[源码解析] 机器学习参数服务器Paracel (3)------数据处理
[源码解析] 机器学习参数服务器Paracel (3)------数据处理
0x00 摘要
Paracel是豆瓣开发的一个分布式计算框架,它基于参数服务器范式,用于解决机器学习的问题:逻辑回归、SVD、矩阵分解(BFGS,sgd,als,cg),LDA,Lasso...。
Paracel支持数据和模型的并行,为用户提供简单易用的通信接口,比mapreduce式的系统要更加灵活。Paracel同时支持异步的训练模式,使迭代问题收敛地更快。此外,Paracel程序的结构与串行程序十分相似,用户可以更加专注于算法本身,不需将精力过多放在分布式逻辑上。
前文介绍了PyTorch 的数据处理部分,本文接着介绍Paracel的数据处理部分,正好可以与PyTorch做一下印证。
为了行文完整,本文部分基础知识与前文重复,另外在解析时候会删除部分非主体代码。
参数服务器系列其他文章如下:
[源码解析] 机器学习参数服务器ps-lite 之(1) ----- PostOffice
[源码解析] 机器学习参数服务器ps-lite(2) ----- 通信模块Van
[源码解析] 机器学习参数服务器ps-lite 之(3) ----- 代理人Customer
[源码解析]机器学习参数服务器ps-lite(4) ----- 应用节点实现
[源码解析] 机器学习参数服务器 Paracel (1)-----总体架构
[源码解析] PyTorch 分布式(1) --- 数据加载之DistributedSampler
[源码解析] PyTorch 分布式(2) --- 数据加载之DataLoader
0x01 切分需要
1.1 切分的好处
深度学习领域的特点是:海量数据 + 海量运算。因为会出现运算时间过长或者模型过大的情况,所以会对数据或者模型进行切分,从而并行的分布式的解决问题,就是我们常常听到的数据并行或者模型并行。
切分问题包括对训练数据和训练模型的切分。即:切分模型以便处理大模型,切分数据以加速训练。
1.2 数据并行
比如下图中,每一个节点都拥有一个模型的完整拷贝,但是每个节点的训练数据不同。每个节点上运行一个训练进程,我们称之为 worker。这些worker读取一个批次数据,各自完成前向计算和后向传播,得到梯度,然后把各自的梯度提交到参数服务器上,由参数服务器进行归并/更新参数操作,然后参数服务器把更新后的模型回传给各个节点,然后每个计算节点负责对本地模型的参数进行更新。进行新一轮迭代训练。
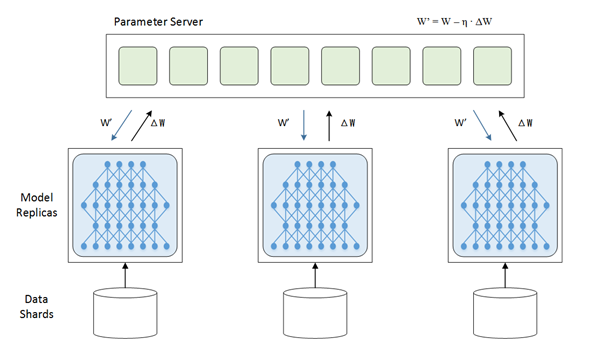
1.3 模型并行
如果可以对模型进行有意义的分割,然后分段加载并且传送到参数服务器上,算法也支持分段并行处理,那么理论上就可以进行模型并行。我们首先可以把模型分为线性可分模型和非线性模型(神经网络)。
1.3.1 线性模型
针对线性模型,我们可以把模型和数据按照特征维度进行划分,分配到不同的计算节点上,每个节点的局部模型参数计算不依赖于其他维度的特征,彼此相对独立,不需要与其他节点进行参数交换。这样就可以在每个计算节点上采用梯度下降优化算法进行优化,进行模型并行处理。
某些机器学习问题,如矩阵因子化、主题建模和线性回归,由于使用的小批量大小不是非常大,从而提高了统计效率,因此模型并行通常可以实现比数据并行更快的训练时间。
1.3.2 非线性模型(神经网络)
神经网络的模型与传统机器学习模型不同,具有如下特点:
- 神经网络具有很强的非线性,参数之间有较强的关联依赖。
- 深度学习的计算本质上是矩阵运算,这些矩阵保存在GPU显存之中。
- 因为过于复杂,所以神经网络需要较高的网络带宽来完成节点之间的通信。
根据这些特征,神经网络可以分为 层间分割 和 层内分割:
- 层间分割:横向按层划分或纵向跨层划分进行网络划分。每个计算节点计算然后通过RPC将参数传递到其他节点上进行参数的合并。从网络角度来看,就是把神经网络结构拆分。
- 层内分割:如果矩阵过大,则一张显卡无法加载整个矩阵,这就需要把一张巨大矩阵拆分开来放到不同GPU上去计算,每个GPU只负责模型的一部分。从计算角度看就是把矩阵做分块拆分处理。
具体可以参见下图:
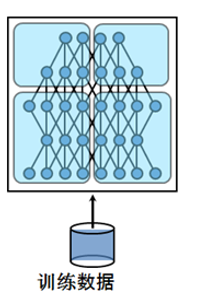
1.4 混合使用
有的时候数据并行和模型并行会被同时用上。
- 对于与数据相关的这类模型(如矩阵分解,pagerank,svd等,换句话说就是model是key-value的样子,key对应一个物体或人),我们可以通过对数据的切分来控制切分模型的方式。
- 有些模型不直接和数据相关(如LR、神经网络等),这时只要分别对数据和模型做各自的切分即可。
比如:
- 卷积神经网络中卷积层计算量大,但所需参数系数 W 少,适合使用数据并行。
- 全连接层计算量小,所需参数系数 W 多。适合使用模型并行。
就像这样:
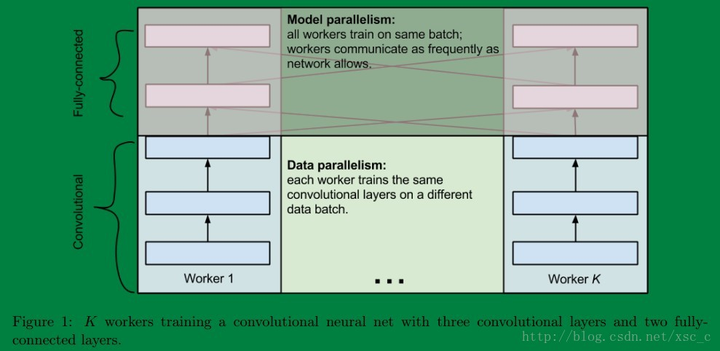
0x02 切分机制与数据格式
2.1 切分原则
切分数据意味着减少计算量,切分模型的方式则决定了计算和通信的拓扑。不同的划分方式可能导致计算性能上的差异。所以我们要试图寻找切分的一些原则:
切分数据的同时尽量保证切开的模型大小均衡以及通信较优。
要能保证参数服务器负载均衡,降低参数服务器单点性能瓶颈,降低网络传输成本(比如在网络中传输Embedding模型参数,整个时延和成本将是不可接受的),因此原则如下:
- 关联的数据/模型在同一个参数服务器上。
- 尽量将一个模型平均分配到所有参数服务器节点上。
- 对于非常小的模型,将它们尽量放在一个参数服务器节点上。
- 对于多行的模型,尽量将同一行放在一个参数服务器节点上。
提供定制化的需求,因为各个算法,或者一个算法的各种实现,对划分方式要求都不一样。
2.2 模型和数据格式
因为分布式实际上不仅包括计算分布式,也涉及到存储分布式。这就要求模型文件和数据文件的格式必须天生支持切分。
对于与数据相关的模型(如矩阵分解,pagerank,svd等,即模型表示成key-value格式),可以通过对数据的切分来控制切分模型的方式。另一些情况是模型不直接和数据相关(如LR、神经网络等),只要分别对数据和模型做各自的切分即可。
在这个方面,各个公司也做了自己的努力。比如腾讯的Angel的模型是以矩阵为单位来保存的。默认情况下, Angel将模型(矩阵)切分成大小相等的矩形区域,每一个矩阵在模型保存路径下对应一个以矩阵名命名的文件夹,里面包含矩阵的元数据文件和数据文件。一个矩阵只有一个元数据文件(元数据主要由矩阵特征,分区索引和行相关索引组成),但是一般有多个数据文件。
2.3 Paracel 数据机制
Paracel 提供了丰富的数据切分方式,我们需要从几个方面一一说明。
2.3.1 数据表示
Paracel用图和矩阵来表示训练数据。
有四种类型的图:
- bigraph
- bigraph_continuous
- digraph
- undirected_graph
Paracel使用 Eigen3库来支撑矩阵/向量的操作,因此支持两种矩阵:
- SparseMatrix
- MatrixXd
我们以bigraph为例看看。
在图论的数学领域中,bigraph的顶点可以划分为两个不相交的集合U和V(即U和V是各自独立的集合),使得U中的一个顶点与V中的一个顶点相连。
定义如下:
template <class T = paracel::default_id_type>
class bigraph {
private:
size_t v_sz = 0;
size_t e_sz = 0;
paracel::dict_type<T, paracel::dict_type<T, double> > adj;
public:
MSGPACK_DEFINE(v_sz, e_sz, adj);
public:
bigraph();
bigraph(std::unordered_map<T, std::unordered_map<T, double> > edge_info);
bigraph(std::vector<std::tuple<T, T> > tpls);
bigraph(std::vector<std::tuple<T, T, double> > tpls);
void add_edge(const T & v, const T & w);
void add_edge(const T & v, const T & w, double wgt);
// return bigraph data
std::unordered_map<T, std::unordered_map<T, double> > get_data();
// traverse bigraph edge using functor func
template <class F>
void traverse(F & func);
// traverse vertex v’s related edges using functor func
template <class F>
void traverse(const T & v, F & func);
// return U bag
std::vector<T> left_vertex_bag();
// return U set
std::unordered_set<T> left_vertex_set();
// out: tpls
void dump2triples(std::vector<std::tuple<T, T, double> > & tpls);
// out: dict
void dump2dict(std::unordered_map > & dict);
// return number of vertexes in U
inline size_t v();
// return number of edges in bigraph
inline size_t e();
// return adjacent info of vertex v
std::unordered_map<T, double> adjacent(const T & v);
// return outdegree of vertex u in U
inline size_t outdegree(const T & u);
// return indegree of vertex v in V
inline size_t indegree(const T & v);
};
2.3.2 数据加载
Paracel为加载输入文件提供了各种接口。在最新版本中,所有与加载相关的接口都只支持文本格式的文件,这样会占用多一些内存。
用户可以并行读取数据的一个分区对应的行,然后构造自定义的数据结构,也可以直接将输入数据加载为Paracel的“graph”或“matrix”类型。在后一种情况下,必须使用'pattern'和'mix_flag'变量来描述输入文件的结构。Pattern还决定输入数据的分区方法。
Paracel用变量“pattern”定义了几个模式:
| pattern | structure | line example |
|---|---|---|
| linesplit(default) | 用行来确定分区 | all structures |
| fmap | first-second case(value set to 1.0) first-second-value case 依据第一个字段进行分区 |
a,b a,b,0.2 |
| smap | second-first case(value set to 1.0) second-first-value case 依据第二个字段进行分区 |
a,b a,b,0.2 |
| fsmap | support the same structure as fmap and smap 用两个字段一起分区 |
a,b or a,b,0.2 |
| fvec | id,feature1,…,feature k, 依据id分区 |
1001 0.1|0.2|0.3|0.4 |
| fset | attr1,attr2,attr3,… attr1,attr2|value2,attr3|value3,… 依据第一个字段进行分区 |
a,b,c or a,b|0.2,c|0.4 |
变量mix_flag 表示图形/矩阵的链接关系是否在一行中定义。如下面的示例所示,当mix_flag 设置为false时,节点 “a” 的所有链接关系都展开为三行。如果“pattern”等于“fvec”和“fset”,则mix_flag 始终为“true”。
| mix_flag | example |
|---|---|
| true | a,b,c,d b,c,d … |
| true | a,b a,c,d b,c b,d … |
| false(default) | a,b a,c a,d b,c b,d … |
如上所述,pattern不仅决定数据格式,还决定分区策略,而mix_flag告诉Paracel链接关系是否在一行中混合。
0x03 数据加载
3.1 并行处理
AI框架的数据处理主要如下并行处理:
- 数据加载/处理使用CPU。
- 训练使用GPU。
在理想状态下,应该是每轮迭代训练之前,CPU就完成加载,准备好训练数据,这样训练就可以持续无缝迭代。
然而,GPU算力每年会提升一倍,CPU的提升速度远远落后于GPU,所以CPU会是拖后腿的那个角色。这里不仅仅是CPU算力不足的问题,也包括从存储中读取数据速度不足的问题。
因此,机器学习对于数据加载和前期预处理的要求越来越高,必须在GPU计算时间内,完成下一迭代数据的准备工作,不能让GPU因为等待训练数据而空闲。
3.2 流水线
对于机器学习训练,加载数据可以分为三个步骤:
- 将数据从磁盘或者分布式存储加载到主机(CPU)。
- 将数据从主机可分页内存传输到主机固定内存。
- 将数据从主机固定内存转移到主机GPU。
因此,流行的深度学习框架会依据加载步骤的特点和异构硬件的特点来进行流水线处理,从而提高数据处理过程的吞吐量。
流水线一般包括多个算子,每个算子内部由数据队列组成一个缓冲区,上游算子完成处理之后会传给给下游算子进行处理。这样每个算子任务会彼此独立,算子内部可以使用细粒度的多线程/多进程来并行加速,每个算子可以独立控制处理速度和内存以适配不同网络对于处理速度的需求。
如果算子内部数据队列不为空,模型就会一直源源不断获得数据,就不会因为等待训练数据而产生瓶颈。
下面是串行处理逻辑:
+------+ +-----------+ +---------------------------+
| | | | | |
| Data +----------> | Load Data +---------> | Transfer to Pinned Memory |
| | | | | |
+------+ +-----------+ +---------------------------+
下面是并行流水线逻辑:
+------------+
+--------+ | |
| | | Process 1 |
| Data 1 +--------> | +------+
| | | Load Data | |
+--------+ | | |
+------------+ |
|
|
|
+------------+ |
+--------+ | | | +-----------------------------+
| | | Process 2 | +------> | Pin-memory process |
| Data 2 +--------> | | | |
| | | Load Data +-------------> | |
+--------+ | | | Transfer to Pinned Memory |
+------------+ +-----> +-----------------------------+
|
|
|
+--------+ +------------+ |
| | | | |
| Data 3 +--------> | Process 3 +-------+
| | | |
+--------+ | Load Data |
| |
+------------+
3.3 GPU
本文到现在是解决CPU侧的数据传输问题,即:从磁盘加载数据,从可分页到固定内存。
但是,从固定内存到GPU的数据传输(tensor.cuda())也可以使用CUDA流进行流水线处理。
另外,深度学习应用程序需要复杂的多阶段数据处理管道,包括加载、解码、裁剪、调整大小和许多其他增强功能。这些目前在 CPU 上执行的数据处理管道已经成为瓶颈,限制了训练和推理的性能和可扩展性。
Nvidia DALI 通过将数据预处理放到 GPU 处理来解决 CPU 瓶颈问题,用户可以依据自己模型的特点,构建基于 GPU 的 pipeline,或者基于CPU的pipeline。

0x04 Paracel数据加载
前面提到,Paracel使用图,矩阵等进行数据加载,接下来我们就看看具体如何实现。
4.1 样例代码
我们从源码中选取样例,恰好里面有model partition 和 data partition 字样。
其实,这里的意思是:并行加载模型和并行加载数据。
class adjust_ktop_s : public paracel::paralg {
public:
adjust_ktop_s(paracel::Comm comm,
std::string hosts_dct_str,
std::string _rating_input,
std::string _fmt,
std::string _sim_input,
int _low_limit,
std::string _output) :
paracel::paralg(hosts_dct_str, comm, _output),
rating_input(_rating_input),
fmt(_fmt),
sim_input(_sim_input),
low_limit(_low_limit) {}
virtual void solve() {
// load sim_G, model partition 并行加载模型
auto local_parser = [] (const std::string & line) {
auto tmp = paracel::str_split(line, '\t');
auto adj = paracel::str_split(tmp[1], '|');
std::vector<std::string> stuff = {tmp[0]};
stuff.insert(stuff.end(), adj.begin(), adj.end());
return stuff;
};
auto parser_func = paracel::gen_parser(local_parser);
paracel_load_as_graph(sim_G,
sim_input,
parser_func,
"fset");
// load rating_G, data partition 并行加载数据
auto local_parser_rating = [] (const std::string & line) {
return paracel::str_split(line, ',');
};
auto local_parser_rating_sfv = [] (const std::string & line) {
std::vector<std::string> tmp = paracel::str_split(line, ',');
std::vector<std::string> r({tmp[1], tmp[0], tmp[2]});
return r;
};
auto rating_parser_func = paracel::gen_parser(local_parser_rating);
if(fmt == "sfv") {
rating_parser_func = paracel::gen_parser(local_parser_rating_sfv);
}
paracel_load_as_graph(rating_G,
rating_input,
rating_parser_func,
fmt);
// init rating_G
paracel::dict_type<std::string, double> tmp_msg;
auto init_lambda = [&] (const node_t & uid,
const node_t & iid,
double v) {
std::string key = std::to_string(uid) + "_" + std::to_string(iid);
tmp_msg[key] = v;
};
rating_G.traverse(init_lambda);
paracel_write_multi(tmp_msg);
paracel_sync();
// learning
cal_low_peak();
}
private:
std::string rating_input, fmt;
std::string sim_input;
int low_limit = 1;
paracel::bigraph<node_t> sim_G;
paracel::bigraph<node_t> rating_G;
paracel::dict_type<node_t, int> ktop_result;
double training_rmse = 0., original_rmse = 0.;
}; // class adjust_ktop_s
4.2 加载图
对于图结构的数据或者模型,首先每个 worker 会通过fixload并行加载文件,然后会通过paracel_sync进行同步。
注意:每个worker都会执行以下函数,内部会通过MPI进行协调和统一。
template <class T, class G>
void paracel_load_as_graph(paracel::bigraph<G> & grp,
const T & fn,
parser_type & parser,
const paracel::str_type & pattern = "fmap",
bool mix_flag = false) {
if(pattern == "fset") {
mix_flag = true;
}
// TODO: check pattern
// load lines
paracel::loader<T> ld(fn, worker_comm, parser, pattern, mix_flag);
// 并行加载,fixload 里面有一个all2all交换
paracel::list_type<paracel::str_type> lines = ld.fixload();
paracel_sync(); //这里进行同步,确保所有worker都完成加载
// create graph
ld.create_graph(lines, grp); // 此时才开始建立图
set_decomp_info(pattern);
lines.resize(0); lines.shrink_to_fit(); paracel::cheat_to_os();
}
4.3 加载文件
Paracel 的数据(模型),可能由多个数据文件构成,因此可以进行并行加载:
- 首先,依据文件列表和world size来分区,确保多个加载的worker之间不会出现workload不均衡的情况
- 其次,调用 structure_load 来做并行加载,和pytorch 暗合。
paracel::list_type<paracel::str_type> fixload() {
paracel::scheduler scheduler(m_comm, pattern, mix);
auto fname_lst = paracel::expand(filenames); //文件名字列表
// 依据文件列表和world size来分区,确保多个加载的worker之间不会出现workload不均衡的情况
paracel::partition partition_obj(fname_lst,
m_comm.get_size(),
pattern);
partition_obj.files_partition();
// parallel loading lines 此时才并行加载
auto linelst = scheduler.structure_load(partition_obj);
m_comm.synchronize();
if(m_comm.get_rank() == 0) std::cout << "lines got" << std::endl;
return linelst;
}
4.3.1 分区
于是就涉及到了一个问题,假如有6个worker,12个文件,那么每个worker怎么做到并行加载呢?
可能有同学会说:每个worker 加载两个文件。但是这种情况只适用于文件大小基本一致的情况,如果文件大小不一致,比如一个文件15000行,一个文件50行,一个文件20000行.....,那么就会造成worker的 load 不均衡,导致无法达到并行加载的效果。
所以需要按照所有文件的总行数进行分配。比如12个文件一共120000行,则每个worker负责加载10000行。
第一个worker可能负责加载第一个文件的10000行,第二个worker负责加载第一个文件的后5000行 和第二个文件的50行,第三个文件的 xxx 行.....
4.3.2 分区定义
我们看看分区是如何定义的:
namelst :是模型文件或者数据文件名字列表。
slst 其中第 i 个元素是第 i 个分区的起始行数。
elst : 第 i 个元素是第 i 个分区的终止行数。
np : 是所有worker个数。
displs :第 i 个元素是第 i 个文件在所有文件行数的起始行数。比如:第一个文件5行,第二个文件6行,第三个文件6行,则displs[0] = 0,displs[1] = 5,displs[2] = 11 ...
具体如下:
class partition {
public:
partition(paracel::list_type<paracel::str_type> namelst_in,
int np_in, paracel::str_type pattern_in)
: namelst(namelst_in), np(np_in), pattern(pattern_in) {}
private:
paracel::list_type<paracel::str_type> namelst;
int np; // world size
paracel::str_type pattern;
paracel::list_type<long> slst, elst, displs;
}; // class partition
4.3.3 均衡分区
目的就是计算所有文件的总行数,然后在各个worker之中进行均衡分配。
const int BLK_SZ = 32;
void files_partition(int blk_sz = paracel::BLK_SZ) {
if(pattern == "linesplit" || pattern == "fvec") {
blk_sz = 1;
}
slst.resize(0);
elst.resize(0);
displs.resize(0);
displs.resize(namelst.size() + 1, 0); // 扩展为文件个数
for(size_t i = 0; i < displs.size() - 1; ++i) {
std::ifstream f(namelst[i], std::ios::ate); // ate作用是写入的数据被加入到文件末尾
long tmp = f.tellg(); // 得到某个文件的行数
f.close();
displs[i + 1] = displs[i] + tmp; // 计算每个文件在总行数中的位置
}
long sz = displs.back(); //得到所有文件的总行数
int nbk = np * blk_sz; // 每个worker负责的范围
long bk_sz = sz / static_cast<long>(nbk); //每个partition的大小
long s, e;
for(int i = 0; i < nbk; ++i) { // nbk是每个worker负责的范围,其中每个范围是s, e,s和e之间大小是BLK_SZ。
s = static_cast<long>(i) * bk_sz; // 加载起始行
if(i == nbk - 1) {
e = sz;
} else {
e = (i + 1) * bk_sz; // 加载终止行
}
assert(s < e);
slst.push_back(s); //插入起始行
elst.push_back(e); //插入终止行
}
}
4.4 并行加载
回忆一下前面的代码,当我们用分区做负载均衡之后,就可以用scheduler实施并行加载:
partition_obj.files_partition();
// parallel loading lines 此时才并行加载
auto linelst = scheduler.structure_load(partition_obj);
scheduler可以认为是调度器,负责调度多个进程并行加载。
比如某worker,rank = 2, 则依据自己的rank来计算,得到本worker加载的起始,终止位置是:st = 64, en = 96。然后使用 files_load_lines_impl 具体加载。
paracel::list_type<paracel::str_type>
scheduler::structure_load(partition & partition_obj) {
paracel::list_type<paracel::str_type> result;
int blk_sz = paracel::BLK_SZ;
if(pattern == "fvec" || pattern == "linesplit") {
blk_sz = 1;
}
int st = m_comm.get_rank() * blk_sz; // 依据自己的rank来计算,看看自己这个进程从哪里加载。
int en = (m_comm.get_rank() + 1) * blk_sz; // 加载到哪里结束
auto slst = partition_obj.get_start_list();
auto elst = partition_obj.get_end_list();
for(int i = st; i < en; ++i) { // 遍历 64 ~ 96
// 去找 slst[64 ~ 96], elst[64 ~ 96]的来逐一加载
auto lines = partition_obj.files_load_lines_impl(slst[i], elst[i]); // 自己应该加载什么
result.insert(result.end(), lines.begin(), lines.end());
}
return result;
}
files_load_lines_impl完成了对具体文件的加载功能。
template <class F>
void files_load_lines_impl(long st, long en, F & func) {
// to locate files index to load from
int fst = 0;
int fen = 0;
long offset;
// 找到st, en分别属于哪个文件,即在 displs 的位置,找到哪些files
for(size_t i = 0; i < namelst.size(); ++i) {
if(st >= displs[i]) {
fst = i; // st所在文件的idx
}
if(en > displs[i + 1]) {
fen = i + 1; // en所在文件的idx
}
}
assert(fst <= fen);
bool flag = false;
// load from files
for(auto fi = fst; fi < fen + 1; ++fi) { // 遍历加载 fst, fen之间的文件
if(flag) {
offset = 0;
} else {
offset = st - displs[fi];
}
assert(offset >= 0);
std::ifstream f(namelst[fi]); // 加载某个file
// 依据文件行数,找到对应在哪个文件之中,然后加载
if(offset) {
f.seekg(offset - 1);
paracel::str_type l;
std::getline(f, l);
offset += l.size();
}
if(fi == fen) {
while(offset + displs[fi] < en) {
paracel::str_type l;
std::getline(f, l);
offset += l.size() + 1;
func(l);
}
} else {
flag = true;
while(1) {
paracel::str_type l;
std::getline(f, l);
if(l.size() == 0) {
break;
}
func(l);
}
}
f.close();
} // end of for
}
4.5 建立图
加载完成之后,会调用create_graph完成对图的构建。
void create_graph(paracel::list_type<paracel::str_type> & linelst,
paracel::bigraph<paracel::default_id_type> & grp) {
paracel::scheduler scheduler(m_comm, pattern, mix);
// hash lines into slotslst,每个worker构建自己负责的部分
paracel::list_type<paracel::list_type<paracel::compact_triple_type> > result;
scheduler.lines_organize(linelst,
parserfunc,
result);
linelst.resize(0); linelst.shrink_to_fit(); paracel::cheat_to_os();
m_comm.synchronize();
// alltoall exchange,让每个worker都拥有全部的数据
paracel::list_type<paracel::compact_triple_type> stf;
scheduler.exchange(result, stf);
result.resize(0); result.shrink_to_fit(); paracel::cheat_to_os();
m_comm.synchronize();
for(auto & tpl : stf) {
grp.add_edge(std::get<0>(tpl),
std::get<1>(tpl),
std::get<2>(tpl));
}
stf.resize(0); stf.shrink_to_fit(); paracel::cheat_to_os();
}
在构建过程中,使用lines_organize完成了对具体数据行的处理,具体就是依据文件中行的格式来进行解析,比如文件类型是fset?还是 fsv?还是 bfs 等,针对每种格式进行不同的处理。
template <class F = std::function< paracel::list_type<paracel::str_type>(paracel::str_type) > >
listlistriple_type
lines_organize(const paracel::list_type<paracel::str_type> & lines,
F && parser_func = default_parser) {
listlistriple_type line_slot_lst(m_comm.get_size());
paracel::str_type delimiter("[:| ]*");
for(auto & line : lines) {
auto stf = parser_func(line);
if(stf.size() == 2) {
// bfs or part of fset case
// ['a', 'b'] or ['a', 'b:0.2']
auto tmp = paracel::str_split(stf[1], delimiter);
if(tmp.size() == 1) {
paracel::triple_type tpl(stf[0], stf[1], 1.);
line_slot_lst[h(stf[0], stf[1], npx, npy)].push_back(tpl);
} else {
paracel::triple_type tpl(stf[0], tmp[0], std::stod(tmp[1]));
line_slot_lst[h(stf[0], tmp[0], npx, npy)].push_back(tpl);
}
} else if(mix) {
// fset case
// ['a', 'b', 'c'] or ['a', 'b|0.2', 'c|0.4']
// but ['a', '0.2', '0.4'] is not supported here
for(paracel::default_id_type i = 1; i < stf.size(); ++i) {
auto item = stf[i];
auto tmp = paracel::str_split(item, delimiter);
if(tmp.size() == 1) {
paracel::triple_type tpl(stf[0], item, 1.);
line_slot_lst[h(stf[0], item, npx, npy)].push_back(tpl);
} else {
paracel::triple_type tpl(stf[0], tmp[0], std::stod(tmp[1]));
line_slot_lst[h(stf[0], tmp[0], npx, npy)].push_back(tpl);
}
} // end of for
} else {
// fsv case
paracel::triple_type tpl(stf[0], stf[1], std::stod(stf[2]));
line_slot_lst[h(stf[0], stf[1], npx, npy)].push_back(tpl);
} // end of if
} // end of for
return line_slot_lst;
}
0x05 总结
现在归纳下总体逻辑如下,我们假设有两个workers对若干文件进行并行加载。最终每个worker都把数据和模型加载进入自己的进程。
+------------------------------------------------------------------------------------------------------------------------------------------------------+
| worker 1 +------------------+ |
| | partition | +-----------------+ |
| | | 3 structure_load | scheduler | |
| | slst +---------------------------> | | 5 6 8 |
| 1 fixload | | | +----> paracel_sync +-----> create_graph +----> lines_organize |
| +-------------> | elst | <---------------------------+ | |
| | | 4 files_load_lines_impl +-----------------+ ^ ^ |
| | displs | | | |
| | | | | |
| +------------------+ | | |
| | | |
| ^ | | |
| | | | |
| |2 files_partition | | |
+------------------------------------------------------------------------------------------------------------------------------------------------------+
| | |
+------------------------------+ | |
| | | | |
| | | | |
+----+----+ +---+----+ +----+---+ | 7 +
| File 1 | | File 2 | | File n | | scheduler.exchange
+----+----+ +---+----+ +----+---+ | +
| | | | |
| | | | |
+------------------------------+ | |
| | |
+------------------------------------------------------------------------------------------------------------------------------------------------------+
| worker 2 |2 files_partition | | |
| v | | |
| | | |
| +-------------------+ | | |
| | partition | | | |
| | | +------------------+ | | |
| 1 fixload | slst | 3 structure_load | scheduler | v v |
| +-------------> | +------------------------> | | 8 |
| | elst | | +----> paracel_sync +-----> create_graph +-----> lines_organize |
| | | <-------------------------+ | 5 6 |
| | displs | 4 files_load_lines_impl +------------------+ |
| | | |
| +-------------------+ |
+------------------------------------------------------------------------------------------------------------------------------------------------------+
手机如下:

至此,Paracel分析完毕,我们下一篇开始介绍 GPipe,敬请期待。
0xFF 参考
卷积神经网络的并行化模型--One weird trick for parallelizing convolutional neural networks
PyTorch 源码解读之 torch.utils.data:解析数据处理全流程
pytorch(分布式)数据并行个人实践总结——DataParallel/DistributedDataParallel
最新文章
- 解决win7系统重启后ip丢失问题,即每次电脑重启都要重新设置ip地址,重启后ip地址没了
- Android随笔之——Android ADB详解
- 建模分析之机器学习算法(附python&R代码)
- SQL 行转列和列转行2
- C#微信开发之旅(二):基础类之HttpClientHelper(更新:SSL安全策略)
- CXF支持 SOAP1.1 SOAP1.2协议
- iOS 开发者必知的 75 个工具(译文)
- div隐藏
- 【CentOS】Eclipse插件egit使用
- ArryList vs LinkedList
- angularjs应用骨架
- eclipse中show whitespace characters显示代码空格,TAB,回车 导致代码乱恶心
- 4G时代来临,运营商为谁搭台献唱?
- fedora 18 源码编译 android 4.0.1
- wpf 9张图片的连连看
- JavaScript 轻松创建级联函数
- 四张图揭秘中国AI人才现状
- BitmapImage 读取内存流和显示图片
- Alpha冲刺——Day1
- Oracle完全复制表结构的存储过程