045 介绍UDF,以及完成大小写的转换
2024-08-19 17:11:18
一:概述
1.UDF
用户自定义函数,用java实现自定义的需求
User Defined Function-----UDF。
2.UDF的类型
udf:一进一出
udaf:多进一出
udtf:一进多出
3.udf的实现步骤
继承UDF类
实现evaluate的方法
所有的方法都必须有返回值
推荐使用Text,LongWritable等类型
二:配置准备
1.导入新的包括hive的jar包
需要新的本地repository库。
然后在eclipse中选择更新。
在windows下新建maven工程。
2.修改pom.xml中的依赖,
主要是增加hive的依赖,当然hadoop依赖必须有。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.cj.it</groupId>
<artifactId>hiveUdf</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging> <name>hiveUdf</name>
<url>http://maven.apache.org</url> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties> <dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>0.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>0.13.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
三:程序完成
1.需求
大小写的转换
0:表示转换为小写
1:表示转换为大写
默认是转换为小写
2.程序讲解
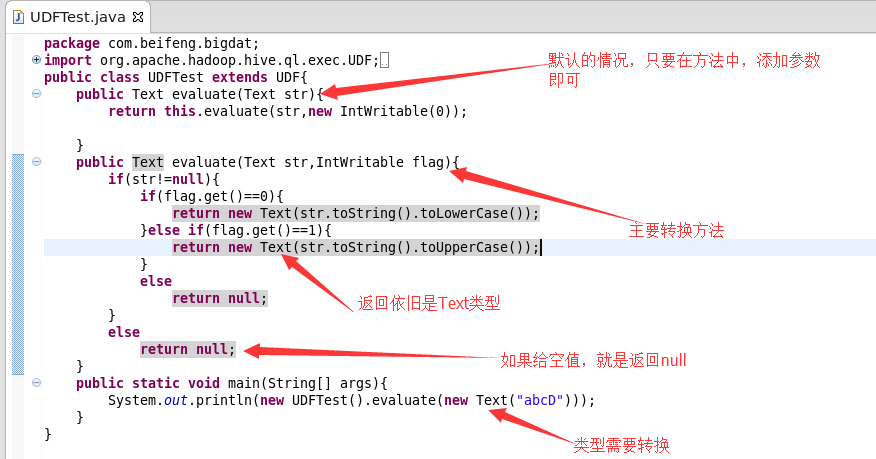
3.源代码
package com.cj.it.hiveUdf; import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text; public class UdfTest extends UDF {
public Text evaluate(Text str) {
return evaluate(str, new IntWritable(0));
} public Text evaluate(Text str, IntWritable flag) {
if (str != null) {
if (flag.get() == 0) {
return new Text(str.toString().toLowerCase());
}
if (flag.get() == 1) {
return new Text(str.toString().toUpperCase());
}
return null;
}
return null;
} public static void main(String[] args) {
System.out.println(new UdfTest().evaluate(new Text("asssf"), new IntWritable(1)));
}
}
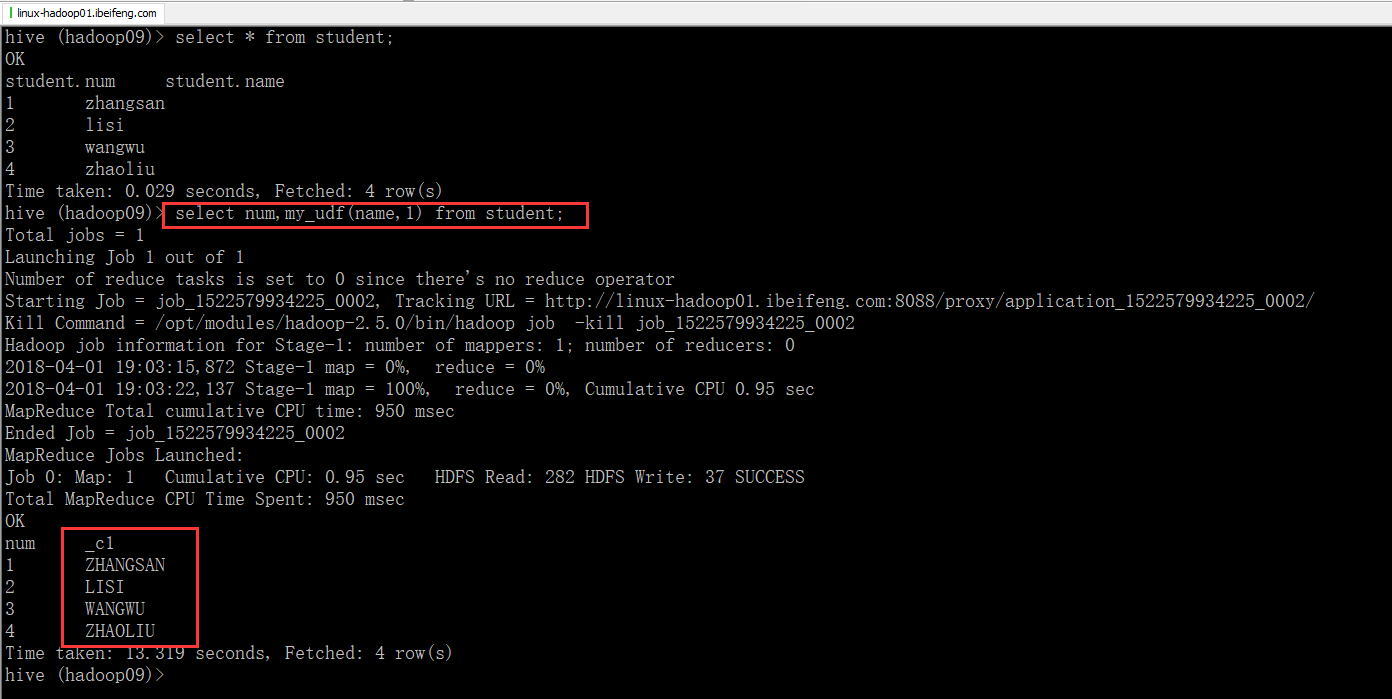
4.运行效果

四:导出
1.Export
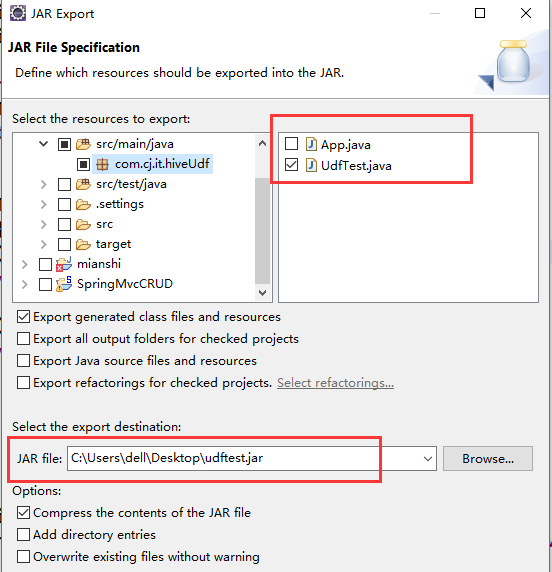
2.jar
五:上传到hive
1.先上传到datas目录下
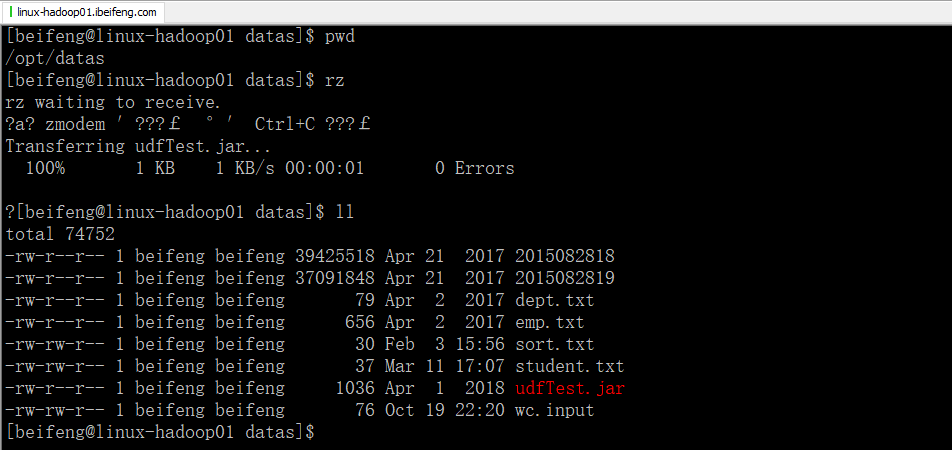
2.启动hadoop
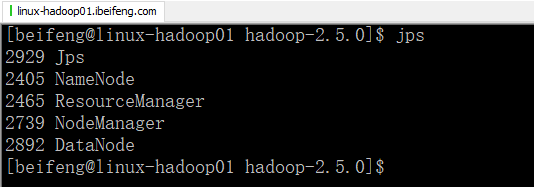
3.启动hive
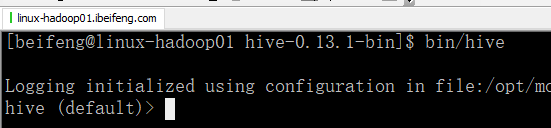
4.关联jarbao
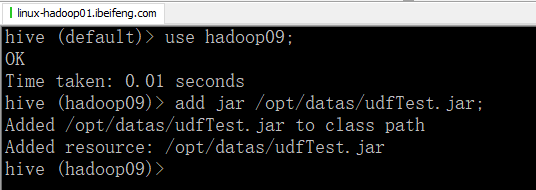
5.创建方法

6.使用
最新文章
- css-父标签中的子标签默认位置
- Ionic发布成android
- SQL SERVER 2000数据库置疑处理
- AngularJS in Action读书笔记2——view和controller的那些事儿
- ArcObject10.1降级至10.0
- Java集合——Set接口
- Sqlite基础及其与SQLServer语法差异
- js基本框架
- Swift、Objective-C 单例模式 (Singleton)
- Perl IO:IO重定向
- Unity3D判断当前所在平台
- elasticsearch -- Logstash实现mysql同步数据到elasticsearch
- windows 7 安装时提示:安装程序无法创建新的系统分区
- linux硬盘挂载-新硬盘挂载和扩容硬盘挂载
- AX_Currency
- 自学Aruba7.2-Aruba安全认证-Portal认证(web页面配置)
- RabbitMQ Dead Lettering(死信)
- usb的一些网址
- Linux下grep命令查找带有tab(退格)的字符
- gitlab修改root密码
热门文章
- NOIP2016 D2-T3 愤怒的小鸟
- python之functools partial
- centOS6.4 extundelete工具恢复rm -rf 删除的目录[转]
- Linq基于两个属性的分组
- canny 算子python实现
- cocos2d-x在App中的应用
- 执行update语句mysql5.6报错ERROR 1292 (22007): Truncated incorrect DOUBLE value: '糖糖的坤大叔'
- 通过Cookie跳过登录验证码【限cookie不失效有用】
- sklearn 岭回归
- sqlserver服务启动后停止,传递给数据库 'master' 中的日志扫描操作的日志扫描号无效