Pytorch实战学习(九):进阶RNN
《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
Advance RNN
1、RNN分类问题
判断数据集中的每个名字所属的国家,共有18个国家类别
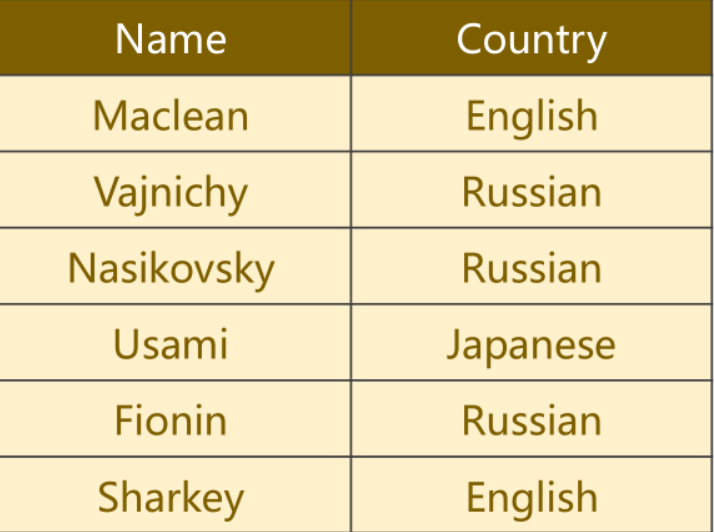
2、网络结构
①基础RNN
seq2seq,可以解决自动翻译问题
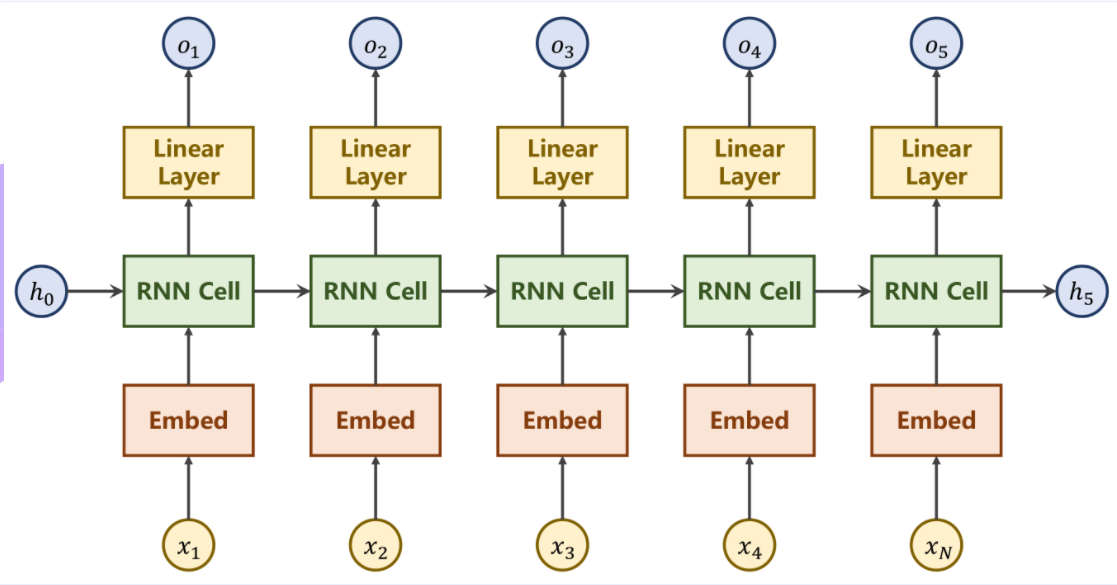
②简化RNN
利用最终的隐藏层状态 h_H 通过一个线性层来
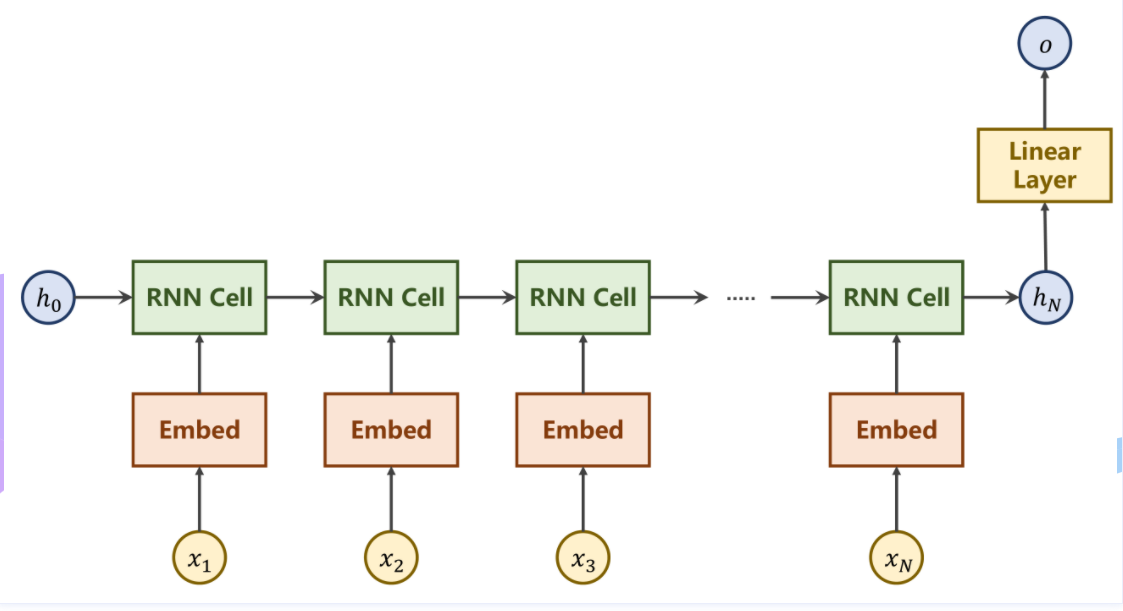
③本例具体结构
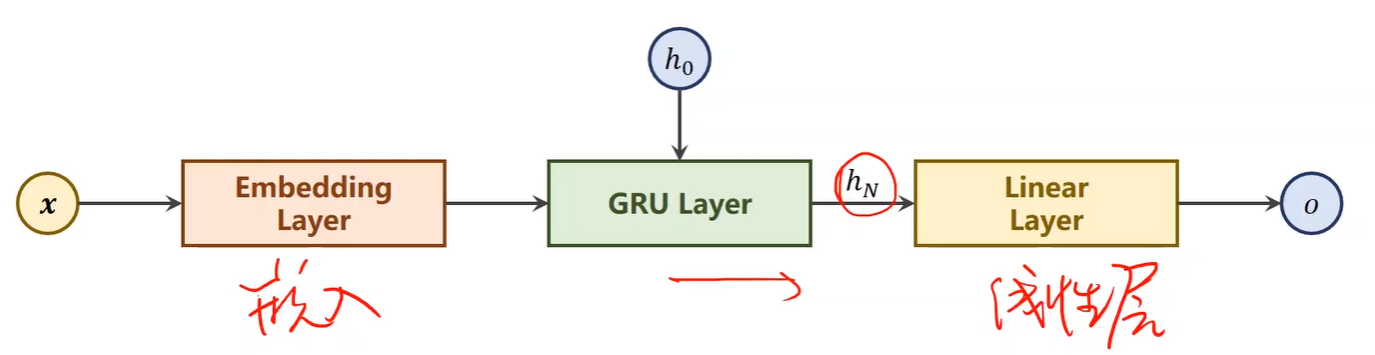
3、输入数据
文本数据
数据中的每个名字,实际上是一个序列,每个字母是序列中的一个输入,处理远比想象中费力
每个名字长短不一,即序列之间本身的长度是不固定的。
4、代码部分啦
①Main Cycle
def time_since(since):
s = time.time() - since
m = math.floor(s / 60)
s -= m*60
return '%dm %ds' % (m, s) if __name__ == '__main__':
'''
N_CHARS:字符数量,英文字母转变为One-Hot向量
HIDDEN_SIZE:GRU输出的隐层的维度
N_COUNTRY:分类的类别总数
N_LAYER:GRU层数
'''
classifier = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER)
#迁移至GPU
if USE_GPU:
device = torch.device("cuda:0")
classifier.to(device) criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(classifier.parameters(), lr=0.001) # 记录训练的时长
start = time.time()
print("Training for %d epochs ... " % N_EPOCHS)
#记录训练准确率
acc_list = []
for epoch in range(1, N_EPOCHS+1):
#训练模型
trainModel()
#检测模型
acc = testModel()
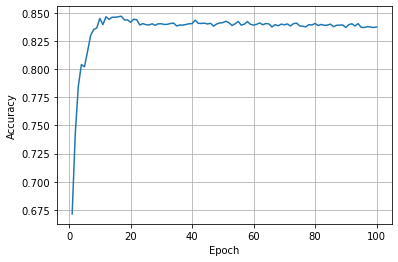
acc_list.append(acc) #绘制图像
epoch = np.arange(1, len(acc_list)+1, 1)
acc_list = np.array(acc_list)
plt.plot(epoch, acc_list)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.grid()
plt.show()
②Preparing Data
先将【Name】单词拆分成 字符,再用ASCII作为字典
每一个ASCII码值实际上代表着一个长为128的独热向量,以77为例,即在77处为1,其余全部为0
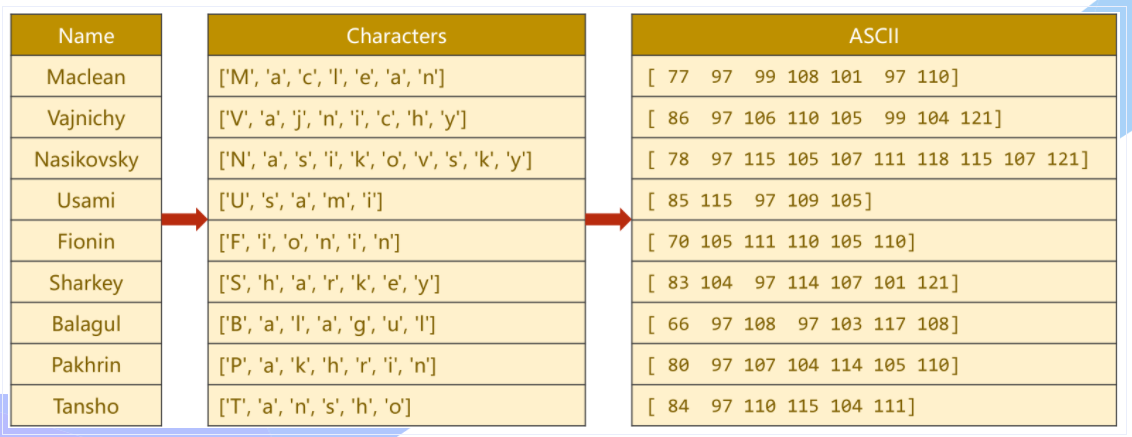
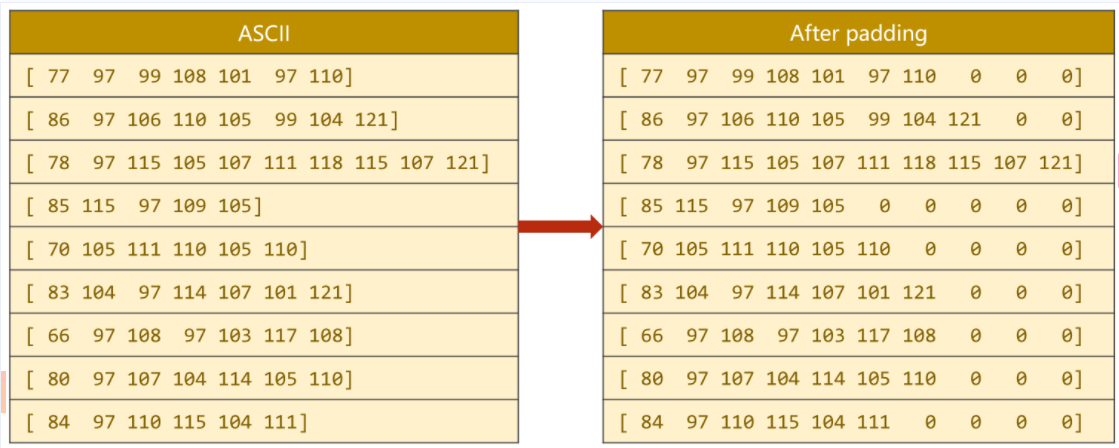
为保证计算,需要将所有输入的名字填充至等长,即进行padding填充,使之能够成为矩阵(张量)
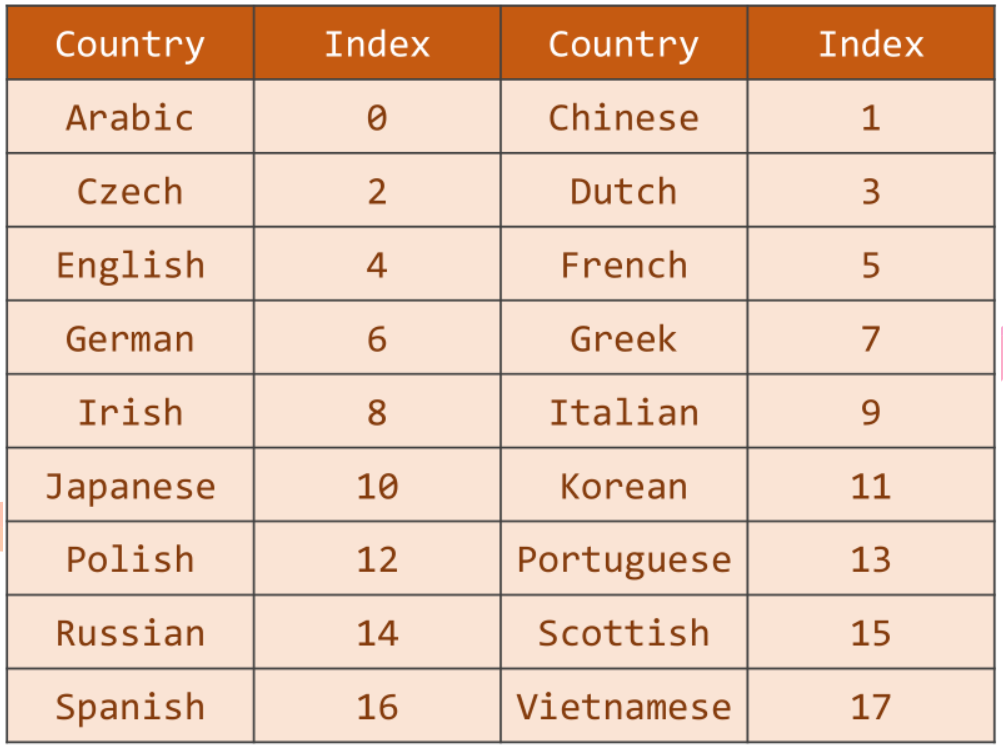
输出的国家类别形成分类索引
##Preparing Data
class NameDataset(Dataset):
def __init__(self, is_train_set=True): #读数据
filename = 'names_train.csv.gz' if is_train_set else 'names_test.csv.gz'
with gzip.open(filename, 'rt') as f:
reader = csv.reader(f)
rows = list(reader) #数据元组(name,country),将其中的name和country提取出来,并记录数量
self.names = [row[0] for row in rows]
self. len = len(self.names)
self.countries = [row[1] for row in rows] #将country转换成索引
#列表->集合->排序->列表->字典
# set将列表变成集合(去重)--排序--列表
self.country_list = list(sorted(set(self.countries)))
#列表->字典
self.country_dict = self.getCountryDict()
#获取长度
self.country_num = len(self.country_list) #name是字符串
#country是字典,获取键值对,country(key)-index(value)
def __getitem__(self, index):
return self.names[index], self.country_dict[self.countries[index]] def __len__(self):
return self.len def getCountryDict(self):
country_dict = dict()
for idx,country_name in enumerate(self.country_list, 0):
country_dict[country_name]=idx
return country_dict #根据索引返回国家名
def idx2country(self, index):
return self.country_list[index] #返回国家数目
def getCountriesNum(self):
return self.country_num # 参数设置
HIDDEN_SIZE = 100
BATCH_SIZE = 256
N_LAYER = 2 #GRU2层
N_EPOCHS = 100
N_CHARS = 128 #字典长度(ASCII码)
USE_GPU = False # 实例
trainset = NameDataset(is_train_set = True)
# 加载器
trainloader = DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True) testset = NameDataset(is_train_set=False)
testloader = DataLoader(testset, batch_size=BATCH_SIZE, shuffle=False) #最终的输出维度(国家类别数量)
N_COUNTRY = trainset.getCountriesNum()
③Model Design
## Model Design
class RNNClassifier(torch.nn.Module):
def __init__(self, input_size, hidden_size, output_size, n_layers =1 , bidirectional = True):
super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size
self.n_layers = n_layers
self.n_directions = 2 if bidirectional else 1 #Embedding层输入 (SeqLen,BatchSize)
#Embedding层输出 (SeqLen,BatchSize,HiddenSize)
#将原先样本总数为SeqLen,批量数为BatchSize的数据,转换为HiddenSize维的向量
self.embedding = torch.nn.Embedding(input_size, hidden_size)
#bidirection用于表示神经网络是单向还是双向
self.gru = torch.nn.GRU(hidden_size, hidden_size, n_layers, bidirectional = bidirectional)
#线性层需要*direction
self.fc = torch.nn.Linear(hidden_size * self.n_directions, output_size) def _init_hidden(self):
hidden = torch.zeros(self.n_layers * self.n_directions, batch_size, self.hidden_size) return create_tensors(hidden) def forward(self, input, seq_length):
#对input进行转置:Batch x Seq -> Batch x Seq
input = input.t()
batch_size = input.size(1) #(n_Layer * nDirections, BatchSize, HiddenSize)
hidden = self._init_hidden(batch_size)
#(SeqLen, BatchSize, HiddenSize)
embedding = self.embedding(input) #对数据计算过程提速
#需要得到嵌入层的结果(输入数据)及每条输入数据的长度
gru_input = pack_padded_sequence(embedding, seq_length) output, hidden = self.gru(gru_input, hidden) #如果是双向神经网络会有h_N^f以及h_N^b两个hidden
if self.n_directions == 2:
hidden_cat = torch.cat([hidden[-1], hidden[-2]], dim=1)
else:
hidden_cat = hidden[-1] fc_output = self.fc(hidden_cat) return fc_output
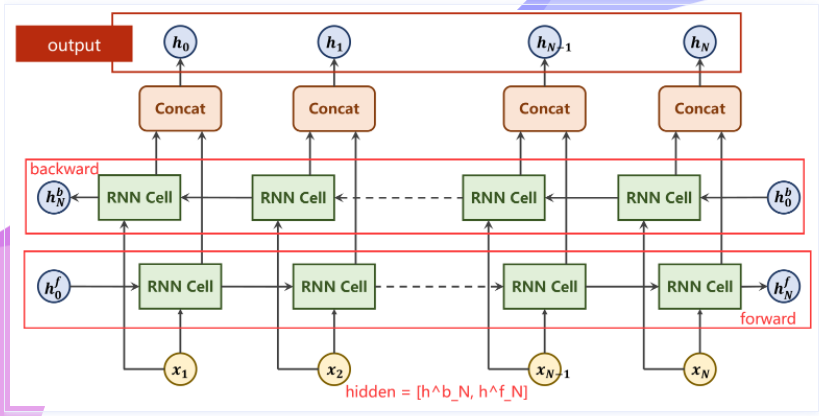
Bi-direction RNN/LSTM/GRU
全面考虑上下文信息
对于RNN系列的网络而言,其输出包括output以及hidden两部分。
output:序列对应输出,也就是 h_1....h_N
hidden:hidden指的是隐含层最终输出结果,在双向网络中即为 h_f_N 和 h_b_N
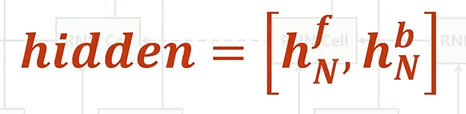

数据转置
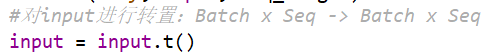

pack_padded_sequence
其原理在于,由于先前对于长短不一的数据需要填充0,而填充的0本质上不必参与运算,因此可以进行优化。
Embedding变换后的结果如图所示,其中深色部分为实际值为0即padding的部分。这部分可以不用参与运算。
***填充0的Embedding大小应该一样,下图有误***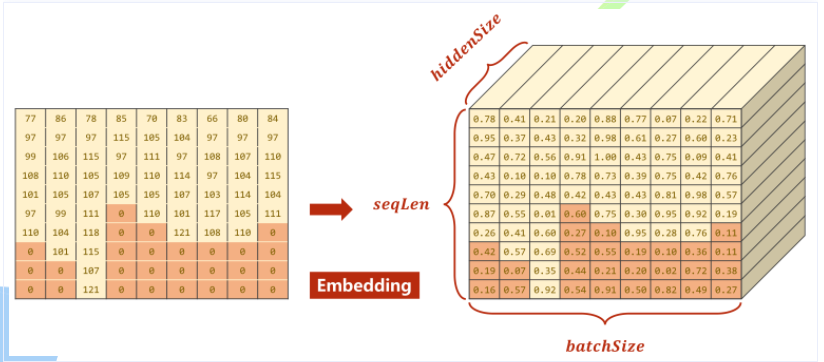
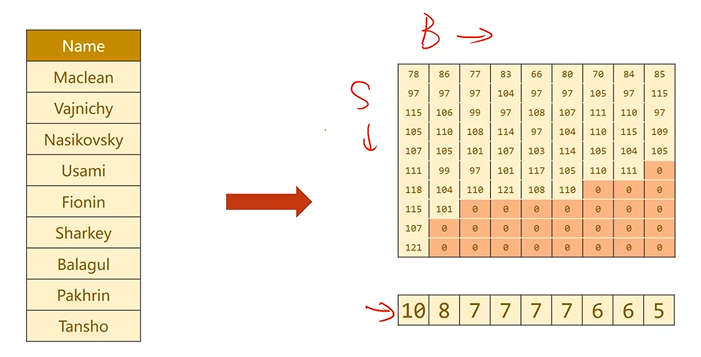
Batch中的序列先按照序列长短进行降序排序
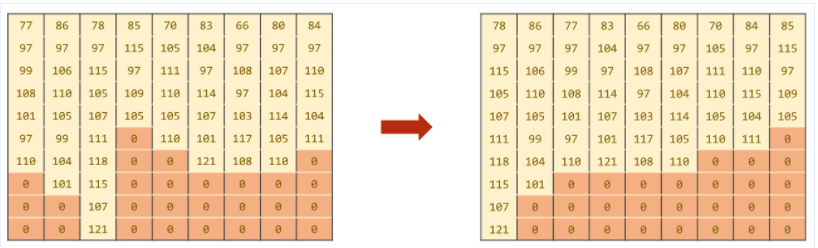
然后记录真正有意义的数字以及该序列的真正长度,最终返回一个PackedSequence对象
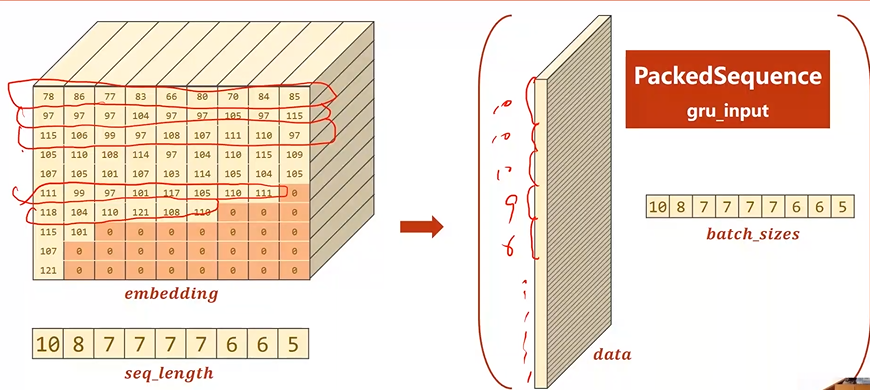
Name 转换成 Tensor
需要 Batch_size、Seq_size 和 每个name长度组成的list
转换过程:
字符串 → 字符 → ASCII码值 → Padding → 转置 → 排序
#ord()取ASCII码值
def name2list(name):
arr = [ord(c) for c in name]
return arr, len(arr) def create_tensor(tensor):
if USE_GPU:
device = torch.device("cuda:0")
tensor = tensor.to(device)
return tensor def make_tensors(names, countries):
sequences_and_length = [name2list(name) for name in names]
#取出所有的列表中每个姓名的ASCII码序列
name_sequences = [s1[0] for s1 in sequences_and_length]
#将列表车行度转换为LongTensor
seq_length = torch.LongTensor([s1[1] for s1 in sequences_and_length])
#将整型变为长整型
countries = countries.long() #做padding
#新建一个全0张量大小为最大长度-当前长度
seq_tensor = torch.zeros(len(name_sequences), seq_lengths.max()).long()
#取出每个序列及其长度idx固定0
for idx, (seq, seq_len) in enumerate(zip(name_sequences, seq_length), 0):
#将序列转化为LongTensor填充至第idx维的0到当前长度的位置
seq_tensor[idx, :seq_len] = torch.LongTensor(seq) #返回排序后的序列及索引
seq_length, perm_idx = seq_length.sort(dim = 0, descending = True)
seq_tensor = seq_tensor[perm_idx]
countries = countries[perm_idx] return create_tensor(seq_tensor),
create_tensor(seq_length),
create_tensor(countries)
④Training & Test
def trainModel():
total_loss = 0
for i, (names, countries) in enumerate(trainloader, 1):
inputs, seq_lengths, target = make_tensors(names, countries)
output = classifier(inputs, seq_lengths)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step() total_loss += loss.item() if i % 10 == 0:
print(f'[{time_since(start)}] Epoch {epoch} ', end='')
print(f'[{i * len(inputs)}/{len(train_set)}]', end='')
print(f'loss={total_loss / (i * len(inputs))}') return total_loss def testModel():
correct = 0
total = len(testset)
print("evaluating trained model……")
# 测试不需要求梯度
with torch.no_grad():
for i, (names, countries) in enumerate(testloader, 1):
inputs, seq_lengths, target = make_tensors(names, countries)
output = classifier(inputs, seq_lengths)
pred = output.max(dim=1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item() percent = '%.2f' % (100*correct/total)
print(f'Test set: Accuracy {correct}/{total} {percent}%')
return correct/total
⑤完整代码
import torch
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
import gzip
import csv
import time
from torch.nn.utils.rnn import pack_padded_sequence
import math
#可不加
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" ##Preparing Data
class NameDataset(Dataset):
def __init__(self, is_train_set=True): #读数据
filename = 'names_train.csv.gz' if is_train_set else 'names_test.csv.gz'
with gzip.open(filename, 'rt') as f:
reader = csv.reader(f)
rows = list(reader) #数据元组(name,country),将其中的name和country提取出来,并记录数量
self.names = [row[0] for row in rows]
self. len = len(self.names)
self.countries = [row[1] for row in rows] #将country转换成索引
#列表->集合->排序->列表->字典
# set将列表变成集合(去重)--排序--列表
self.country_list = list(sorted(set(self.countries)))
#列表->字典
self.country_dict = self.getCountryDict()
#获取长度
self.country_num = len(self.country_list) #name是字符串
#country是字典,获取键值对,country(key)-index(value)
def __getitem__(self, index):
return self.names[index], self.country_dict[self.countries[index]] def __len__(self):
return self.len def getCountryDict(self):
country_dict = dict()
for idx,country_name in enumerate(self.country_list, 0):
country_dict[country_name]=idx
return country_dict #根据索引返回国家名
def idx2country(self, index):
return self.country_list[index] #返回国家数目
def getCountriesNum(self):
return self.country_num # 参数设置
HIDDEN_SIZE = 100
BATCH_SIZE = 256
N_LAYER = 2 #GRU2层
N_EPOCHS = 100
N_CHARS = 128 #字典长度(ASCII码)
USE_GPU = False # 实例
trainset = NameDataset(is_train_set = True)
# 加载器
trainloader = DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True) testset = NameDataset(is_train_set=False)
testloader = DataLoader(testset, batch_size=BATCH_SIZE, shuffle=False) #最终的输出维度(国家类别数量)
N_COUNTRY = trainset.getCountriesNum() ## Model Design
class RNNClassifier(torch.nn.Module):
def __init__(self, input_size, hidden_size, output_size, n_layers =1 , bidirectional = True):
super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size
self.n_layers = n_layers
self.n_directions = 2 if bidirectional else 1 #Embedding层输入 (SeqLen,BatchSize)
#Embedding层输出 (SeqLen,BatchSize,HiddenSize)
#将原先样本总数为SeqLen,批量数为BatchSize的数据,转换为HiddenSize维的向量
self.embedding = torch.nn.Embedding(input_size, hidden_size)
#bidirection用于表示神经网络是单向还是双向
self.gru = torch.nn.GRU(hidden_size, hidden_size, n_layers, bidirectional = bidirectional)
#线性层需要*direction
self.fc = torch.nn.Linear(hidden_size * self.n_directions, output_size) def _init_hidden(self, batch_size):
hidden = torch.zeros(self.n_layers * self.n_directions, batch_size, self.hidden_size) return hidden def forward(self, input, seq_length):
#对input进行转置:Batch x Seq -> Batch x Seq
input = input.t()
batch_size = input.size(1) #(n_Layer * nDirections, BatchSize, HiddenSize)
hidden = self._init_hidden(batch_size)
#(SeqLen, BatchSize, HiddenSize)
embedding = self.embedding(input) #对数据计算过程提速
#需要得到嵌入层的结果(输入数据)及每条输入数据的长度
gru_input = pack_padded_sequence(embedding, seq_length) output, hidden = self.gru(gru_input, hidden) #如果是双向神经网络会有h_N^f以及h_N^b两个hidden
if self.n_directions == 2:
hidden_cat = torch.cat([hidden[-1], hidden[-2]], dim=1)
else:
hidden_cat = hidden[-1] fc_output = self.fc(hidden_cat) return fc_output #ord()取ASCII码值
def name2list(name):
arr = [ord(c) for c in name]
return arr, len(arr) def create_tensor(tensor):
if USE_GPU:
device = torch.device("cuda:0")
tensor = tensor.to(device)
return tensor ## Name 转换成 Tensor
def make_tensors(names, countries):
sequences_and_length = [name2list(name) for name in names]
#取出所有的列表中每个姓名的ASCII码序列
name_sequences = [s1[0] for s1 in sequences_and_length]
#将列表车行度转换为LongTensor
seq_lengths = torch.LongTensor([s1[1] for s1 in sequences_and_length])
#将整型变为长整型
countries = countries.long() #做padding
#新建一个全0张量大小为最大长度-当前长度
seq_tensor = torch.zeros(len(name_sequences), seq_lengths.max()).long()
#取出每个序列及其长度idx固定0
for idx, (seq, seq_len) in enumerate(zip(name_sequences, seq_lengths), 0):
#将序列转化为LongTensor填充至第idx维的0到当前长度的位置
seq_tensor[idx, :seq_len] = torch.LongTensor(seq) #返回排序后的序列及索引
seq_lengths, perm_idx = seq_lengths.sort(dim = 0, descending = True)
seq_tensor = seq_tensor[perm_idx]
countries = countries[perm_idx] return create_tensor(seq_tensor), create_tensor(seq_lengths), create_tensor(countries) def trainModel():
total_loss = 0
for i, (names, countries) in enumerate(trainloader, 1):
inputs, seq_lengths, target = make_tensors(names, countries)
output = classifier(inputs, seq_lengths)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step() total_loss += loss.item() if i % 10 == 0:
print(f'[{time_since(start)}] Epoch {epoch} ', end='')
print(f'[{i * len(inputs)}/{len(trainset)}]', end='')
print(f'loss={total_loss / (i * len(inputs))}') return total_loss def testModel():
correct = 0
total = len(testset)
print("evaluating trained model……")
# 测试不需要求梯度
with torch.no_grad():
for i, (names, countries) in enumerate(testloader, 1):
inputs, seq_lengths, target = make_tensors(names, countries)
output = classifier(inputs, seq_lengths)
pred = output.max(dim=1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item() percent = '%.2f' % (100*correct/total)
print(f'Test set: Accuracy {correct}/{total} {percent}%')
return correct/total def time_since(since):
s = time.time() - since
m = math.floor(s / 60)
s -= m*60
return '%dm %ds' % (m, s) if __name__ == '__main__':
'''
N_CHARS:字符数量,英文字母转变为One-Hot向量
HIDDEN_SIZE:GRU输出的隐层的维度
N_COUNTRY:分类的类别总数
N_LAYER:GRU层数
'''
classifier = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER)
#迁移至GPU
if USE_GPU:
device = torch.device("cuda:0")
classifier.to(device) criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(classifier.parameters(), lr=0.001) # 记录训练的时长
start = time.time()
print("Training for %d epochs ... " % N_EPOCHS)
#记录训练准确率
acc_list = []
for epoch in range(1, N_EPOCHS+1):
#训练模型
trainModel()
#检测模型
acc = testModel()
acc_list.append(acc) #绘制图像
epoch = np.arange(1, len(acc_list)+1, 1)
acc_list = np.array(acc_list)
plt.plot(epoch, acc_list)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.grid()
plt.show()
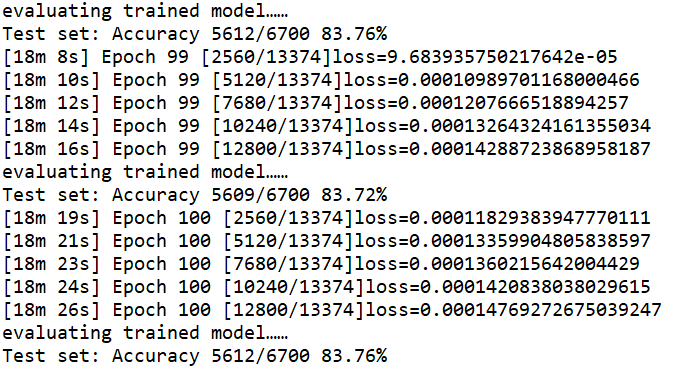
运行结果:准确率最高 83.79%,训练100次,花费18分半钟
最新文章
- 更新UI界面的四种方法
- [No000005]C#注册表操作,创建,删除,修改,判断节点是否存在
- 怎样写 OpenStack Neutron 的 Plugin (一)
- telnet不通11211端口,防火墙
- iOS多线程之NSOperation,NSOperationQueue
- wcf 获取客户端 IP
- TweenMax动画库学习(六)
- 常用后台frame框架
- css流式和弹性布局(未完)
- CSS盒子的浮动
- 数组查找算法的C语言 实现-----线性查找和二分查找
- 【45】java的封装剖析
- 开源ERP Odoo仓存功能模块深度应用(一)
- linux 替换 sed命令 转载
- 备忘录模式-Memento Pattern
- One-wire Demo on the STM32F4 Discovery Board
- Lucene--FuzzyQuery与WildCardQuery(通配符)
- linux 短信收发
- 关于Unity屏幕分辨率的比例
- Requests库请求网站
热门文章
- Django-request、django连接数据库、ORM
- 模拟实现strlen的三种方法
- 微信小程序wx.navigateTo跳转参数大小超出限制问题
- linux下删除文件夹的软链接时注意千万不能在后面加反斜杠,千万不要用强制删除,否则下面2种场景,你会把源文件删除,要闯祸的
- .Net依赖注入、控制反转
- Linux:touch 修改文件的时间
- Apache Maven Assembly自定义打包插件的使用
- Ubuntu中用普通方法无法添加自启动
- cximage菜单(Load Jpeg Resource)
- 98、TypeError: f.upload.addEventListener is not a function