Selenium选择web元素
获取html片段可以用来做什么?
可以用来分割,也可以分析HTML文档
beautifulsoup用法?
安装beautifulsoup库: pip install beautifulsoup4
因为bs里面缺省的库对html的兼容性不够,还要安装一个库来实现: pip install html5lib
下面附上bs1.html代码截图:
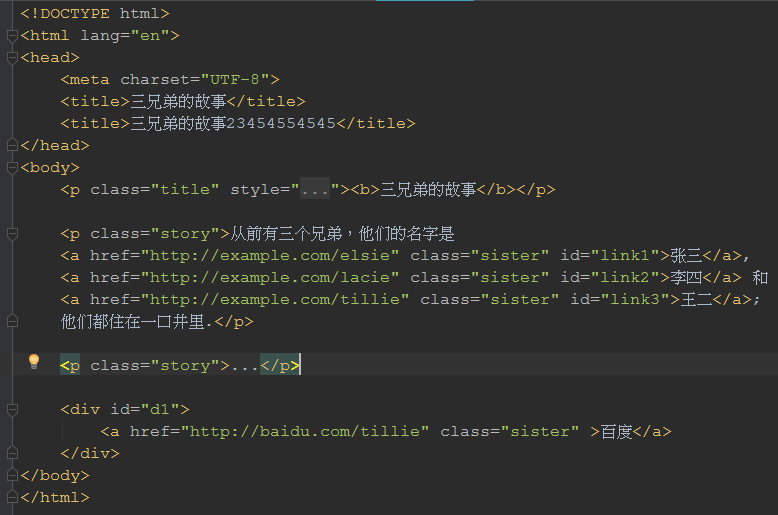
通过代码实现:
# BS操作对象是字符串,假设要对某个html文本作分析,就要先将文本的字符串读出来。
with open('bs.html',encoding='utf8') as f:
html_doc = f.read()
# 导入相关库,html5lib不用导入,BS会自动引用
from bs4 import BeautifulSoup
# 指定用HTML5lib来解析文档
soup = BeautifulSoup(html.doc, 'html5lib') # 第一个参数是要解析的文本,第二个参数指定是用htmllib库来解析的
# print(soup.title) # 打印出第一个title的内容
# print(soup.find('title'))
# print(soup.title.name) # 获取标签名
# 获取tag(标签)文本内容
# print(soup.title.string)
# 也可以:
# print(soup.title.get_text())
# 如果要获取tag的父节点tag
# print(soup.title.parent)
# print(soup.title.parent.name)
# 如果要获取元素的属性值
# print(soup.div['id'])
# print(soup.p['style'])
# print(soup.a) 只找到第一个标签
# print(soup.find_all('a')) 找到所有的a标签
# print(soup.find_all('a')[1]) 找到第二个a标签 根据下标
# print(soup.find('a', id='link1')) 根据id属性来查找相应的a标签
# print(soup.find('a', href='http://example.com/lacie')) # 根据超链接来查找相应的a标签
webdriver提供的八种基本元素定位:
通过id属性选择元素:find_element_by_id()
通过name属性选择元素:find_element_by_name()
通过classs属性选择元素:find_element_by_class_name()
通过tag(标签)属性选择元素:find_element_by_tag_name()
通过link选择元素:find_element_by_link_text()
通过partial_link(模糊匹配的方式)定位:find_element_by_partial_link_text()
通过xpath选择元素:find_element_by_xpath()
通过css选择元素:find_element_by_css_selector()
最新文章
- JAVA通信系列三:Netty入门总结
- Euclid求最大公约数
- 使用pngquant命令近乎无损压缩PNG图片大小减少70%左右
- java中流转化为Object可序列化
- 怎样在excel中添加下拉列表框
- linux包之iproute之ss命令
- DataTable.Select
- OpenJudge/Poj 1191 棋盘分割
- C语言可变参数在宏定义中的应用
- Java的native关键字---JAVA下调用其他语言的关键词
- poj3320 (尺取法)
- android引入百度地图之最简单的例子-HelloBaiDuMap
- 服务器:SATA、PATA及IDE的比较
- 【Linux基础】查看某一端口是否开放(1025为例)
- scipy插值与拟合
- Faster R-CNN:详解目标检测的实现过程
- xcode代码提示没了
- cordova网络情况检测插件使用:cordova-plugin-network-information
- .NET Core微服务之路:文章系列和内容索引汇总 (v0.52)
- Python Web简单加法器的实现--Python