常用文本处理命令 & 三剑客之 sed
今日内容
- 文本处理命令
- Linux 三剑客之 sed
内容详细
文本处理命令
1、sort : 文件内容排序
默认按照文件隔行内容的第一个字符大小进行排序(默认是升序)
默认输出文本结果
sort [参数] [操作对象]
[root@localhost tmp]# sort test
232
34
454
455
[root@localhost tmp]# sort test2
a
A
aa
AA
Ab
ba
Bb
# 如果是英文字符,则是按照 ascii 表的大小比较,且同字母的大小写会先进行比较,字母相同的位数会先比。
参数:
-n 依照数值的大小排序
[root@localhost tmp]# sort -n test
34
89
89
232
454
# 按照数值的大小比较
-r 以相反的顺序来排序
[root@localhost tmp]# sort -r test
909
89
89
677
# 与 n 比较数字大小配合使用
[root@localhost tmp]# sort -rn test
909
677
576
455
455
454
232
89
-k 以某列进行排序
# 以第二列第一个数字的大小进行升序排序
[root@localhost tmp]# sort -k2 test
909 235
576 4323
34 454
455 4667
# 与 n、r 配合使用,用数值大小进行倒序(降序)进行排序
[root@localhost tmp]# sort -k2nr test
454 97867
89 7887
232 6578
89 5456
-t 指定分割符,默认是以空格为分隔符
默认不能用 tab 符来分隔,先进行转义 : -t$'\t'
[root@localhost tmp]# sort -t$'\t' test
232 6578
34 454
454 97867
455 4667
2、uniq :检查和删除文本中重复出现的行列
用于检查和删除文本中重复出现的行列,注意,只有相邻并且重复的内容才会被识别出来,一般与 sort 命令结合使用
uniq [参数] [被操作对象]
[root@localhost tmp]# cat test3
456
456
867
867
867
456
456
9877
9877
[root@localhost tmp]# uniq test3
456
867
456
9877
# 由此可见:只有相邻并且重复的内容才会被识别出来,
# 解决 : 与 sort 命令结合使用,先排序才去重
参数:
-c : 每列旁边显示该行重复出现的次数
sort -nr test3 | uniq -c
先用 sort 进行数值降序排序,再进行去重并统计每行重复次数
[root@localhost tmp]# sort -nr test3 | uniq -c
3 9877
4 867
6 456
-d : 仅显示重复出现的行列
sort -nr test3 | uniq -d
先进行排序,再显示重复出行的行列
[root@localhost tmp]# sort -nr test3 | uniq -d
9877
867
456
-u : 仅显示出现一次的行列
uniq -u test3
[root@localhost tmp]# uniq -u test3
abcde
fghij
3、cut 显示行中指定部分,删除文件指定字段
cut命令可以从一个文本文件或者文本流中提取文本列
(切割必须指定字节、字符或字段的列表)
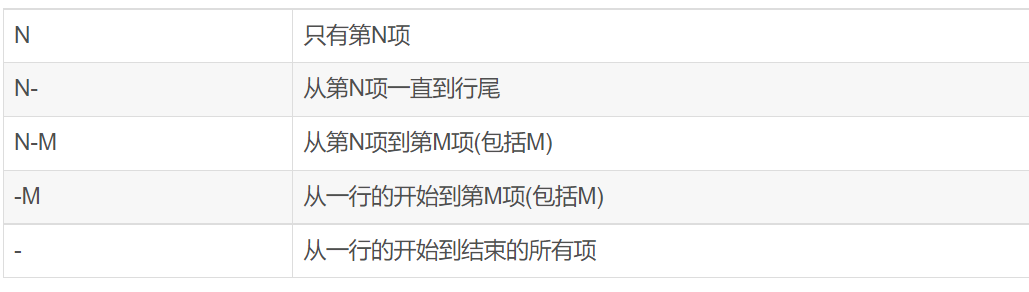
cut -f list [-d delim][-s] [file ...]
[root@localhost tmp]# cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
[root@localhost ~]# cut -f1 -d':' /etc/passwd
root
bin
daemon
adm
lp
sync
shutdown
# passwd 用户信息文件内容以 : 为分隔符分隔为多列,顺利地
参数:
-d :指定字段的分隔符,默认的字段分隔符为"TAB"
cut -d':' /etc/passwd
将 passwd 中的内容以冒号 ':' 为分割符分割成好几列
-f : 显示指定字段的内容
cut -f1 /etc/passwd
取出 passwd 中分列之后的第一个字段的所有内容
4、tr : 替换或删除命令
可以将 tr 看作为 sed的(极其)简化的变体:
它可以用一个字符来替换另一个字符
可以完全除去一些字符
也可以用它来除去重复字符
替换字符
[root@localhost tmp]# cat test3
456
456
456
867
867
# 把 456 替换成 son
注意:替换是一个一个字符相对位置替换的,也就是 s 替换了 4, o 替换了 5, n 替换了 6
[root@localhost tmp]# cat test3 | tr '456' 'son'
son
son
son
8n7
8n7
-d : 删除字符
cat test3 | tr -d '123'
[root@localhost tmp]# cat test3 | tr -d '456'
87
87
# 成功删除 456
5、wc : 统计,计算数字
默认会统计文件的 行数(l)、单词个数(w)、文件大小(c)
[root@localhost tmp]# wc test3
15 17 75 test3
行数 单词数 文件大小
-l : 统计文件的行数
[root@localhost tmp]# wc -l test3
15 test3
-w : 统计文件中单词的个数,默认以空白字符做为分隔符
[root@localhost tmp]# wc -w test3
17 test3
-c : 统计文件的Bytes数
[root@localhost tmp]# wc -c test3
75 test3
Linux 三剑客之 sed
三剑客:
grep : 过滤文件
sed : 更改文件
awk : 处理文件
sed是linux中的流媒体编辑器
1、语法格式
sed [参数] '处理规则' [操作对象]
2、参数
-e : 允许多项编辑
[root@localhost tmp]# cat 1.txt
heihei
eat tanyuan
wowowo
wowowowo
# 把 1.txt 文件第 1 行和第 3 行删除
[root@localhost tmp]# sed -e '1d' -e '3d' 1.txt
eat tanyuan
wowowowo
-n : 取消默认输出
# 打印第二行
[root@localhost tmp]# sed '2p' 1.txt
heihei
eat tanyuan
eat tanyuan < -- 多打印的一行
wowowo
wowowowo
# 取消其它的默认输出行
[root@localhost tmp]# sed -n '2p' 1.txt
eat tanyuan
-i : 就地编辑
就地编辑会把 指定打印 的内容直接编辑进文件里面去(正常使用 sed 的时候都只会在终端输出更改结果,不会直接写入文件)
删除效果也可以直接作用到文件中
就地编辑 : 把更改过的效果写入到文件里面去,真实修改
[root@localhost tmp]# cat 1.txt
heihei
eat tanyuan
wowowo
wowowowo
# 直接把打印的第二行内容写入了 1.txt 文件中
[root@localhost tmp]# sed -i '2p' 1.txt
[root@localhost tmp]# cat 1.txt
heihei
eat tanyuan
eat tanyuan
wowowo
wowowowo
-r : 支持拓展正则
-f : 指定 sed 匹配规则脚本文件
[root@localhost tmp]# cat 1.txt
heihei
eat tanyuan
wowowo
wowowowo
# 可以把复杂的正则表达式写入另一个脚本文件中,要使用正则表达式的时候可以用 -f 来调用脚本文件
vim role.
3、定位
d : sed的编辑模式 --> 删除
p : 打印
1、数字定位法
[root@localhost tmp]# cat -n test3
1 456
2 456
3 456
4 456
5 867
6 867
# 定位文件的第三行,删除 d
[root@localhost tmp]# cat -n test3 | sed '3d'
1 456
2 456 < -- 第三行被删除了
4 456
5 867
6 867
# 定位到内容第二和第四行,会删除内容的 3到4 行
[root@localhost tmp]# cat -n test3 | sed '2,4d'
1 456 < -- 第 2 到 第 4 行被删除了
5 867
6 867
2、正则定位法
把正则表达式写在 引号的 / / 内
在 grep 中,正则规则写在 单引号中,在 sed 里正则规则要写到 / / 符号里面,外加引号添加更改选项
[root@localhost tmp]# cat test3
456
456
867
867
# 删除以四开头的内容
[root@localhost tmp]# sed '/^4/d' test3
867
867
3、数字和正则定位法
[root@localhost tmp]# cat test3
456
456
456
456
867
867
# 删除第 2 行到 以 8 开头的内容
[root@localhost tmp]# sed '2,/^8/d' test3
456
867
4、正则正则定位法
[root@localhost tmp]# cat test3
456
456
456
867
867
867
867
456
# 把以 8 开头 到以 4 开头 的内容删除
[root@localhost tmp]# sed '/^8/,/^4/d' test3
456
456
456
456
4、sed 的编辑模式:
d : 删除
[root@localhost tmp]# cat -n test3
1 456
2 456
3 456
4 456
5 867
6 867
# 定位文件的第三行,删除 d
[root@localhost tmp]# cat -n test3 | sed '3d'
1 456
2 456 < -- 第三行被删除了
4 456
5 867
6 867
p : 打印
# 打印 1.txt 文件的第二行
[root@localhost tmp]# sed '2p' 1.txt
heihei
eat tanyuan
eat tanyuan < -- 打印出来的第二行
wowowo
wowowowo
a : 在当前行后添加一行或多行
# 在文本的第二行之后添加 内容
[root@localhost tmp]# cat -n test3 | sed '2alixiaoze i am sorry'
1 456
2 456
lixiaoze i am sorry
3 456
4 456
c : 用新文本修改(替换)当前行
# 把文本第二行内容替换成 c 后面的内容
[root@localhost tmp]# cat -n test3 | sed '2cxiaoze wo cuo le'
1 456
xiaoze wo cuo le
3 456
4 456
5 867
r : 在文件中读内容
# 1.txt 中的内容:
[root@localhost tmp]# cat 1.txt
xiaoze qing yuanliang
# forgive 中的内容:
[root@localhost tmp]# cat forgive
heihei
eat tanyuan
wo
# 把 1.txt 中所有内容读取到 forgive 文件内容的第二行下方
[root@localhost tmp]# sed '2r 1.txt' forgive
heihei
eat tanyuan
xiaoze qing yuanliang
wo
w : 将指定行写入文件
# 把 1.txt 中的第三行内容写入到 forgive 文件中去
[root@localhost tmp]# sed '3w forgive' 1.txt
[root@localhost tmp]# cat forgive
wo
y : 将字符转换成另一个字符
# 将 1.txt 文件第三行中的 wo 转换成 WO
[root@localhost tmp]# sed '3y/wo/WO/' 1.txt
heihei
eat tanyuan
WO
wo
i : 在当前行之前,插入文本(单独使用时)
# 在第二行之前,插入内容
[root@localhost tmp]# cat -n test3 | sed '2ixiaoze forgive me please~~'
1 456
xiaoze forgive me please~~
2 456
3 456
4 456
i : 忽略大小写(与s模式一起使用时)
# 把 1.txt 文件内容中全部字符 wo 转换成 HE, 全部执行,忽略大小写
[root@localhost tmp]# sed 's/wo/HEE/gi' 1.txt
heihei
eat tanyuan
HEEHEEHEE
HEEHEEHEEHEE
s : 将字符串转换成另一个字符串(每一行只替换一次)
[root@localhost tmp]# cat 1.txt
heihei
eat tanyuan
wowowo
wowowowo
# 把 1.txt 文件内容中每一行的第一个字符 wo 转换成 HE
sed 's/wo/HEE/' 1.txt
[root@localhost tmp]# sed 's/wo/HEE/' 1.txt
heihei
eat tanyuan
HEEwowo
HEEwowowo
g : 全部执行(一般配合 s 使用)
# 把 1.txt 文件内容中全部字符 wo 转换成 HE, 全部执行
[root@localhost tmp]# sed 's/wo/HEE/g' 1.txt
heihei
eat tanyuan
HEEHEEHEE
HEEHEEHEEHEE
最新文章
- 给hadoop新手的一封信:Hadoop入门自学及对就业的帮助
- box-shadow
- 【UOJ#33】【UR#2】树上GCD 有根树点分治 + 容斥原理 + 分块
- php-fpm进程关闭与重启脚本详解(转)
- Gradle使用指南
- JAVA基础知识之NIO.2——Path,Paths,Files
- 对IEnumerable<T>和IQueryable<T>的一点见解
- iOS 如何根据经纬度来定位位置
- Java 序列化的高级认识
- release下去除nslog宏
- linux gcc 和 g++ 编译
- 【转】改善C#程序的建议2:C#中dynamic的正确用法 空间
- CGContextRef一点用法
- Object.defineProperty 规则
- Qt tip 网络请求 QNetworkRequest QJason 处理 JSON
- CentOS7下解决yum install mysql-server 异常:No package mysql-server available.问题
- 前端笔记-javaScript-1
- backbone点滴
- Scrapy学习篇(三)之创建项目和Scrapy的安装
- Runtime 全方位装逼指南