spark数据清洗
2024-10-21 03:50:23
spark数据清洗
1.Scala常用语法
运用maven创建项目,需要导入如下依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
main方法:
def main(args:Array[String]):Unit={ }
变量
var i:Int=1 //在类中自带get和set功能
val a:Int=2 //常量,在类中只有get功能
var arr:Array[String]=Array("abc","bcd","cde")
类型转换
var num:Int=20
var str:String=num.toString
var num2:Int=str.toInt
条件判断
var score:Int=88
if(score==100){
println("优秀")
}else if (score>=90){
println("良好")
}else{
println("继续加油")
}
循环:
//遍历arr
var arr=Array("java","python","scala")
//方式1
for(a<-arr){
println(a)
}
//方式2
arr.foreach(println) //循环1到1(包括1和10)
for(a<-1 to 10){
println(a)
}
元组
//声明赋值:
var t=(4.13,"hello",44)
//取值:
println(t._1) //4.13
println(t._2) //hello
函数:
def test(x:Int,y:Int):Int={
x+y //返回值时不需要加return
}
RDD的创建
//使用集合、数组创建RDD
val arr = Array(1,2,3,4,5)
val rdd = sc.parallelize(arr) 或者 val rdd = sc.makeRDD(arr)
rdd.collect() 转为数组
//通过外部存储创建RDD
//Hdfs上:
sc.textFile(“hdfs://master:9000/wordcount.txt”)
//本地测试
sc.textFile(“data/xxx.csv”)
//通过其他RDD得到新的RDD
val rdd = sc.parallielize(Array(1,2,3,4,5))
arl rdd2 = rdd.map(_*2)
2.常用方法
计数器:
//定义累加器:
val longAccum=sc.longAccumulator("count")
//累加器增加:
longAccum.add(1)//每次增加1
//获取累加器数据
print("累加器结果是:"+longAccum.value)
去重:distinct()
文本行数:count()
package com.xyz import org.apache.spark.{SparkConf, SparkContext} /**
* @author 小勇子start
* @create 2021-10-12 14:03
*/
object DistinctDemo {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("test1")
val sc=new SparkContext(sparkConf)
val rdd=sc.textFile("data/distinct.txt")
val count1:Long=rdd.count();
val rdd2=rdd.distinct()
val count2:Long=rdd2.count()
println("清除的数据条数有:"+(count1-count2)) //
rdd2.saveAsTextFile("data/out1")
sc.stop()
}
}
过滤:filter :false删除,true保留
package com.xyz import org.apache.spark.{SparkConf, SparkContext} /**
* @author 小勇子start
* @create 2021-10-12 14:03
*/
object FilterDemo {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("test1")
val sc = new SparkContext(sparkConf)
val longAccum=sc.longAccumulator("count")
val rdd = sc.textFile("data/test.txt")
val rdd2 = rdd.filter(!_.startsWith("id")) //过滤表头
//val rdd2=rdd.filter(!_.endsWith("e")) //过滤以“e”结尾的数据
val rdd3 = rdd2.filter(x => {//过滤分数小于50的科目
val str = x.split(",")
val score = str(2).toInt
if (score > 50)
true
else{
longAccum.add(1)
false
} })
rdd3.saveAsTextFile("data/out3")
print("分数小于50的数据条数是:"+longAccum.value)
sc.stop()
}
}
map() :适合用来格式化输出格式
package com.xyz import org.apache.spark.{SparkConf, SparkContext} /**
* @author 小勇子start
* @create 2021-10-12 14:03
*/
object MapDemo {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("test1")
val sc = new SparkContext(sparkConf)
val rdd = sc.textFile("data/test.txt")
val rdd2 = rdd.filter(!_.startsWith("id")) //过滤表头
val rdd3=rdd2.map(x=>{
val str=x.split(",")
val name=str(3)
val score=str(2)
val kc=str(1)
val newStr=name+","+score+","+kc
newStr
})
rdd3.saveAsTextFile("data/out4")
sc.stop()
}
}
排序:sortBy() ,填两个值,前一个填根据排序的字段,后一个填升降序,默认升序
package com.xyz import org.apache.spark.{SparkConf, SparkContext} /**
* @author 小勇子start
* @create 2021-10-12 14:03
*/
object sortByDemo {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("test1")
val sc = new SparkContext(sparkConf)
val rdd = sc.textFile("data/test.txt")
val rdd2 = rdd.filter(!_.startsWith("id"))
val rdd3=rdd2.map(x=>{
val str=x.split(",")
val name=str(3)
val score=str(2)
val kc=str(1)
val newStr=name+","+score+","+kc
newStr
}).sortBy(x=>x.split(",")(1),ascending = false)//降序,默认为true
rdd3.saveAsTextFile("data/out5")
sc.stop()
}
}
3.单词计数案例
package com.xyz
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 小勇子start
* @create 2021-10-12 21:22
*/
object WordCount {
def main(args: Array[String]): Unit = {
val sparkConf=new SparkConf().setMaster("local").setAppName("test")
val sc=new SparkContext(sparkConf)
val rdd=sc.textFile("data/test2.txt")
val rdd2=rdd.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_)
//flatMap能把数据一次性读取出来,并按"," 分成若干个数据
//reduceByKey(_+_)表示每一个相同的key的value相加 _:代表key,1 :是value
//格式必须是:(k,v)才能使用该方法
rdd2.saveAsTextFile("data/out1")
}
}
4.求科目平均值案例
package com.xyz
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 小勇子start
* @create 2021-10-13 17:16
*/
object GroupByKeyDemo {
def main(args: Array[String]): Unit = {
val sparkConf=new SparkConf().setMaster("local").setAppName("test2")
val sc= new SparkContext(sparkConf)
val rdd=sc.textFile("data/test.txt")
val rdd2=rdd.map(x=>{
val str=x.split(",")
val km=str(1)
val score=str(2).toFloat
(km,score)
}).groupByKey().map(x=>{
val km=x._1
var allScore:Float=0;
for(i<-x._2){
allScore+=i
}
km+"的平均分为:"+allScore/x._2.size
})
rdd2.saveAsTextFile("data/out2")
}
}
//groupByKey 根据(k,v)中的k分组,将所有k相同的v都放入同一个iterate中保存起来,返回一个(k,iterate(v1,v2,v3))
5.join案例
package com.xyz
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 小勇子start
* @create 2021-10-13 18:41
*/
object JoinDemo{
def main(args: Array[String]): Unit = {
val sparkConf=new SparkConf().setMaster("local").setAppName("test4")
val sc= new SparkContext(sparkConf)
val rdd1=sc.textFile("data/test.txt")
val rdd2=sc.textFile("data/test_2.txt")
val rdd1_2=rdd1.map(x=>{
val str=x.split(",")
val id=str(5).toInt
(id,x)
})
val rdd2_2=rdd2.map(x=>{
val str=x.split(",")
val id=str(0).toInt
(id,x)
})
rdd2_2.join(rdd1_2).map(x=>{
val str=x._2._2.replace(","+x._1,"")
x._2._1+","+str
}).saveAsTextFile("data/out4")
}
}
6.spark项目打jar包
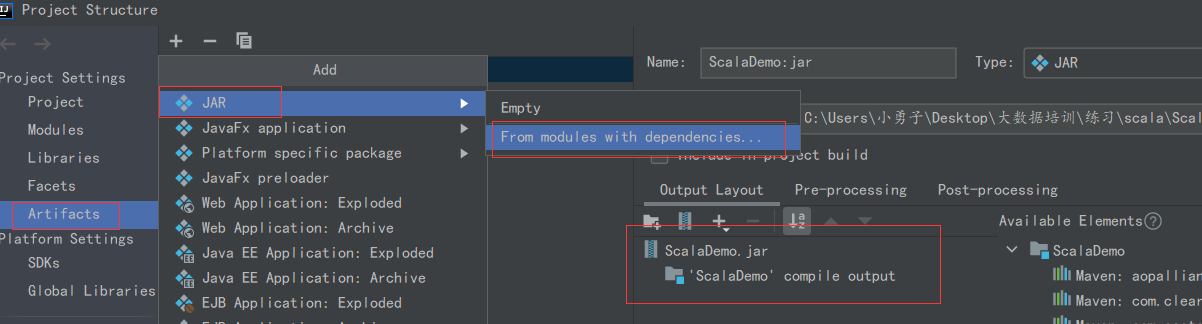
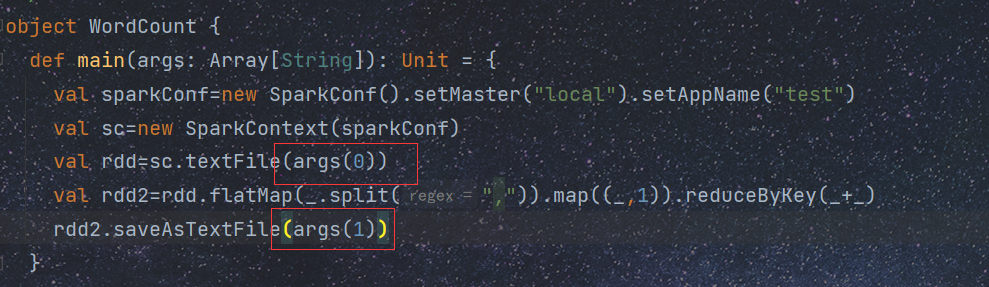
7.运行jar包
以单词计数为例
[root@master bin]# pwd
/usr/local/src/spark/bin
[root@master bin]#spark-submit --master spark:master:7707 --class com.xyz.WordCount /opt/test/ScalaDemo.jar hdfs://master:9000/test/test2.txt hdfs://master:9000/test/out1
--master 后面可以填 local 、spark等等
--class 后面填要运行的主类
/opt/test/ScalaDemo.jar 表示jar包位置
hdfs://master:9000/test/test2.txt 文件输入位置 不能写成 http://master:50070
hdfs://master:9000/test/out1 文件存储位置
输入输出位置与下面对应
最新文章
- iOS开发 关于SEL的简单总结
- python-基础案例
- 学习资料 数据查询语言DQL
- “我爱淘”冲刺阶段Scrum站立会议8
- 略懂 MySQL字符集
- jquery 改变变量出现值不同步
- C++ Primer 5 CH1 开始
- 最长回文 hdu3068(神代码)
- Python复习笔记(一)高级变量类型
- java接口定义和作用
- DFS--障碍在指定时间会消失
- 最新OFFICE 0day漏洞分析
- Nodejs统计每秒记录日志数
- (转)win7英文目录和中文目录,文件夹的别名
- VUE -- ejs模板的书写
- 照猫画虎学gnuplot之折线图
- Event事件的三个阶段
- maven多个子项目、父项目之间的引用问题
- python_传递任意数量的实参
- Canvas中的非零围绕规则原理