pandas的聚合操作: groupyby与agg
pandas提供基于行和列的聚合操作,groupby可理解为是基于行的,agg则是基于列的
从实现上看,groupby返回的是一个DataFrameGroupBy结构,这个结构必须调用聚合函数(如sum)之后,才会得到结构为Series的数据结果。
而agg是DataFrame的直接方法,返回的也是一个DataFrame。当然,很多功能用sum、mean等等也可以实现。但是agg更加简洁, 而且传给它的函数可以是字符串,也可以自定义,参数是column对应的子DataFrame
一、pandas.group_by
首先来看一下案例的数据格式,使用head函数调用DataFrame的前8条记录,这里一共4个属性
column_map.head(8)
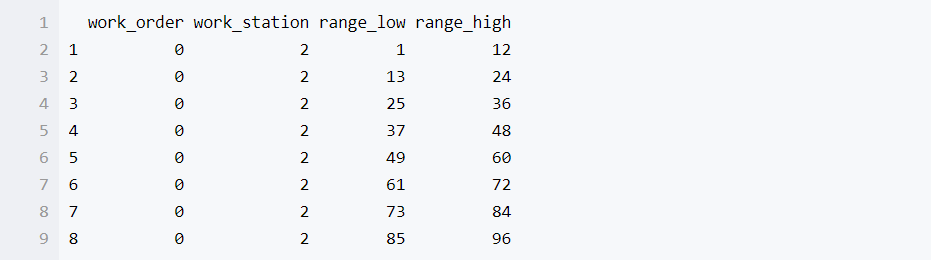
work_order 表示工序, work_station表示工位,rang_low, range_high 表示对应记录的上下限,现在使用groupby统计每个工序工位下面各有多少条记录
column_map.groupby(['work_order','work_station'])我们会发现输出的是一个GroupBy类,并非我们想要的结果
<pandas.core.groupby.DataFrameGroupBy object at 0x111242630>还需要加上一个聚合函数,比如
wo_ws_group = column_map.groupby(['work_order','work_station'])
wo_ws_group.size()我们就可以得到

新出现的列对应着每个工序工位下面有多少条记录
但是我们可以发现它的格式已经和我们平时使用的DataFrame不太一样了,我们可以使用下面的命令解决
wo_ws_group.size().reset_index()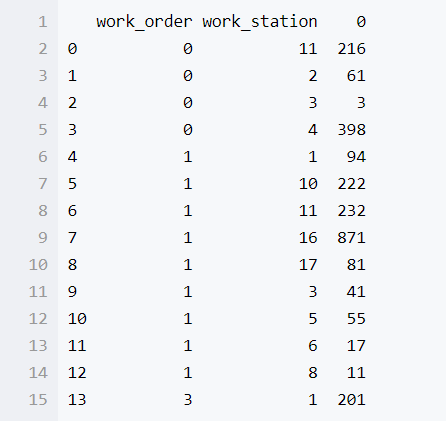
想要查询具体每一个记录,可以使用loc命令


使用get_group可以查询具体每一个分组下面的所有记录
wo_ws_group.get_group(('0','11'))
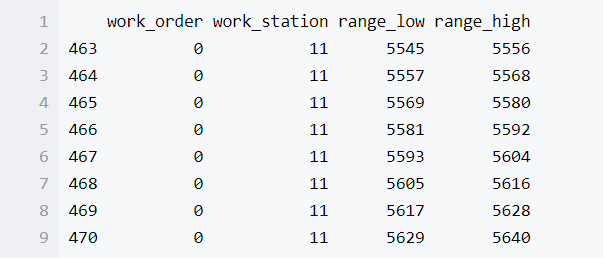
因为比较多就显示全部了,使用head,显示前几条记录
wo_ws_group.get_group(('0','11')).head(8)
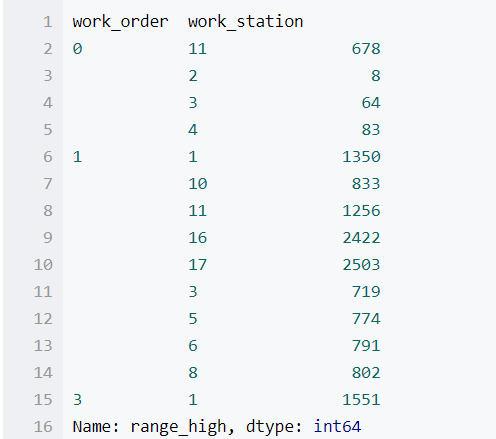
我们还可以使用idxmin(),idxmax()函数,获得每一个分组下面所有记录中数值最大最小的index
wo_ws_group['range_low'].idxmin()


对于分组结果的每一列还可以使用apply,进行一些函数的二次处理,如
wo_ws_group['work_order'].apply(lambda x:2*x).head(8)
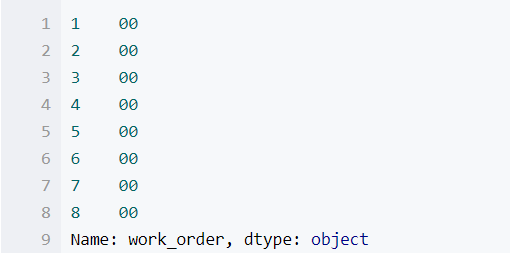
由于这里的0是字符串类型,所以2*以后都变成了2个0
二、pandas.agg
agg的使用比groupby还要简介一些,我们现自己创建一个DataFrame作为例子
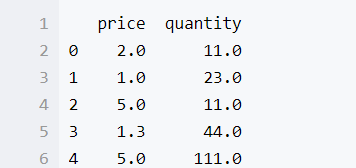
data = pd.DataFrame([[2,11],[1,23],[5,11],[1.3,44],[5,111]],columns = ['price','quantity'],dtype = float)
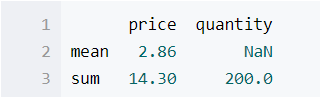
使用agg统计每一列的求和与平均值
data.agg({'price':['sum','mean'],'quantity':['sum']})
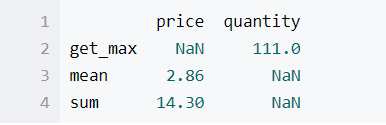
如果需要自定义一些函数的 话可以使用lambda函数

最新文章
- django之DB操作
- (淘宝无限适配)手机端rem布局详解(转载非原创)
- ZOJ Problem Set - 3640 Help Me Escape
- ZOJ 3367 Counterfeit Money(最大相同子矩阵)
- ODB 下载与安装 (Linux)
- Ajax—初识
- 《剑指offer》面试题的Python实现
- 检验金额合法性, 只能是正数 或小数(常用js总结)
- WP Super Cache+七牛云配置CDN加速,让你的网站秒开
- javaEE学习路线与目标
- RabbitQM(消息duilie)
- 小甲鱼零基础python课后题 P21 020函数:内嵌函数和闭包函数
- Java NIO的工作方式
- Ouroboros Snake POJ - 1392(数位哈密顿回路)
- nginx 全局配置
- 一个简单的web.py论坛
- BootStrapTable 文档
- 团队作业4 Alpha冲刺
- IE6、IE7、Firefox中margin问题及input解决办法
- centos7.6 安装 openvpn--2.4.7