【python爬虫】scrapy入门6-生成多个spider
2024-10-09 04:40:37
一个工程生产一个spider,也可以多个spider,比如一个爬文本,一个爬图片等
cd tutorial #自己创建的工程目录
scrapy genspider test1 test1.com
scrapy genspider test2 test2.com
用scrapy list查看三个(早期1个+最近2个)

进入spiders目录,看到生成两个爬虫文件
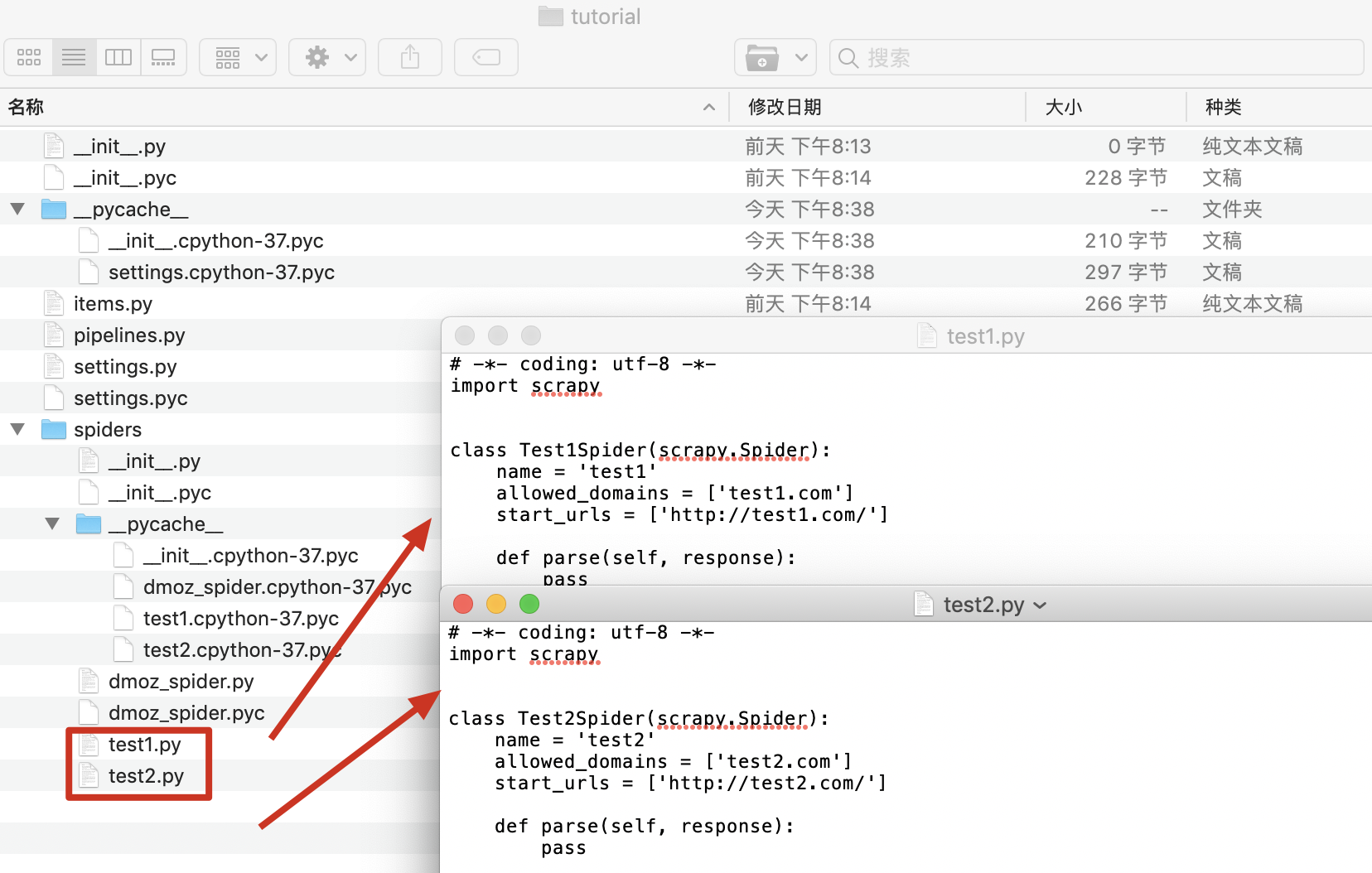
最新文章
- your password has expired.to log in you must change it
- 在<s:iterator>标签里给动态表格添加序号
- 10G整数文件中寻找中位数或者第K大数
- Oracle MySQL Server 拒绝服务漏洞
- linux串口驱动分析
- SOSP 文档 - Windows Azure 存储:具有强一致性的高可用性云存储服务
- Vmware虚拟机安装Ubuntu 16.04 LTS(长期支持)版本+VMware tools安装
- Html_Task4(知识点:水平居中+垂直居中/position/float/border-radius)
- JS中常见设计模式总结
- Kivy / Buildozer VM Ubuntu不能连接到网络的问题解决
- Android sdk下载找不到support library
- getfacl
- Linux环境部署
- 合并两个JsonArray
- wordpress使用七牛云加速
- Markdown基本语法规范
- windows Maven3.0 服务器配置搭建
- sam9260 闲鱼
- Maven项目整合SSH框架
- 软件工程作业 - 实现WC功能(java)