Redis - 2 - 聊聊Redis的RDB和AOF持久化 - 更新完毕
1、RDB
1.1)、RDB是什么?
- RDB,全称Redis Database
- RDB是Redis进行持久化的一种方式,当然:Redis默认的持久化方式也是RDB
1.2)、Redis配置RDB
1.2.1)、编写配置
注:保证自己的linux中安装了docker和docker-compose,安装教程链接如下:
另:老衲的方法是采用docker和docker-compose来进行安装的Redis。官网让下载压缩包,然后安装gcc,使用make编译,从而安装的方式,老衲并没有采用
配制编写如下:
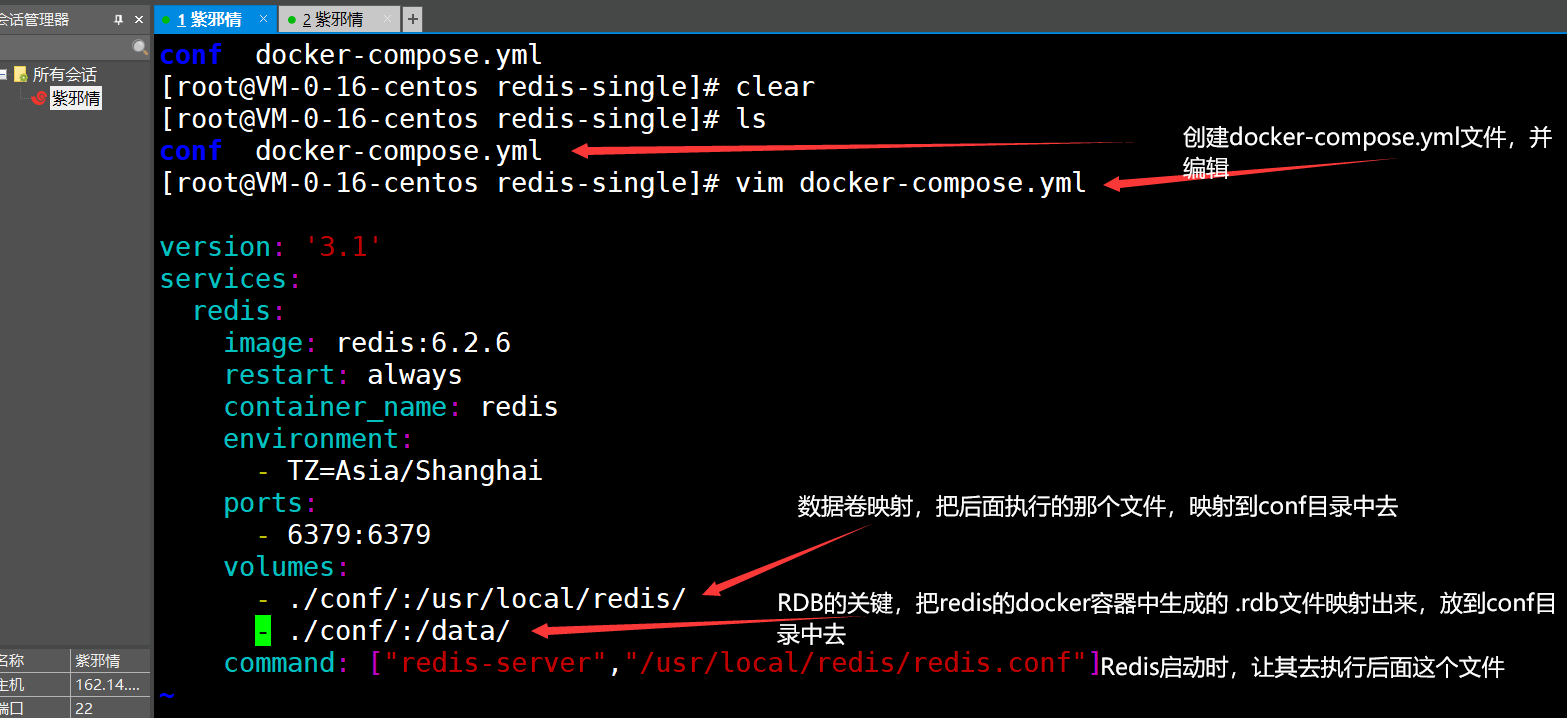
version: '3.1'
services:
redis:
image: redis:6.2.6
restart: always
container_name: redis
environment:
- TZ=Asia/Shanghai
ports:
- 6379:6379
volumes:
- ./conf/:/usr/local/redis/
- ./conf/:/data/
command: ["redis-server","/usr/local/redis/redis.conf"]
- 然后保存即可
1.2.2)、编写RDB配置
注:老衲的Redis是已经启动过了的,因此:接下来的一步如果看老衲博客的人当初不是采用的docker和docker-compose安装的Redis,那么经过上面的步骤之后,启动一下Redis就可以了,怎么启动这里不做说明,可以看一下老衲的docker-compose安装Redis教程,链接如下:
回到正题,编写RDB配置
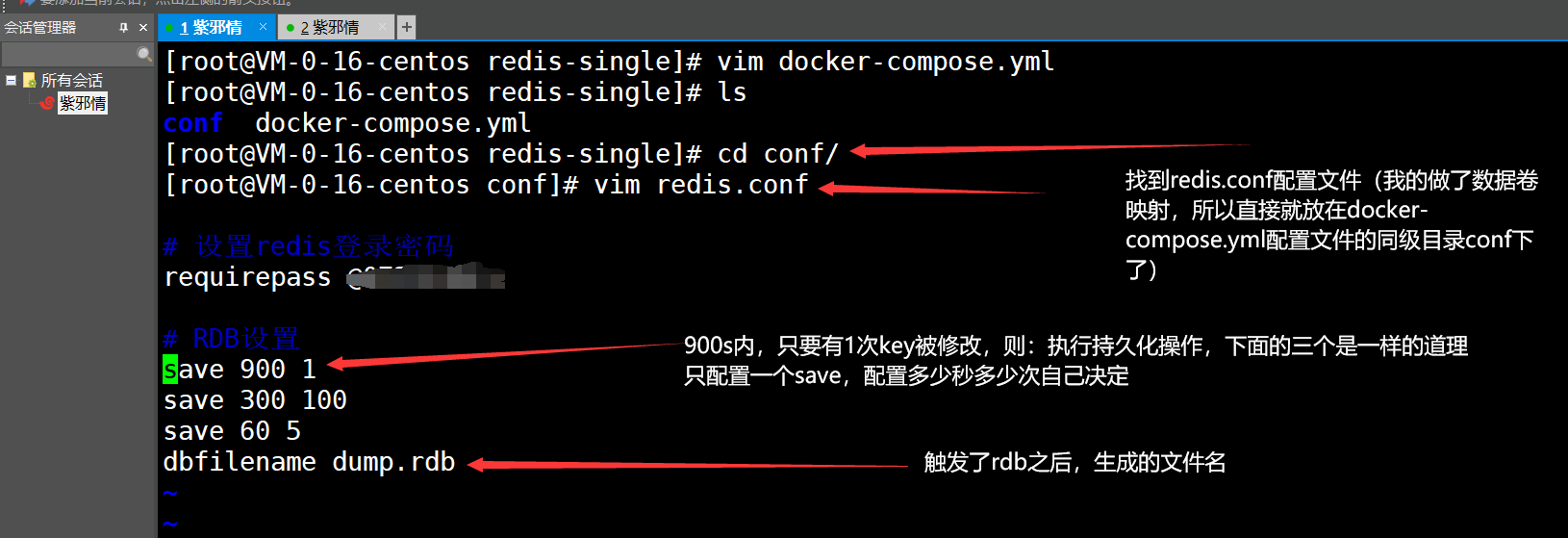
- 最后,保存即可
# 设置redis登录密码
requirepass 自己要设置的Redis登录密码
# RDB设置
save 900 1
save 300 100
save 60 5 # 这里使用5,是为了本博客中好测试,这些后面不说了,因为:这是基操,说起来烦得很
dbfilename dump.rdb
1.2.3)、重新启动Redis,进到Redis的docker容器内部

- 测试:触发RDB,save自己设定的次数次数据即可
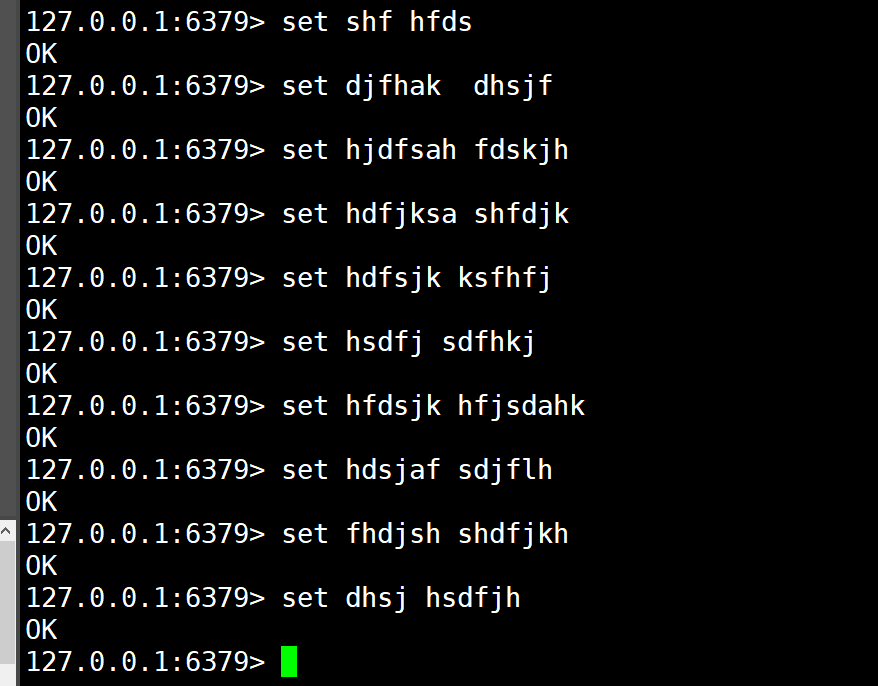
1.2.4)、回到映射的生成rdb文件的目录
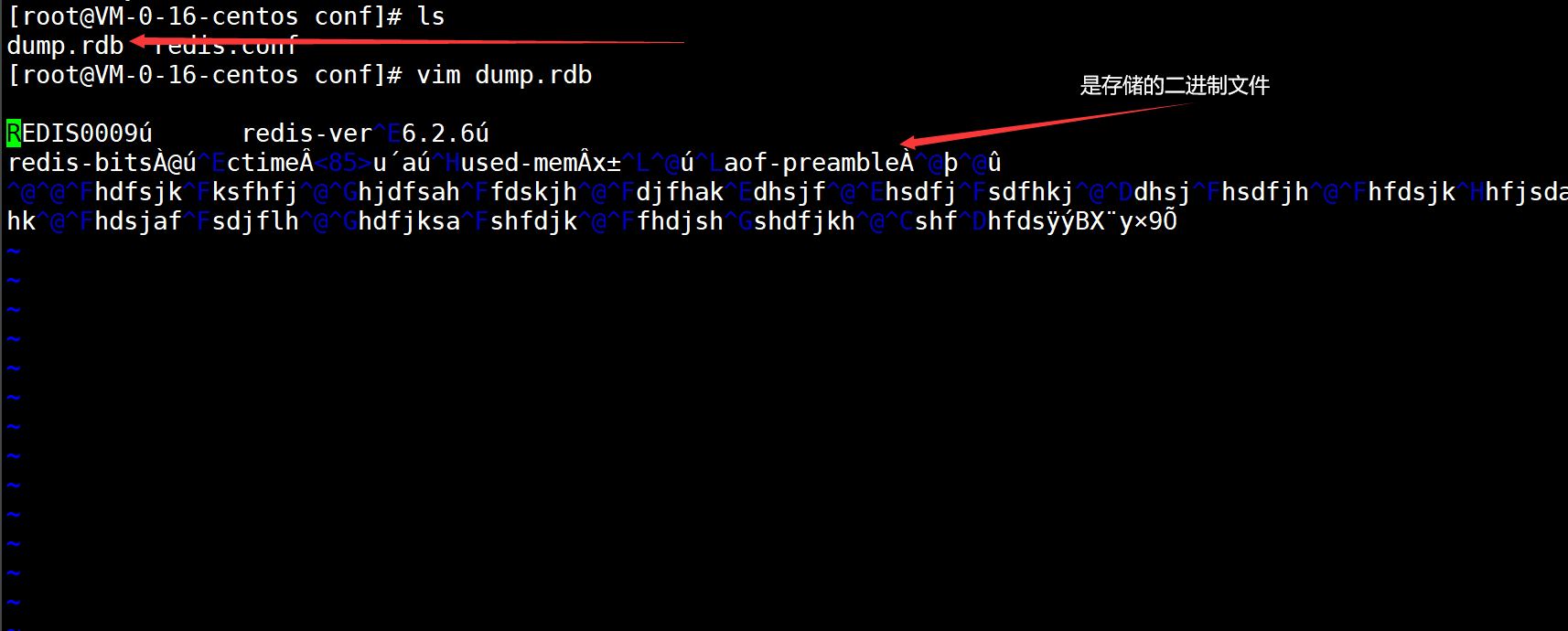
- 经过如上的操作之后,RDB就配置成功了,但是:老衲想说的其实不是上面这些,接下来才是我想说的
2、Redis的RDB原理
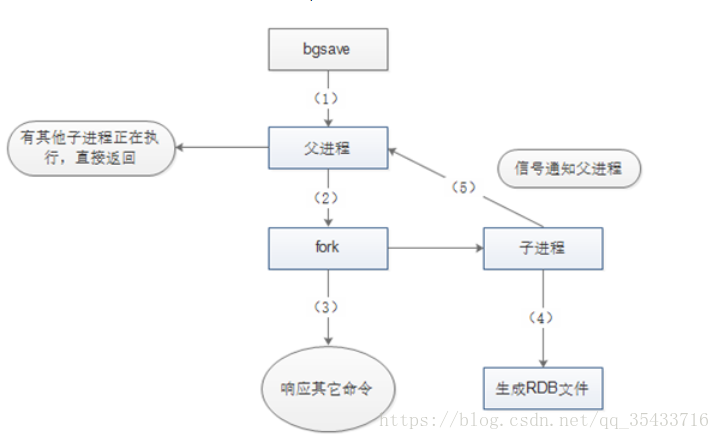
3、RDB的触发条件
1、肯定是使用save命令了( 先删掉生成的rdb文件,从而进行测试 )
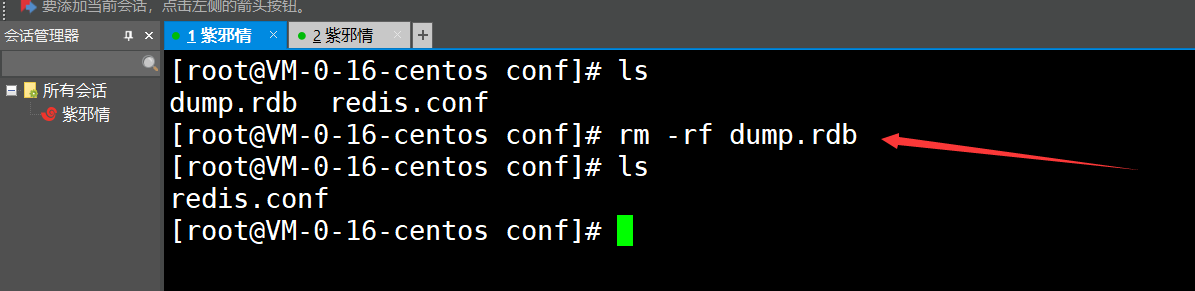
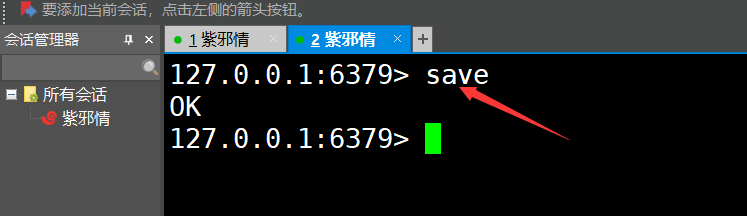
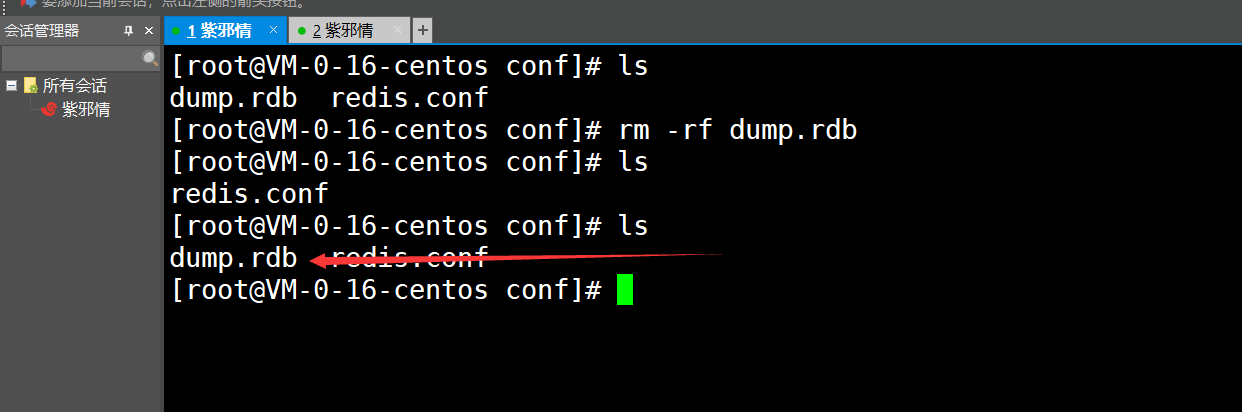
可见:成功触发了,后续的演示老衲不再做了,直说有哪些触发条件
这个命令触发RDB的原理:
- save命令会阻塞Redis服务器进程,直到RDB文件创建完毕为止,在Redis服务器阻塞期间,服务器不能处理任何命令请求
2、使用bgsave命令
这个命令也是推荐的一种,创建一个子进程,由子进程来负责创建RDB文件,父进程(即Redis主进程)则继续处理请求
注:bgsave命令执行过程中,只有fork子进程时会阻塞服务器,而对于save命令,整个过程都会阻塞服务器,因此save已基本被废弃,线上环境要杜绝save的使用
3、自动触发
- 这个就简单了,所谓的自动触发就是前面自己在redis.conf文件中配置哪些save,满足条件就触发了嘛
4、使用flushall命令、以及退出Redis也会触发( 先登进去,然后开另一个创建删掉rdb文件,再退出就发现也生成了 )
4、RDB的优缺点
- 缺点:
进行持久化时有一定的时间间隔( sava配置那里 ),如果刚好在哪个时间点内在保存数据,而此时出现宕机了,则:会导致要保存的数据没有保存成功( 不能保证数据的绝对安全 )
- 举个例子:假如900内是有一次key发生改变就保存数据,但是:在key正在准备改变时,redis宕机了呢?这数据不就没了吗( redis的数据一开始是在内存中的,还没持久化到磁盘 )
RDB是开了一个子进程来进行创建rdb文件,因此:会造成空间的浪费
———————————————————官方话如下:—————————————————————————————
如果你希望在redis意外停止工作(例如电源中断)的情况下丢失的数据最少的话,那么RDB不适合你.虽然你可以配置不同的save时间点(例如每隔5分钟并且对数据集有100个写的操作),是Redis要完整的保存整个数据集是一个比较繁重的工作,你通常会每隔5分钟或者更久做一次完整的保存,万一在Redis意外宕机,你可能会丢失几分钟的数据
RDB 需要经常fork子进程来保存数据集到硬盘上,当数据集比较大的时候,fork的过程是非常耗时的,可能会导致Redis在一些毫秒级内不能响应客户端的请求.如果数据集巨大并且CPU性能不是很好的情况下,这种情况会持续1秒,AOF也需要fork,但是你可以调节重写日志文件的频率来提高数据集的耐久度
优点:
- 适合大规模的数据恢复
- 持久化速度快,相对AOF来说:数据安全( 二进制文件嘛 )
—————————————————————官方话如下:—————————————————————————————
- RDB是一个非常紧凑的文件,它保存了某个时间点得数据集,非常适用于数据集的备份,比如你可以在每个小时报保存一下过去24小时内的数据,同时每天保存过去30天的数据,这样即使出了问题你也可以根据需求恢复到不同版本的数据集
- RDB是一个紧凑的单一文件,很方便传送到另一个远端数据中心或者亚马逊的S3(可能加密),非常适用于灾难恢复
- RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能.
- 与AOF相比,在恢复大的数据集的时候,RDB方式会更快一些
2、AOF
2.1)、什么是AOF
- 全称:append only file
- AOF是Redis进行持久化的另外一种操作方式
2.2)、配置AOF
2.2.1)、编写redis.conf文件
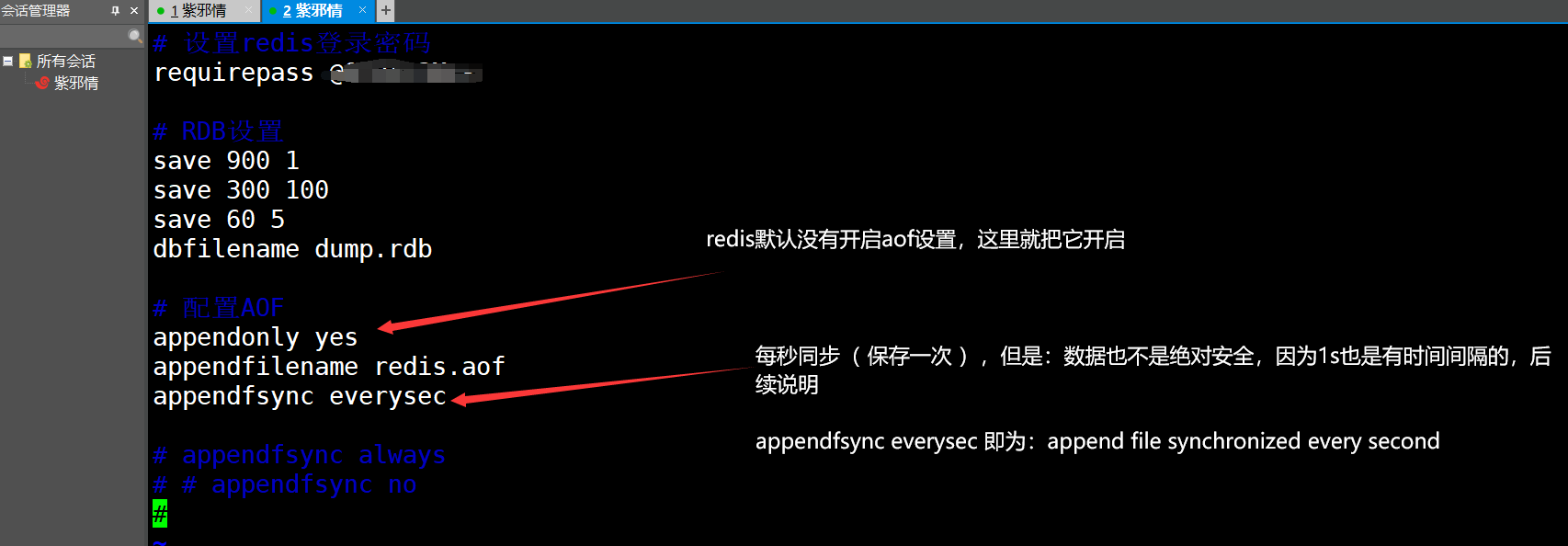
- 编写内容如下:
# 配置AOF
appendonly yes
appendfilename redis.aof
appendfsync everysec
# 下面这两个是另外一种配置措施,一般都不考虑
# appendfsync always
# # appendfsync no
- appendfsync always:每执行一个写操作,立即持久化到AOF文件中,性能比较低
- appendfsync everysec:每秒执行一次持久化
- appendfsync no:会根据你的操作系统不同,环境的不同,在一定时间内执行一次持久化
2.2.2)、重启Redis即可
- 重启之后,测试如下:
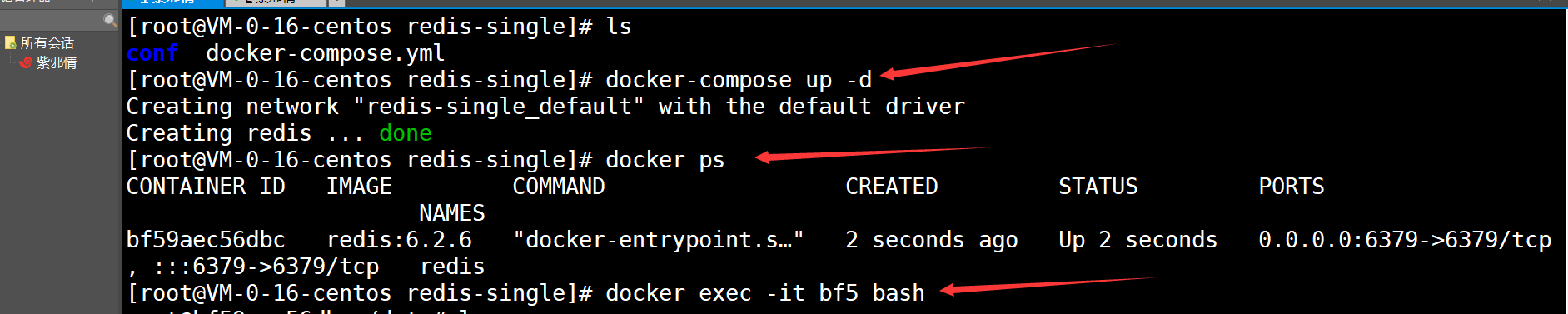

2.2.3)、检查数据卷映射的文件目录
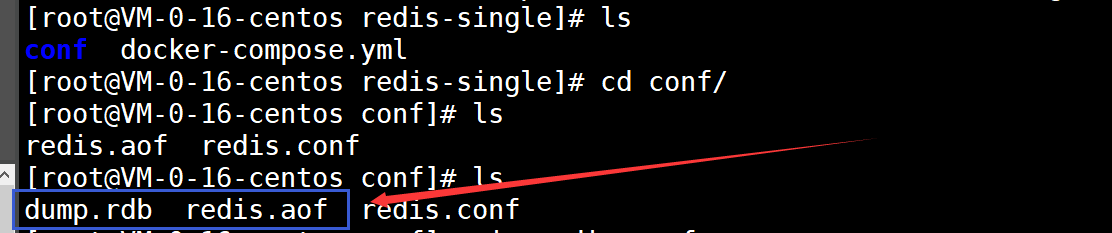
可见:多出了 .aof文件
查看一下这个 aof文件

- 发现:这个aof文件中存储的就是我们刚刚在redis中存储key-value时的指令
还是老话,前面这些不是老衲想说的,下面的才是老衲准备说的内容
2、AOF的原理
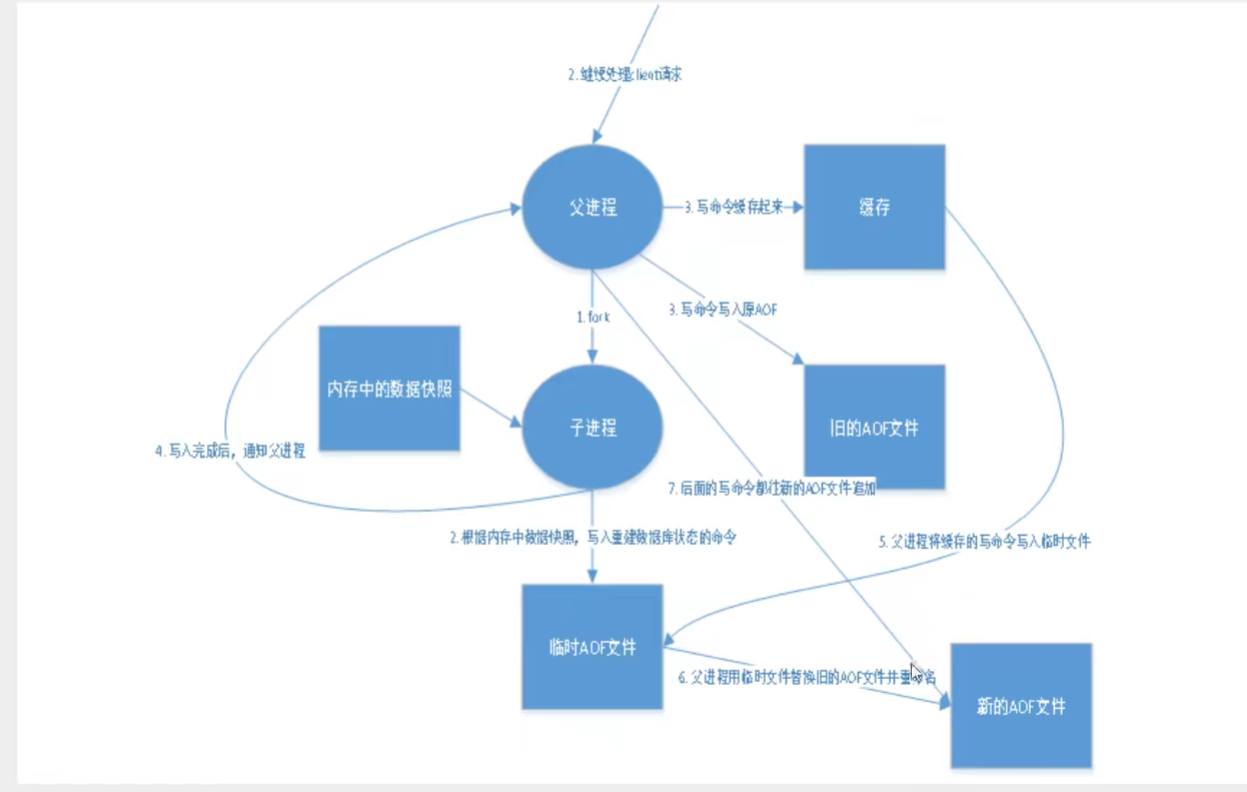
3、AOF的触发条件
- 一句话:只要配置了,那么只要启动Redis就会触发( 可以把aof文件删掉,然后重启Redis,再看映射文件路径,就会发现有了aof文件 )
4、AOF的优缺点
- 缺点:
数据恢复慢( 大数据时,它是去重新执行一遍aof文件中的数据 ,它存的是指令,是一个文本文件,大数据时,这就会变得很大 ,但是:)

- 可以加入这个配置,从而限定:内容超过多大之后,就另起一个aof文件来记录内容[专业词:重写]( 重新写一个aof文件 )
—————————————————————官方话如下:—————————————————————————————
对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积
根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)
优点:
- 采用每修改词义就同步的话,数据的完整性比较好
- 采用每秒同步一次的话,持久化也快,注:容易丢失这一份的数据,对照RDB来看
- 采用从不同步的话,效率蛮高,但是:不建议
—————————————————————官方话如下:—————————————————————————————
AOF文件是一个只进行追加的日志文件,所以不需要写入seek,即使由于某些原因(磁盘空间已满,写的过程中宕机等等)未执行完整的写入命令,你也也可使用redis-check-aof工具修复这些问题
Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作
AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单: 举个例子, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态
注:AOF记录的是每次写操作,读操作并不会记录滴
3、建议
- 同时开启rdb和aof

最新文章
- Ubuntu 安装mysql和简单操作
- PMP 第八章 项目质量管理
- LR之配置端口映射(port mapping)
- (转)MongoDB 3.0 WT引擎参考配置文件
- Java中实现复制文件或文件夹
- WPF 界面布局DockPanel stackPanel WrapPanel 元素内容以及位置控制
- Python判断上传文件类型
- Extjs中numberfield小数位数设置
- 初探JS正则表达式
- 运行一个android程序,直接访问某个网站
- java读取和写入txt文件
- 剑指offer_(4)
- VIM系统复制粘贴
- SQL Server之深入理解STUFF
- 单元测试系列之十:Sonar 常用代码规则整理(二)
- spring mvc 自动生成代码
- luogu2024 食物链 (并查集)
- IDA Pro Disassembler 6.8.15.413 (Windows, Linux, Mac)
- Avatar
- null和System.DBNull.Value的区别