吴裕雄--天生自然python学习笔记:网页解析
2024-10-08 20:37:27
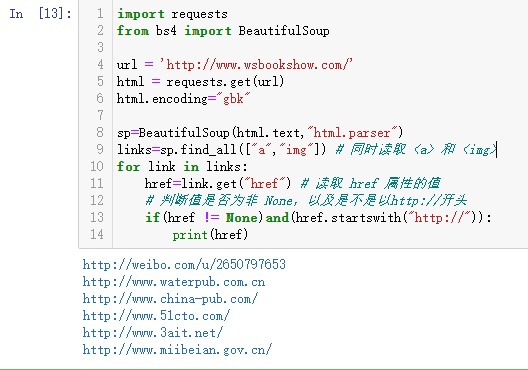
抓取万水书苑网页中所有<a>标签中的超链接井显示。
import requests
from bs4 import BeautifulSoup url = 'http://www.wsbookshow.com/'
html = requests.get(url)
html.encoding="gbk" sp=BeautifulSoup(html.text,"html.parser")
links=sp.find_all(["a","img"]) # 同时读取 <a> 和 <img>
for link in links:
href=link.get("href") # 读取 href 属性的值
# 判断值是否为非 None,以及是不是以http://开头
if(href != None)and(href.startswith("http://")):
print(href)
最新文章
- blktrace
- apache2.4以上版本配置虚拟主机
- Postgresql存储过程调试:PostgreSQL 之 Function NOTICE
- Chrome插件概览(一) – The basics
- css 妙味 总结
- ArcGIS Server,4000端口被占用
- 彻底弄懂css中单位px和em,rem的区别 转的自己看
- volatile synschonized的区别
- Install GDAL in OpenSUSE 12.3 Linux
- 关于Session
- 获取bing图片并自动设置为电脑桌面背景(C++完整开源程序)
- Android下资源使用的方式-android学习之旅(五十三)
- Can peel peel solve pesticide problem
- Flask框架里的cookie和session
- linux添加zabbix service并开机自动启动
- android iOS 编码问题害死人!
- [linux] ssh远程执行本地脚本
- 微信小程序使用函数的三种方法
- pku 2284 That Nice Euler Circuit
- centos下搭建高可用redis
热门文章
- Json返回结果为null属性不显示解决
- AttributeError: module 'selenium.webdriver.common.service' has no attribute 'Service'
- 干货 | 京东云应用负载均衡(ALB)多功能实操
- 01 语言基础+高级:1-8 File类与IO流_day10【缓冲流、转换流、序列化流】
- deque & list
- 【hdu6613】Squrirrel 树形DP
- Bless All
- [AC自动机]玄武密码
- Python笔记_第三篇_面向对象_3.重载(overloading)和重写(overriding)
- Hard Disk Driver(GPT)