图库网站Unsplash高清原图爬虫【华为云技术分享】
【摘要】 写博客的好工具,快速获得高清图片
在百度图片爬虫小助手里,我开发了一个爬虫,来节约我写博客时搜集图片的时间。
但是,也出现了一些问题,主要有以下几点:
- 百度图片上的质量参差不齐,大部分图片质量不够
- 图片分辨率普遍不够
- 图片存在版权问题,许多图片存在水印或logo
针对上面的几个问题,我找了一个新的图库网站Unsplash来获得图片。
Unsplash上的图片都是免费的,因此不存在水印的问题,而且,针对同一图片,还提供不同尺寸(raw,full,regular,small,thumb),就我发博客这一需求而言,regular级别的图片已经可以满足。
进入Unsplash,打开F12开发者工具抓包,输入关键字boy,试图找到相关的request,得到了这些信息
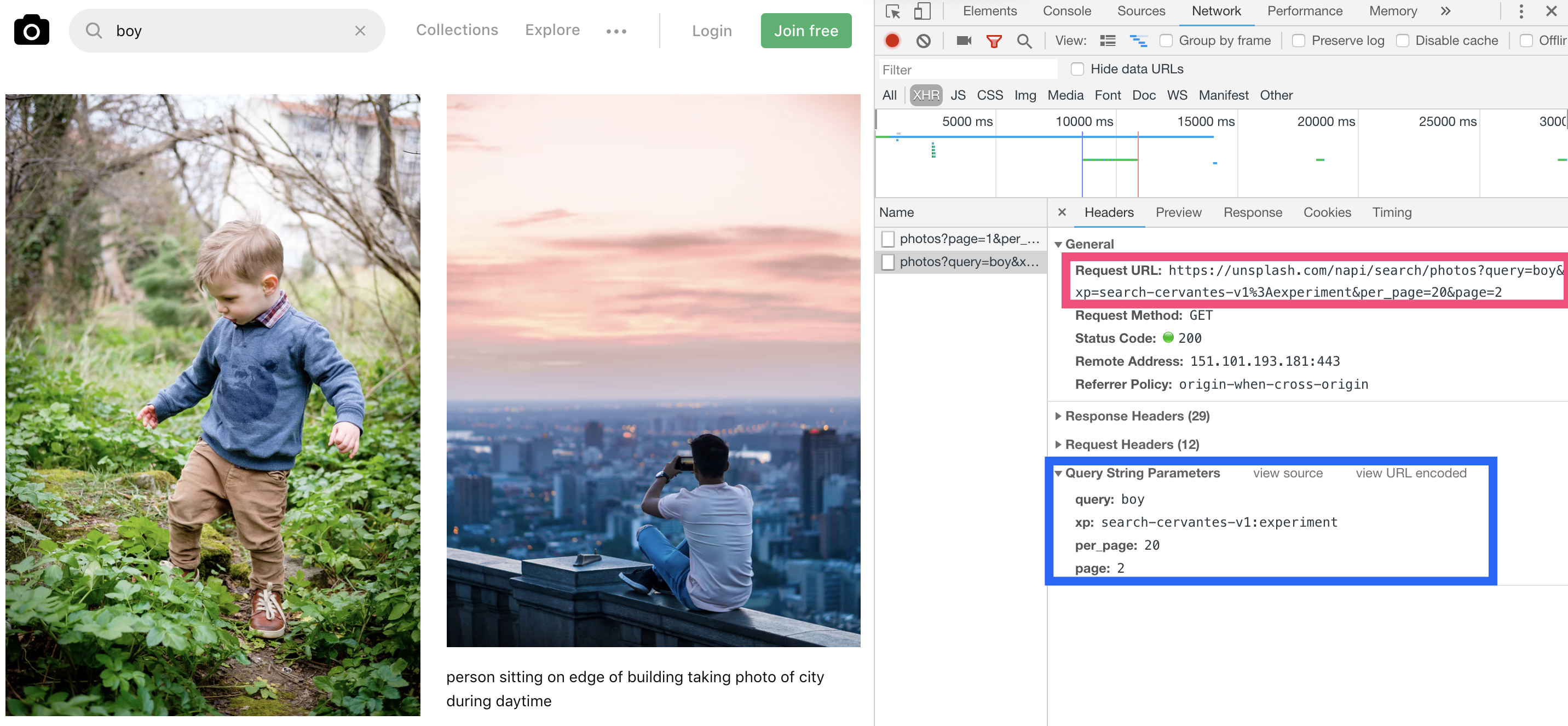
上图红色框是接口地址,蓝色框中是向这个接口发送的入参,我们再看一下这个接口返回的数据。
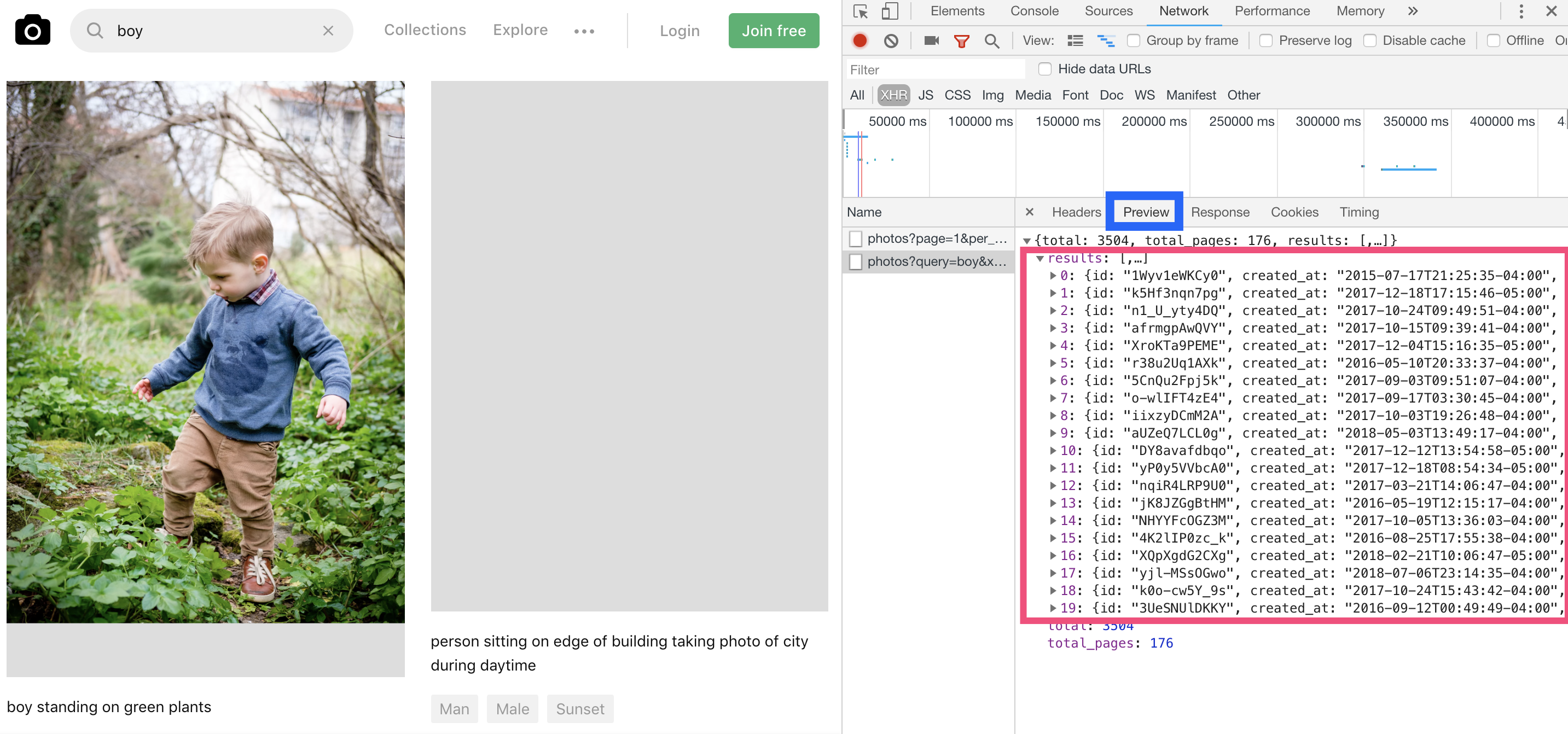
红色框中返回了20条数据,正好对应的向接口发送的入参per_page:20(即每页返回20张图片信息),查看每一张图片的信息,可以看到以下内容。
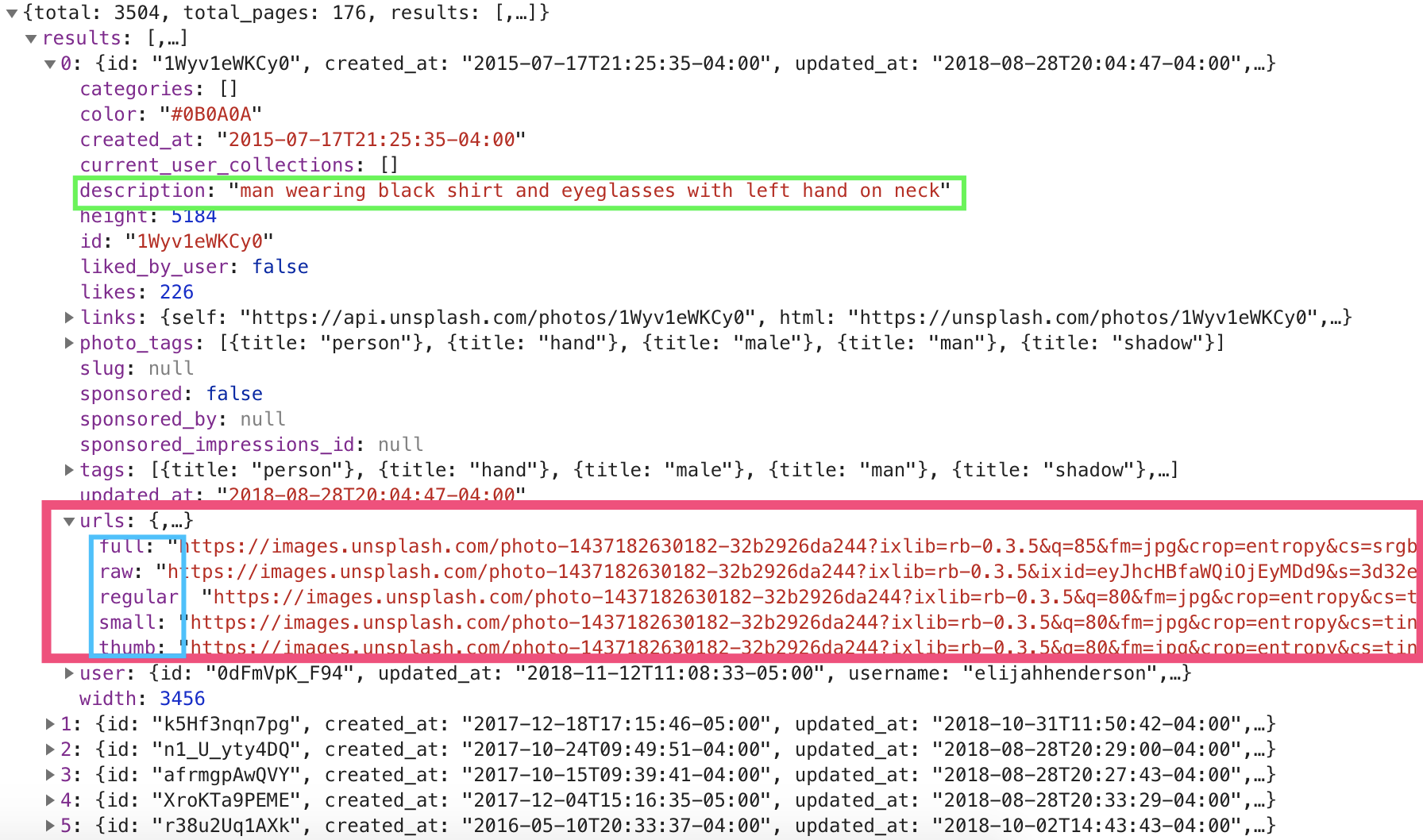
红色框中正是图片的URL地址,绿色框中用了一句话对图片进行大致描述,而蓝色框中可以看出,图片根据不同尺寸分了好几种规格,这应该是方便在不同的设备之间进行显示。
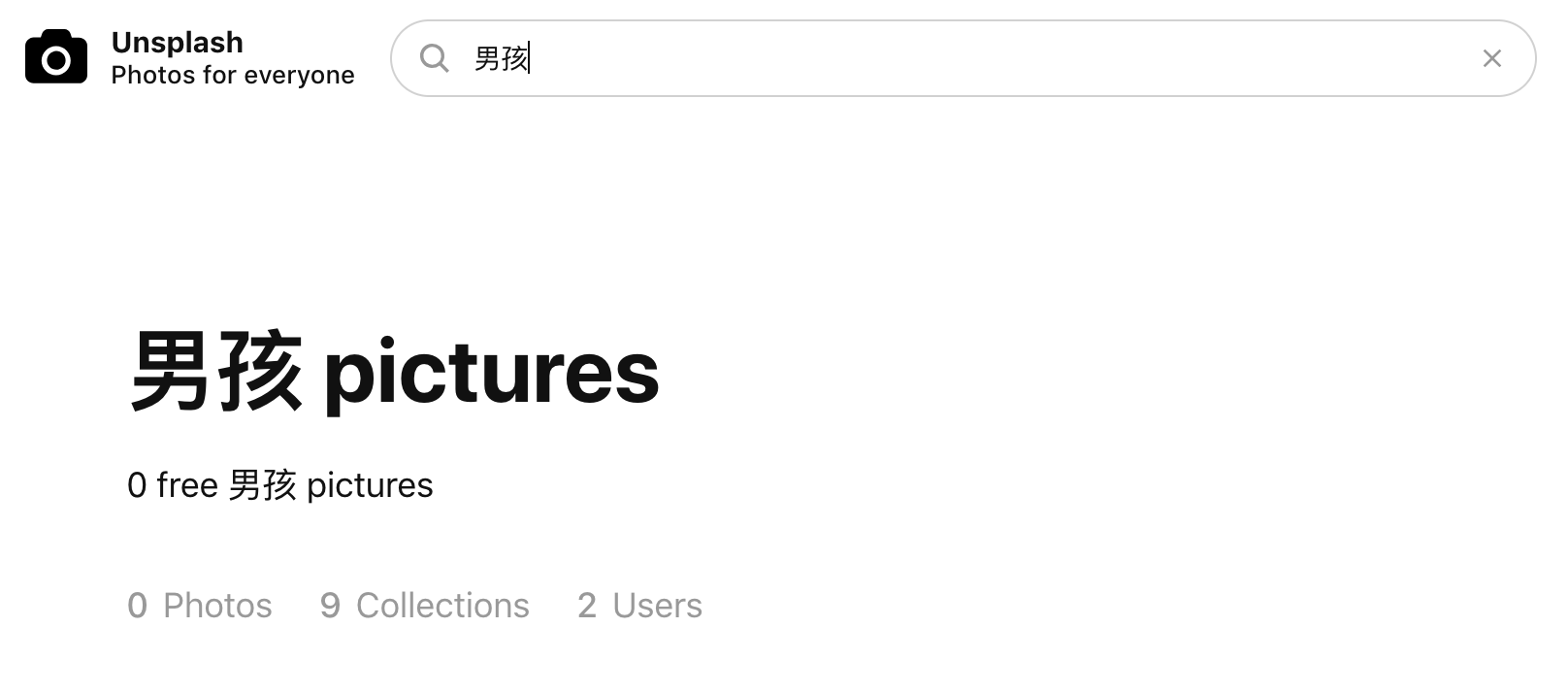
由于Unplash是国外的图库网站,因此并不支持中文查询。但这可难不倒我们,在网上找了个翻译接口将中文翻译成英文,就可以解决这个问题了,我采用的是百度的翻译接口,这里就不展开讲述了。
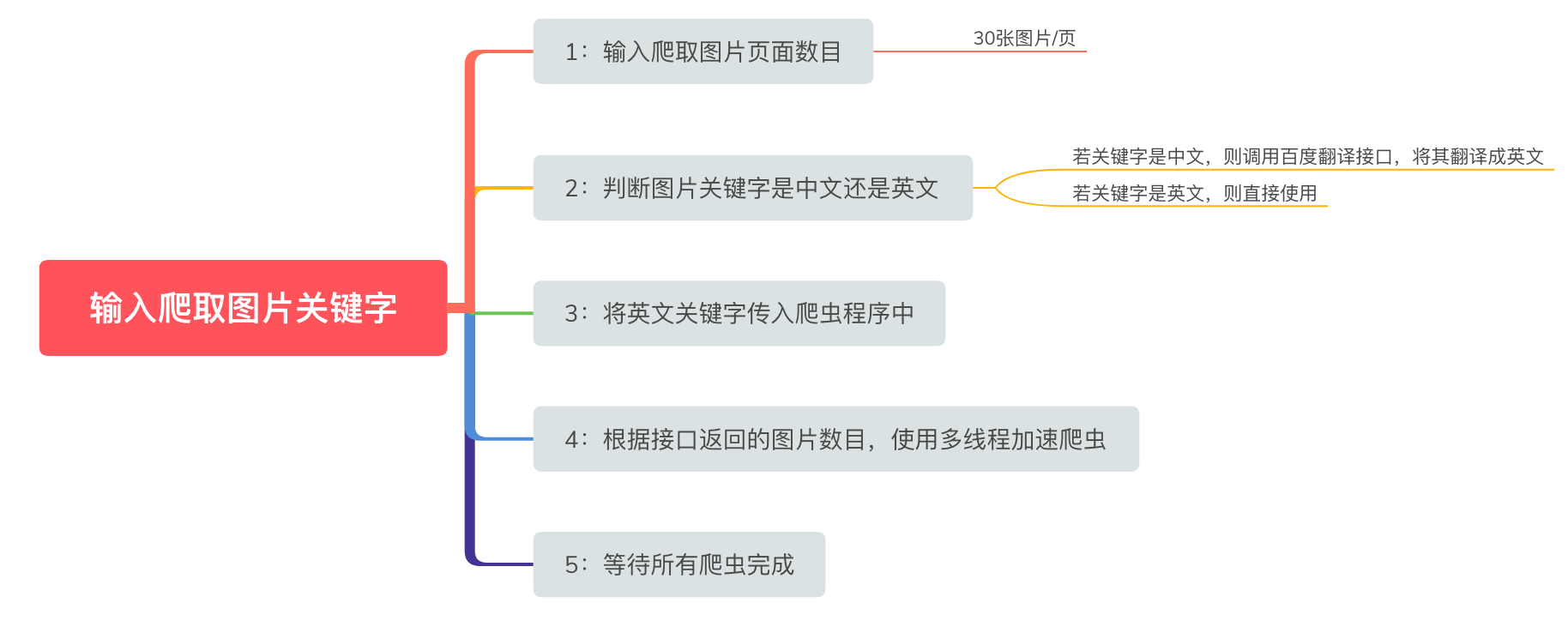
爬虫的流程
我们看一下爬虫的结果吧!
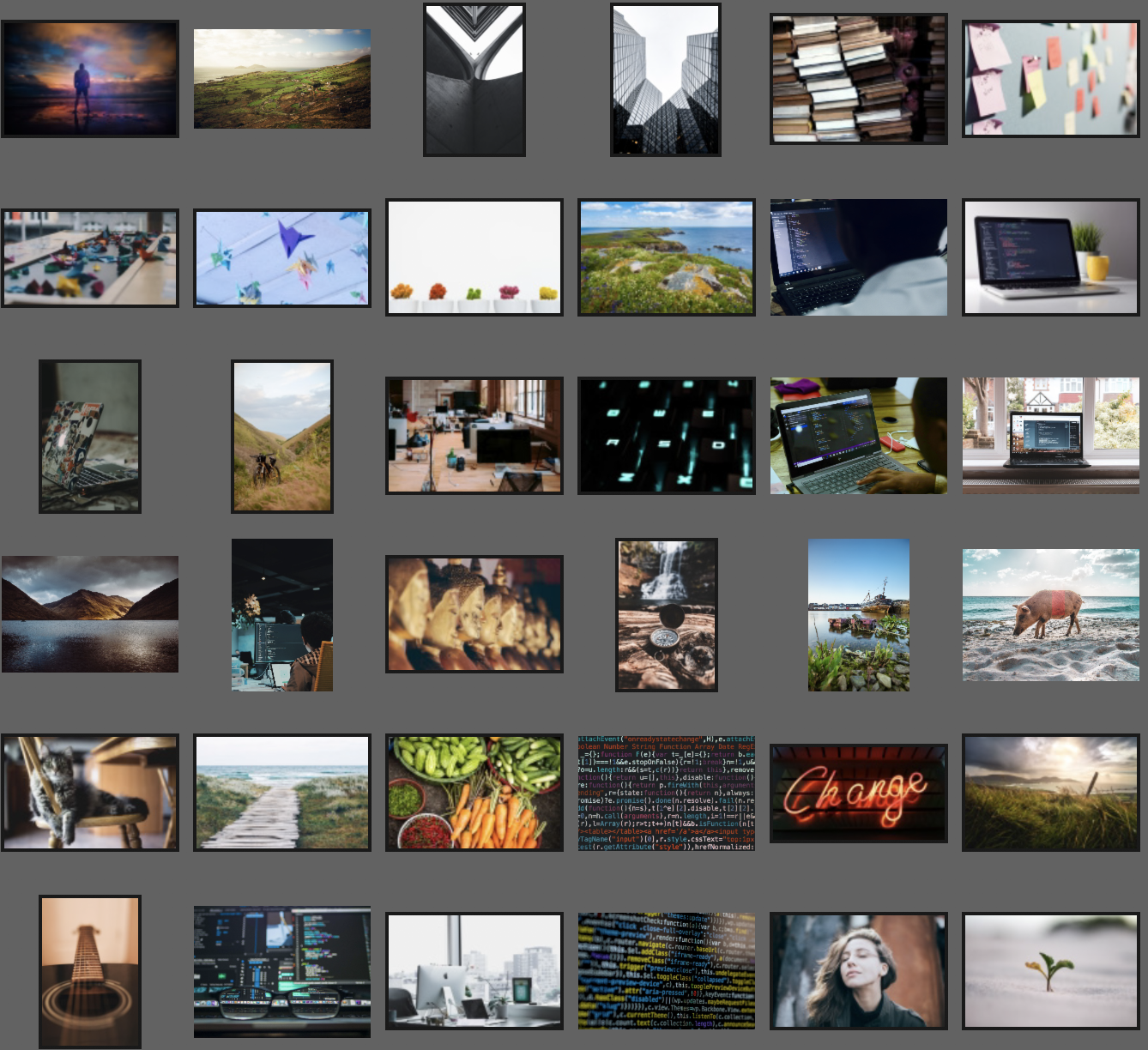
爬虫下载的“programmer”部分图片
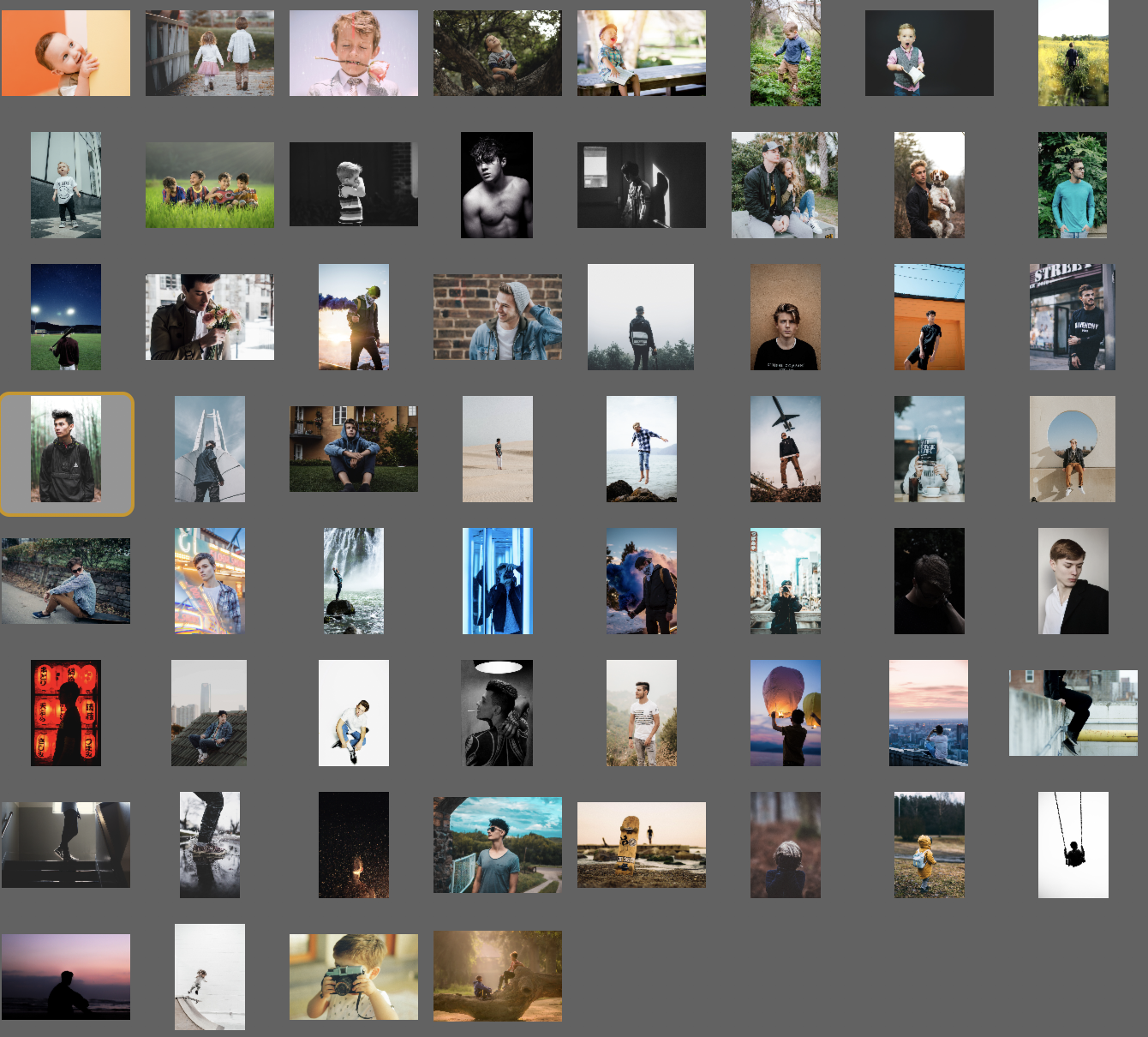
爬虫下载的“boy”部分图片
可以看出,下载的图片质量是非常不错的。为了加速爬虫,并节约硬盘资源,我选择下载reular级别的图片,下面我们看一下这个级别的图片在博客上展示有没有什么问题。


总的来说,Unsplash上的图片质量是比百度图库要好的,但有些特殊的词,Unsplash收录的图片数量就没有百度图库多了,有时间再将Unsplash爬虫与百度爬虫结合起来,希望我的博客在编辑速度以及美观方面能有所提升。
来源:华为云社区 作者:开飞机的大象
最新文章
- 数据结构图文解析之:AVL树详解及C++模板实现
- vsftpd.conf Details
- HTML 标题<h1>-<h6>
- 初学android的第一个习作
- Jsonp 前后端交互操作
- thinkphp 独立分组配置
- SUSAN检测算子
- C#启动进程之Process
- hdu Tempter of the Bone (奇偶剪枝)
- java实现——008旋转数组的最小数字
- java-cef嵌入基于Chrome内核浏览器,做页面爬虫(可以尽在ajax异步请求数据)
- Lucene的使用与重构
- 编译GDAL支持ArcObjects
- 文本分类学习(六) AdaBoost和SVM
- URL 链接中 井号#、问号?、连接符& 分别有什么作用?
- Redis 开发规范
- MVC Post 提交表单 允许他提交参数包含html标记的解决方法
- 【vim】跳转到上/下一个修改的位置
- 译:3.消费一个RESTful Web Service
- play framework - 初识
热门文章
- Golang的json包
- [考试反思]1005csp-s模拟测试60:招魂
- CSPS模拟 47
- P4799 [CEOI2015 Day2]世界冰球锦标赛(折半暴搜)
- Python实现发送邮件代码
- javascript JSMpeg.js 播放视频解决不用全屏也能播放(也支持自动播放哦)
- suseoj 1208: 排列问题 (STL, next_permutation(A.begin(), A.end()))
- nyoj 33-蛇形填数 (循环,模拟)
- 在VMware通过挂载系统光盘搭建本地yum仓库
- 阿里云ECS服务器部署HADOOP集群(二):HBase完全分布式集群搭建(使用外置ZooKeeper)