【Spark】Day01-入门、模块组成、4种运行模式详解及配置、案例实操(spark分析过程)
一、概述
1、概念
基于内存的大数据分析计算引擎
2、特点
快速、通用、可融合性
3、Spark内置模块【腾讯8000台spark集群】
Spark运行在集群管理器(Cluster Manager)上,支持3种集群管理器:Yarn、Standalone(脱机,Spark自带)、Apache Mesos(国外)
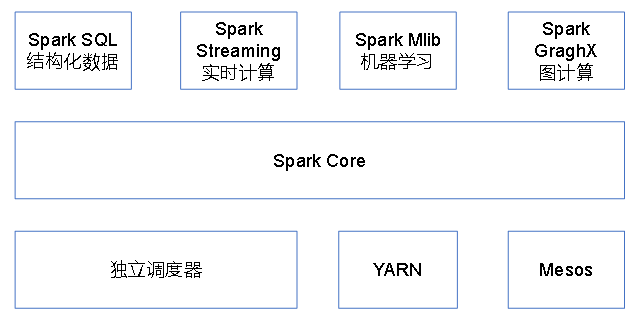
Spark Core:基本功能(任务调度、内存管理、错误恢复、与存储系统交互)、弹性Resilient 分布式数据集RDD的API
Spark SQl:操作结构化数据的程序包,数据查询,并支持多种数据源(Hive 表、Parquet 以及 JSON 等)
Spark Streaming:流式计算,提供用来操作数据流的 API,与Core中的RDD API高度对应
Spark MLlib:机器学习库,以及模型评估、数据导入等功能
Spark GraphX :图计算和挖掘
二、Spark运行模式:单机模式与集群模式
1、概念
(1)分类
Local、Standalone(自带的任务调度)、YARN、Mesos
(2)核心概念
|
Term |
Meaning |
|
Application |
User program built on Spark. Consists of a driver program and executors on the cluster. (构建于 Spark 之上的应用程序. 包含驱动程序和运行在集群上的执行器) |
|
Driver program 驱动程序 |
负责把并行操作发布到集群上,SparkContext对象相当于一个到 Spark 集群的连接(直接与工作节点相连,并受集群管理器的管理) |
|
Cluster manager 集群管理器 |
An external service for acquiring resources on the cluster (e.g. standalone manager, Mesos, YARN) |
|
Deploy mode 运行模式 |
Distinguishes where the driver process runs. In “cluster” mode, the framework launches the driver inside of the cluster. In “client” mode, the submitter launches the driver outside of the cluster. |
|
Worker node |
特有资源调度系统的 Slave,类似于 Yarn 框架中的 NodeManager,功能包括:注册到maser、发送心跳、执行task |
|
Executor 执行器 |
执行计算和为应用程序存储数据,SparkContext对象发送程序代码以及任务到执行器开始执行程序 |
|
Task |
A unit of work that will be sent to one executor |
|
Job |
A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g. save, collect); you’ll see this term used in the driver’s logs. |
|
Stage |
Each job gets divided into smaller sets of tasks called stages that depend on each other (similar to the map and reduce stages in MapReduce); you’ll see this term used in the driver’s logs. |
2、Local模式
(1)使用方式
发布应用程序
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
使用run-examples来运行:bin/run-example SparkPi 100
使用shell:bin/spark-shell(可以通过web查看运行情况)
(2)提交流程
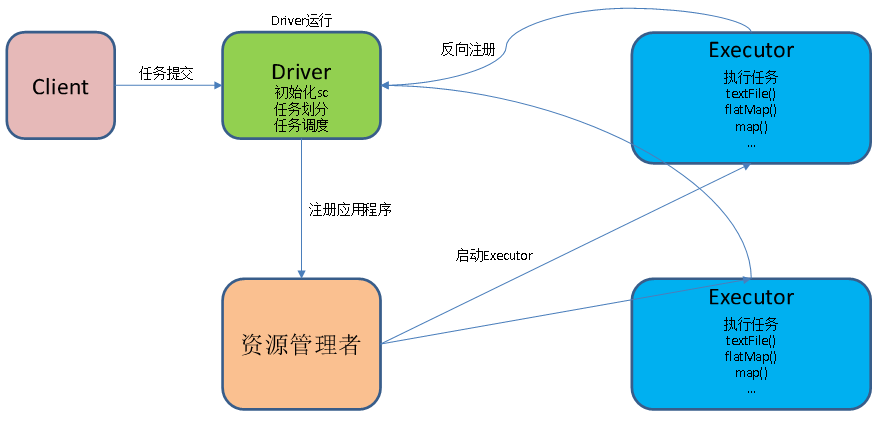
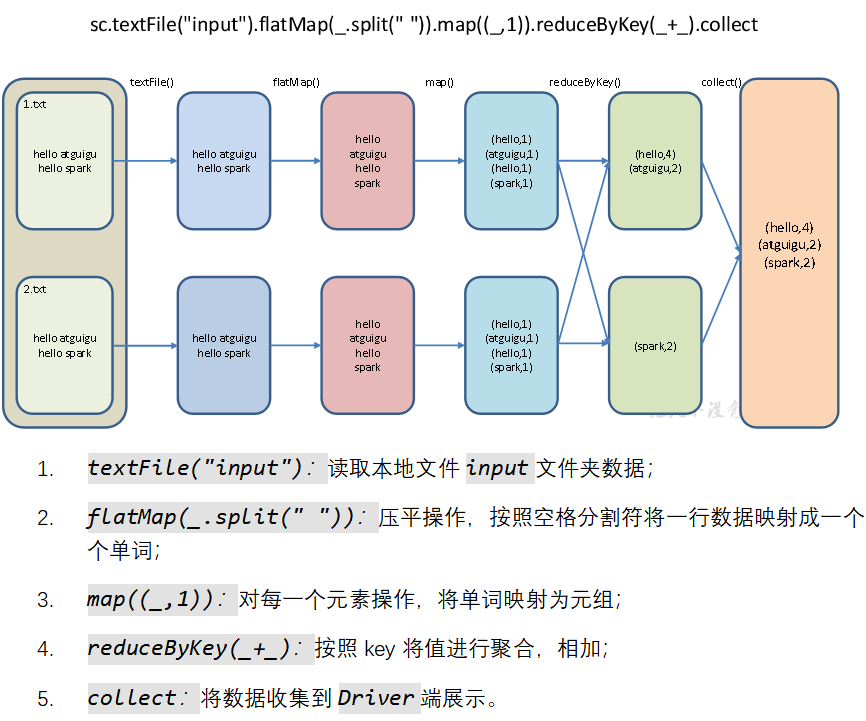
(3)数据流程
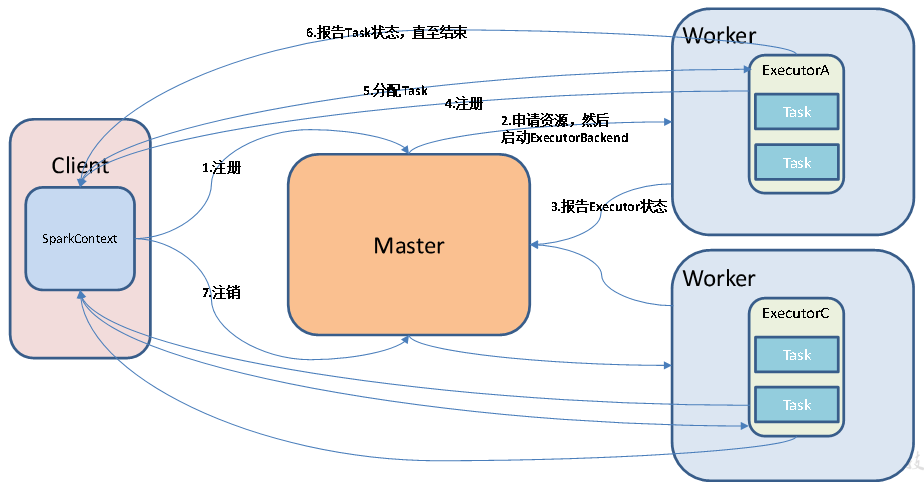
3、Standalone模式
(1)工作模式图解
由master管理
(2)配置
由 Master + Slave 构成的 Spark 集群
修改 slaves 文件,分发启动sbin/start-all.sh
查看集群运行情况:http://hadoop201:8080
运行计算程序bin/spark-submit
启动 Spark-shell:bin/spark-shell --master xxxx
(3)配置Spark任务历史服务器
spark-defaults.conf配置文件中,允许记录日志
spark-env.sh中配置历史服务器端口和日志在hdfs上的目录
分发配置,启动hdfs
启动历史服务器sbin/start-history-server.sh
启动任务并查看
(4)HA 配置(为 Mater 配置)
master单一,存在单点故障问题
方式:启动多个,包含active状态和standby状态
spark-env.sh添加zk配置,移除原有master
分发启动zk,启动全部节点sbin/start-all.sh
杀死master进程,在8080端口查看master的状态
重新启动sbin/start-master.sh
4、Yarn模式:客户端直接连接yarn,无需额外构建spark集群
(1)概述
client 和 cluster 两种模式,区别在于:Driver 程序的运行节点不同
cluster:Driver程序运行在由 RM(ResourceManager)启动的 AM(AplicationMaster)
由RM管理
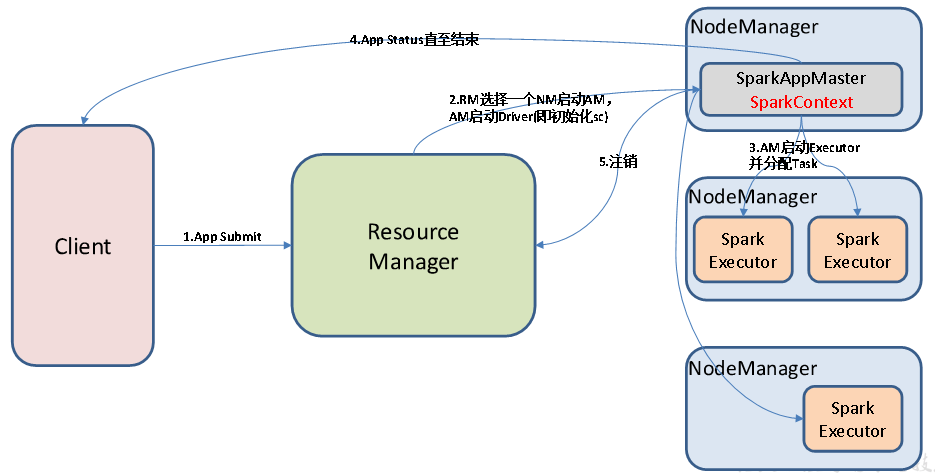
(2)Yarn模式配置
修改yarn-site.xml,避免杀死nm进程
修改spark-evn.sh,去掉 master 的 HA 配置
执行程序并在8088端口进行查看
在spark-default.conf中配置历史服务器
5、Mesos 模式:客户端直接连接 Mesos;不需要额外构建 Spark 集群
6、比较
|
模式 |
Spark安装机器数 |
需启动的进程 |
所属者 |
|
Local |
1 |
无 |
Spark |
|
Standalone |
多台 |
Master及Worker |
Spark |
|
Yarn |
1 |
Yarn及HDFS |
Hadoop |
三、WordCount案例实操
1、概述
利用 Maven 来管理 jar 包的依赖
2、步骤
创建 maven 项目, 导入依赖
编写 WordCount 程序(创建WordCount.scala)
3、测试
(1)打包到 Linux 测试
bin/spark-submit --class day01.WordCount --master yarn input/spark_test-1.0-SNAPSHOT.jar
查询结果
hadoop fs -cat /output/*
(2)idea 本地直接提交应用(使用local模式执行)
package day01
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
// 1. 创建 SparkConf对象, 并设置 App名字, 并设置为 local 模式
val conf: SparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]")
// 2. 创建SparkContext对象
val sc = new SparkContext(conf)
// 3. 使用sc创建RDD并执行相应的transformation和action
val wordAndCount: Array[(String, Int)] = sc.textFile(ClassLoader.getSystemResource("words.txt").getPath)
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.collect()
wordAndCount.foreach(println)
// 4. 关闭连接
sc.stop()
}
}
最新文章
- 七个结构模式之适配器模式(Adapter Pattern)
- CSDN数据库被爆 统计CSDN用户都喜欢哪些密码
- XCODE中的蓝色文件夹与黄色文件夹
- 1分钟去除word文档编辑限制密码
- MAC 重置MySQL root 密码
- 图片生成操作属性导致WP内存溢出解决办法
- 《使用Win32DiskImager安装Ubuntu16.04》
- 一个很奇特的异常 tmpFile.renameTo(classFile) failed
- Bootstrap 常用组件汇总
- 【转】地址空间、内核空间、IO地址空间
- 探索C++对象模型
- gitlab 本地 定时备份
- ●BZOJ 2049 [Sdoi2008]Cave洞穴勘测
- Python核心编程(网络编程)
- 暗之的锁链 [COGS2434] [树上差分]
- 解决安装xcode后git使用报错的问题
- 118. Pascal's Triangle (java)
- PowerDesigner最基础的使用方法入门学习(一)
- Delphi取UTC时间秒
- c#录音和放音,超简单!不用DirectX