Java ThreadPoolExecutor详解
ThreadPoolExecutor是Java语言对于线程池的实现。池化技术是一种复用资源,减少开销的技术。线程是操作系统的资源,线程的创建与调度由操作系统负责,线程的创建与调度都要耗费大量的资源,其中线程创建需要占用一定的内存,而线程的调度需要不断的切换线程上下文造成一定的开销。同时线程执行完毕之后就会被操作系统回收,这样在高并发情况下就会造成系统频繁创建线程。
为此线程池技术为了解决上述问题,使线程在使用完毕后不回收而是重复利用。如果线程能够复用,那么我们就可以使用固定数量的线程来解决并发问题,这样一来不仅节约了系统资源,而且也会减少线程上下文切换的开销。
参数
ThreadPoolExecutor的构造函数有7个,它们分别是:
- corePoolSize(int):线程池的核心线程数量
- maximumPoolSize(int):线程池最大线程数量
- keepAliveTime(long):保持线程存活的时间
- unit(TimeUnit):线程存活时间单位
- workQueue(BlockingQueue):工作队列,用于临时存放提交的任务
- threadFactory(ThreadFactory):线程工厂,用于创建线程
- handler(RejectedExecutionHandler):任务拒绝处理器,当线程池无法再接受新的任务时,会交给它处理
一般情况下,我们只使用前五个参数,剩余两个我们使用默认参数即可。
任务提交逻辑
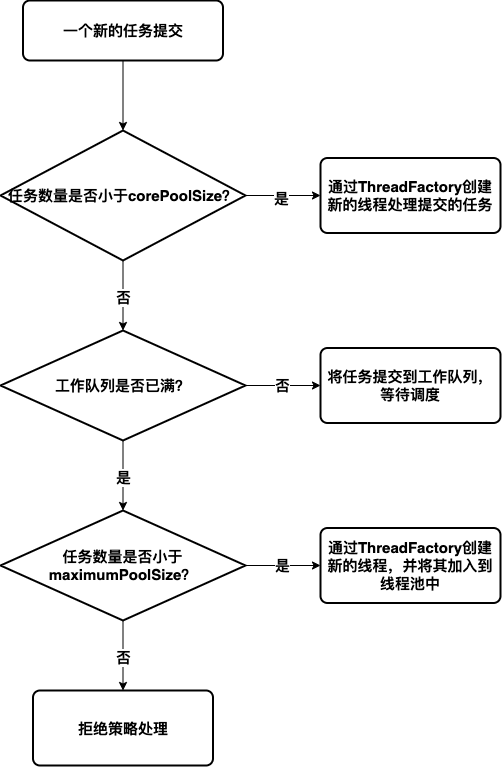
其实,线程池创建参数都与线程池的任务提交逻辑密切相关。根据源码描述可以得知:当提交一个新任务时(执行线程池的execute方法)会经过三个步骤的处理。
- 当任务数量小于
corePoolSize时,线程池会创建一个新的线程(创建新线程由传入参数threadFactory完成)来处理任务,哪怕线程池中有空闲线程,依然会选择创建新线程来处理。 - 当任务数量大于
corePoolSize时,线程池会将新任务压入工作队列(参数中传递的workQueue)等待调度。 - 当新提交的任务无法压入工作队列时,会检查当前任务数量是否大于
maximumPoolSize。如果小于maximunPoolSize则会新建线程来处理任务(这时我们的keepAliveTime参数就起作用了,它主要作用于这种情况下创建的线程,如果任务数量减小,这些线程闲置了,那么在超过keepAliveTime时间后就会被回收)。如果大于了maximumPoolSize就会交由任务拒绝处理器handler处理。
线程池状态
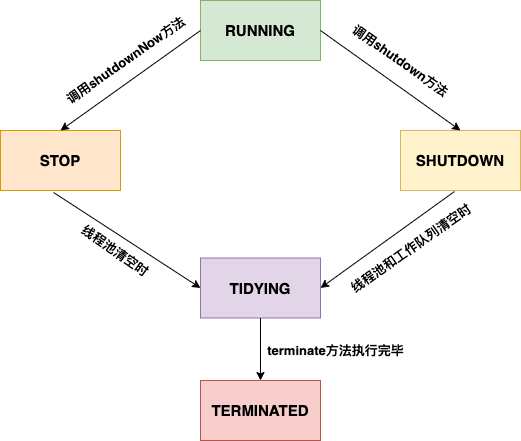
正如线程有不同的状态一样,线程池也拥有不同的运行状态。源码中提出,线程池有五种状态,分别为:
- RUNNING:运行状态,不断接收任务并处理它们。
- SHUTDOWN:关闭状态,不接收新任务,但是会处理工作队列中排队的任务。
- STOP:停止状态,不接收新任务,清空工作队列且不会处理工作队列的任务。
- TIDYING:待终止状态,此状态下,任务队列和线程池都为空。
- TERMINATED:终止状态,线程池关闭。
如何让线程不被销毁
文章开头说到,线程在执行完毕之后会被操作系统回收销毁,那么线程池时如何保障线程不被销毁?首先看一个测试用例:
public static void testThreadState()
{
Thread thread = new Thread(() -> System.out.println("Hello world")); // 创建一个线程
System.out.println(thread.getState()); // 此时线程的状态为NEW
thread.start(); // 启动线程,状态为RUNNING
System.out.println(thread.getState());
try
{
thread.join();
System.out.println(thread.getState()); // 线程运行结束,状态为TERMINATED
thread.start(); // 此时再启动线程会发生什么呢?
} catch (InterruptedException e)
{
e.printStackTrace();
}
}
结果输出:
NEW
RUNNABLE
Hello world
TERMINATED
Exception in thread "main" java.lang.IllegalThreadStateException
at java.base/java.lang.Thread.start(Thread.java:794)
at misc.ThreadPoolExecutorTest.testThreadState(ThreadPoolExecutorTest.java:90)
at misc.ThreadPoolExecutorTest.main(ThreadPoolExecutorTest.java:114)
可以看出,当一个线程运行结束之后,我们是不可能让线程起死回生重新启动的。既然如此ThreadPoolExecutor如何保障线程执行完一个任务不被销毁而继续执行下一个任务呢?
其实这里就要讲到我们最开始传入的参数workQueue,它的接口类型为BlockingQueue<T>,直译过来就是阻塞队列。这中队列有个特点,就是当队列为空而尝试出队操作时会阻塞。
基于阻塞队列的如上特点,ThreadPoolExecutor采用不断循环+阻塞队列的方式来实现线程不被销毁。
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
// 从工作队列中不断取任务。如果工作队列为空,那么程序会阻塞在这里
while (task != null || (task = getTask()) != null) {
w.lock();
// 检查线程池状态
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
try {
//// 执行任务 ////
task.run();
afterExecute(task, null);
} catch (Throwable ex) {
afterExecute(task, ex);
throw ex;
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
关闭线程池
想要关闭线程池可以通过调用shutdown()和shutdownNow()方法实现。两种方法有所不同,其中调用shutdown()方法会停止接收新的任务,处理工作队列中的任务,调用这个方法之后线程池会进入SHUTDOWN状态,此方法无返回值并且不抛出异常。
而shutdownNow()方法会停止接收新的任务,而且会返回未完成的任务集合,同时这个方法也会抛出异常。
如何创建一个适应业务背景的线程池
线程池创建有七个参数,这几个参数的相互作用可以创建出适应特定业务场景的线程池。其中最为重要的有三个参数分别为:corePoolSize,maximumPoolSize,workQueue。其中前两个参数已经在上文中作了详细介绍,而workQueue参数在线程池创建中也极为重要。workQueue主要有三种:
- SynchronousQueue:这个队列只能容纳一个元素,而且只有当队列为空时可以入队。
- ArrayBlockingQueue:这是一个固定容量大小的队列。
- LinkedBlockingQueue:链式阻塞队列,容量无限。
通过上述三种队列的特性我们可以得知,
- 当使用SynchronousQueue的时候,总是倾向于新建线程处理请求,如果线程池大小参数设置的很大,那么线程数量倾向于无限增长。这样的线程池能够高效处理突发增长的请求,而且处理效率很高,但是开销很大。
- 当使用ArrayBlockingQueue的时候,线程池所能处理的瞬时最大任务量为队列大小 + 线程池最大数量,这样的线程池中规中矩,使用的业务场景很多,具体还需结合业务场景来调配三个参数的大小。例如I/O密集型的场景,多数的线程处于阻塞状态,为了提高系统吞吐量,我们希望能够有多数线程来处理IO。这样的话我们偏向于将corePoolSize设置的大一点。而且阻塞队列大小不要设置很大,同时maximumPoolSize也设置的大一点。
- 当使用LinkedBlockingQueue时,线程池的maximumPoolSize参数会失效,因为按照任务提交流程来看,LinkedBlockingQueue可以无限制地容纳任务,自然不会出现队列无法工作,新建线程处理的情况。使用LinkedBlockingQueue可以处理平稳的处理一些请求激增的情况,但是处理效率不会提高,仅仅能够起到一定的缓冲作用。
最新文章
- VS2010--canot determine the locationof the vs common tools folder
- VS条件断点的一个坑
- javascript设计模式-抽象工厂模式
- JSP之错误信息提示
- C# type - IsPrimitive
- WIN7建立网络映射磁盘
- C# - 系统类 - 系统接口
- dubbo源码分析一:整体分析
- 谢绝艳照门 - 手把手教你把当今很hit的家庭监控IP Camera变得网络安全起来
- Python查询MySQL进行远程采集图片实例
- PAT1005
- SpringMVC轻松学习-环境搭建(二)
- LPC1768的IIS通讯
- react和vue的不同
- 转)Ubuntu安装teamviewer
- [UI] 04 - Bootstrap: layout & navigation
- day31-python阶段性复习五
- Restful api 防止重复提交
- Bzoj2149拆迁队:cdq分治 凸包
- [Node.js] Availability and Zero-downtime Restarts
热门文章
- ubuntu下scala下载+集成IDEA开发环境
- Java 复习整理day04
- python工业互联网应用实战5—Django Admin 编辑界面和操作
- Windows下使用poetry和pyproject.toml
- Java创建线程四种方式
- AtCoder Beginner Contest 164
- 牛客练习赛70 A.重新排列 (,字符串思维)
- javascript——function类型(this关键字)
- Educational Codeforces Round 89 (Rated for Div. 2) D. Two Divisors (数学)
- Prometheus监控k8s企业级应用