2019-03-22 Python Scrapy 入门教程 笔记
2024-08-31 12:04:17
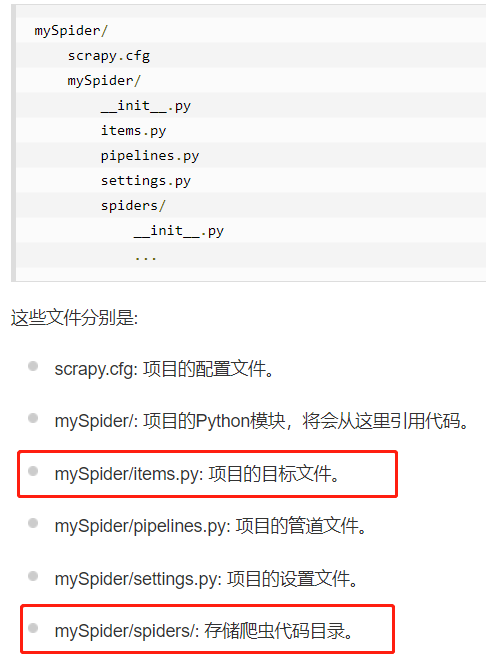
Python Scrapy 入门教程
入门教程笔记:
# 创建mySpider
scrapy startproject mySpider # 创建itcast.py
cd C:\Users\theDataDiggers\mySpider\mySpider\spiders
scrapy genspider itcast "itcast.cn" # itcast(itcast.py name)---ItcastSpider(类名)
#该类有3个强制的属性,和一个解析的方法(属性为name allowed_domains start_urls) # 执行itcast.py
scrapy crawl itcast
scrapy crawl itcast -o teachers.csv #在没有学习scrapy时,我们是先请求数据,然后返回数据的
response=request.get(url)
soup=BeautifulSoup(response.text,'lxml')
soup.select() #学习了Scrapy后,发现
def parse(self,response):
#自带response,你可以进行以下操作
response.body()
response.xpath() #顺便还复习了一下类的继承
class ItcastSpider(scrapy.Spider):
class ItcastItem(scrapy.Item):
class MyspiderPipeline(object): #还有引用其它Python文件的类
from mySpider.items import ItcastItem
学习目标
- 创建一个Scrapy项目
- 定义提取的结构化数据(Item)
- 编写爬取网站的 Spider 并提取出结构化数据(Item)
- 编写 Item Pipelines 来存储提取到的Item(即结构化数据)
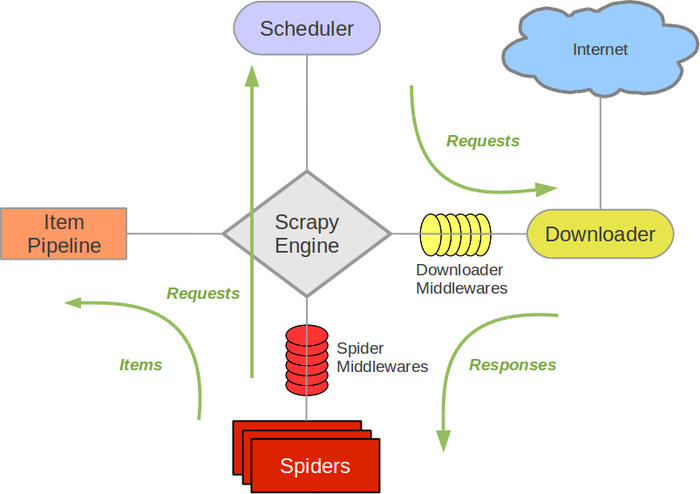
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器).
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
最新文章
- Html:form表单
- 多列布局——column-width
- Easyui-datagrid groupview分组后勾选问题
- 【CC评网】2013.第41周 不求排版,简单就好
- Python之Redis操作
- 2109&2535: [Noi2010]Plane 航空管制 - BZOJ
- linux文件权限位SUID,SGID,sticky的设置理解
- async:false同步请求,浏览器假死
- s标签可以if elseif else
- 【2】最简单的Laravel5.1程序分析
- Linux用户基础
- 个人怎么申请微信小程序
- MySQL 多版本并发控制(MVCC)
- 多线程——multiprocess
- [TPYBoard - Micropython之会python就能做硬件 8] 学习使用超声波模块制作避障小车
- VersionControl:git
- java根据年月显示每周
- linux memcached
- python大法好——字典、集合
- C++中内联函数