梯度提升树 Gradient Boosting Decision Tree
Adaboost + CART
用 CART 决策树来作为 Adaboost 的基础学习器

但是问题在于,需要把决策树改成能接收带权样本输入的版本。(need: weighted DTree(D, u(t)) )
这样可能有点麻烦,有没有简单点的办法?尽量不碰基础学习器内部,想办法在外面把数据送进去的时候做处理,能等价于给输入样本权重。(boostrapping)

例如权重 u 的占比是30%的样本,对应的 sampling 的概率就设定为 0.3。
每一个基础学习器在整体模型中的重要性还是用 αt 来衡量(gt 在 G 中的系数)。另外,这个方法中仍然是 boosting, CART 一定不能太强(剪枝比较多、简单点就限制树高度;训练每棵树都只用一部分训练数据)

极端情况,限制树的高度只有1,那就直接退化成 decision stump ,也就不用做 sampling 了(因为几乎不会只用 stump 就能让 error rate = 0)

GBDT
梯度提升树(GBDT)也是一种前向分步算法,但基础模型限定了使用 CART 回归树。在学习过程中,第 t 轮迭代的目标是找到一个 CART 回归树 gt(x) 让本轮的损失函数 L(y, Gt(x)) = L(y, Gt-1(x) + gt(x)) 尽量小。
从 Adaboost 到 general boosting
负梯度拟合的优势就是可以在通用框架下拟合各种损失误差,这样分类回归都能做。在 ensemble https://www.cnblogs.com/chaojunwang-ml/p/11208164.html 分析过,这里再回顾一遍。
统一每次更新样本权重的形式(gt-1(x) 正确分类的样本权重减小,错误分类的样本权重增加)

那么根据递推公式,unT+1 可以从 un1 推得,而表达式中正好可以发现 G(x) 的 logit(voting score)。

而 yn * voting score 可以理解为点到分割平面的一种距离衡量,类似于 SVM 中的 margin,只不过没有归一化。而模型的训练目标就是想要让 margin 正的越大越好,等价于让 unT+1 越小越好。也就是说,adaboost 中所有样本的 un 之和会随着时间步推移越来越小(让每一个点的 margin 都越来越正、越来越大)。

这样就可以看出 adaboost 整体模型的要最小化的目标函数,是所有时间步的所有样本权重之和,即0/1损失函数的upper bound(指数损失函数)。
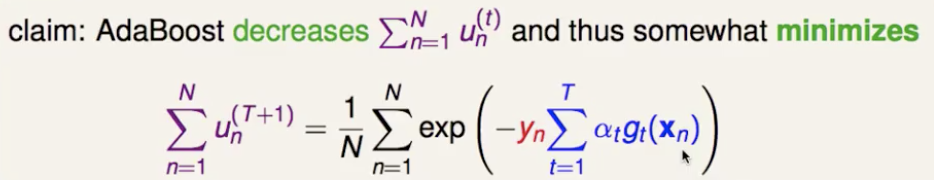

就用梯度下降(泰勒一阶展开)来实现这个最小化(不同的是,这里要求 loss 函数对 gt(x) 函数的梯度,approximate functional gradient)。把1/N拿进去,紫色部分凑成 unt ,对剩下的exp部分用泰勒公式一阶逼近,整理得到最终要对 h 求梯度的目标函数。

那就来看一下,发现最小化整体模型的目标函数,就等价于最小化 Einu(t) ,就是要优化基础分类器(也就是说,adaboost中前向分步训练基础分类器,其实正是在为整体模型的梯度下降优化找最好的gt(x) )


再来就是要确定学习率,能不能每步都找到一个最好的学习率(短期内比固定的学习率下降的快)?steepest descent:loss 对其求导并另为0。得到的最好的学习率,正是 adaboost 中的 αt
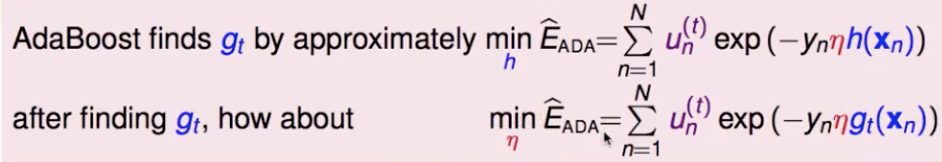

从梯度下降的角度再次总结 adaboost 做分类

gradient boosting
负梯度拟合的扩展,不只用指数损失函数,用其他的损失函数(符合平滑条件)也可以。从目前已经达到的 G(xn) ,向某一个方向(h(xn))走一小步(η),使得新的 logit 与给定的 yn 之间的某种 error 变小。

以平方误差举例,error = (s-y)2

如果在某处往某个方向走了一小步,就要乘上 gradient 在那个地方的分量(error 对 s 偏微分,在sn 处取值)。然后就是找一个 h,让下面式子的第二项越小越好(第一项与h无关)。直接的想法是:如果 s-y 是正的,就给一个负的 h ;如果 s-y 是负的,就给一个正的 h 。那么就让 h 取到 s-y 的负方向。
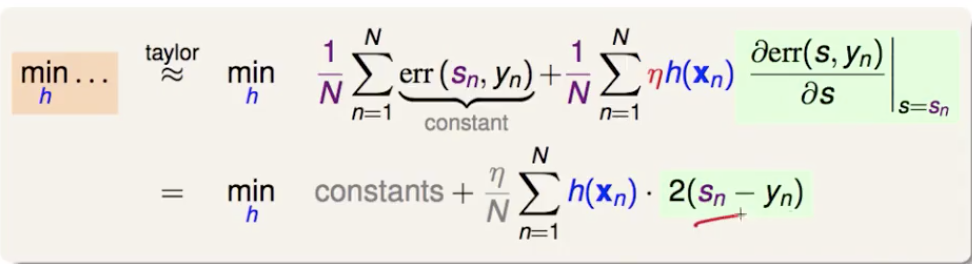
但 h 的大小呢?如果不加约束,h(xn) = - ∞ * (sn-yn) ,可是我们这里找 h 只是要找一个方向,所以步长靠 η 决定。加一个正则化惩罚项即可。然后凑一个 (h(xn) - (yn - sn))2 出来,配上一个和 h 无关的常数项。要最小化这个式子,就是要令 h(xn) 和 (yn - sn) 之间的均方误差最小,那就是以残差 residual 为目标训练一个回归器。

然后决定 η 的大小,单变量最优化问题。但这里除了求偏微分令其等于0,还有一种简洁的求法。把 gt(xn) 看成是feature,residual 看成简单线性回归的目标, 求这个一维的权重。


optimal η 的解为

加入 CART 作为 base learner,总结一下 GBDT

关于 GBDT 做分类的详解:https://www.cnblogs.com/pinard/p/6140514.html
最新文章
- 【mongo】drop不释放磁盘空间
- NET中的规范标准注释(二) -- 创建帮助文档入门篇
- python 练习 26
- ios基础篇(二)——UIImageView的常见用法
- 通过GetManifestResourceStream加载文件出现错误提示“null值”对于“stream”无效[转]
- iOS_根据文字字数动态确定Label宽高
- Swift初体验 (一)
- WEB前端组件思想【日历】
- JS模式--状态模式(状态机)
- 动态语言的灵活性是把双刃剑 -- 以Python语言为例
- lnmp1.3 配置pathinfo---thinkphp3.2 亲测有效
- 使用C#开发C/S框架高级版添加新项目实例
- 查看linux中的TCP连接数
- RabbitMQ中客户端的Channel类里各方法释义
- mysql存储过程的学习(mysql提高执行效率之进阶过程)
- 解决Windows 系统下Chrome中有多个音频界面时 无法静音单个Tab界面的问题
- mint-ui Toast icon 图标
- WPS for Linux
- 6-1 平衡的括号 uva673
- Codeforces 923 B. Producing Snow
热门文章
- 面经手册 · 第7篇《ArrayList也这么多知识?一个指定位置插入就把谢飞机面晕了!》
- 焦大:SEO重思录(上)收录量和收录率的重新定位
- 华为云服务器安装hadoop2.7.5
- 封装Vue Element的dialog弹窗组件
- Android开发之将图片文件转化为字节数组字符串,并对其进行Base64编码处理
- java 区块
- [BUUOJ记录] [ACTF2020 新生赛]BackupFile、Exec
- Linq 下的扩展方法太少了,您期待的 MoreLinq 来啦
- Java并发编程:volatile关键字解析【转载】
- Python算法题:有100只大、中、小骆驼,100框土豆,一只大骆驼可以背3框,中骆驼可以背俩框,小骆驼两只背一筐,问大中小各有多少只骆驼?