day21-Python运维开发基础(单个字符匹配 / 多字符匹配)
2024-09-02 08:19:50
1. 正则表达式(单个字符匹配)
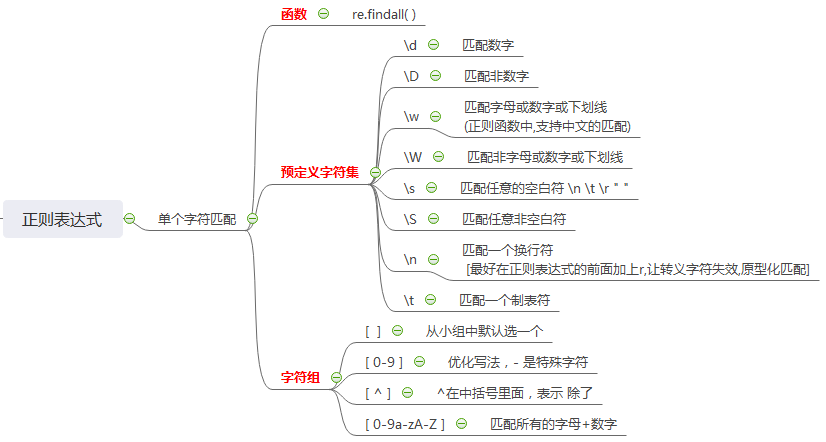
# ### 正则表达式 => 单个字符匹配
import re
"""
lst = re.findall(正则表达式,字符串)
""" # (1) 预定义字符集 # \d 匹配数字
strvar = "sadfasdf^*&^&*^&*^&*你好 神秘男孩 2400909()()"
lst = re.findall("\d",strvar)
print(lst) # \D 匹配非数字
strvar = "&&*sdfjklasjdkf_sdf',神秘女孩23423岁4234234"
lst = re.findall("\D",strvar)
print(lst) # \w 匹配字母或数字或下划线 (正则函数中,支持中文的匹配)
strvar = "uiui7887_王文&*&*"
lst = re.findall("\w",strvar)
print(lst) # \W 匹配非字母或数字或下划线
strvar = "uiui7887_王文&*&*"
lst = re.findall("\W",strvar)
print(lst) # \s 匹配任意的空白符 \n \t \r " "
strvar = " 周杰伦 "
lst = re.findall("\s",strvar)
print(lst) # \S 匹配任意非空白符
strvar = " sdf234 "
lst = re.findall("\S",strvar)
print(lst) # \n 匹配一个换行符 [最好在正则表达式的前面加上r,让转义字符失效,原型化匹配]
strvar = """
王文你真帅呀,我受不了
"""
lst = re.findall(r"\n",strvar)
print(lst) # \t 匹配一个制表符
lst = re.findall(r"\t",strvar)
print(lst) # (2) 字符组 从小组中默认选一个
lst = re.findall("[123]","")
print(lst) print(re.findall('a[abc]b','aab abb acb adb')) # aab abb acb
print(re.findall('a[0123456789]b','a1b a2b a3b acb ayb')) # a1b a2b a3b # 优化写法 0123456789 => 0-9 0到9 -是特殊字符 , 居右特殊含义
print(re.findall('a[0-9]b','a1b a2b a3b acb ayb')) # a1b a2b a3b print(re.findall('a[abcdefg]b','a1b a2b a3b acb ayb adb')) # acb adb # 优化写法 abcdefg a-g 26个小写字母 a-z
print(re.findall('a[a-z]b','a1b a2b a3b acb ayb adb')) # acb adb ayb print(re.findall('a[ABCDEFG]b','a1b a2b a3b aAb aDb aYb')) # aAb aDb # 优化写法 ABCDEFG A-G 26个大写字母A-Z
print(re.findall('a[A-Z]b','a1b a2b a3b aAb aDb aYb')) # aAb aDb aYb # 匹配所有的字母+数字
print(re.findall('a[0-9a-zA-Z]b','a-b aab aAb aWb aqba1b')) # aab aAb aWb aqb a1b # 优化写法 0-9a-zA-Z 0-z 范围变大 一些特殊符号也被包含进行了 , 不推荐使用
print(re.findall('a[0-z]b','a-b aab aAb aWb aqba@b')) # ['aab', 'aAb', 'aWb', 'aqb', 'a@b'] print(re.findall('a[0-9][*#/]b','a1/b a2b a29b a56b a456b')) # a1/b # ^ 出现在字符组中,代表除了 ,除了+-*/ 这个符号 都要
print(re.findall('a[^-+*/]b',"a%b ccaa*bda&bd")) # ['a%b', 'a&b'] # 匹配特殊符号 利用\ 让原来有意义的字符失效, 通过转义来实现匹配
lst = re.findall(r"a[\^\-]b","a^b a-b")
print(lst) # 匹配\
lst = re.findall(r"a\\b",r"a\b")
print(lst) # 显示\\
print(lst[0]) # 打印出来是一个\
正则表达式_单个字符匹配 示例代码
2. 正则表达式(多字符匹配)
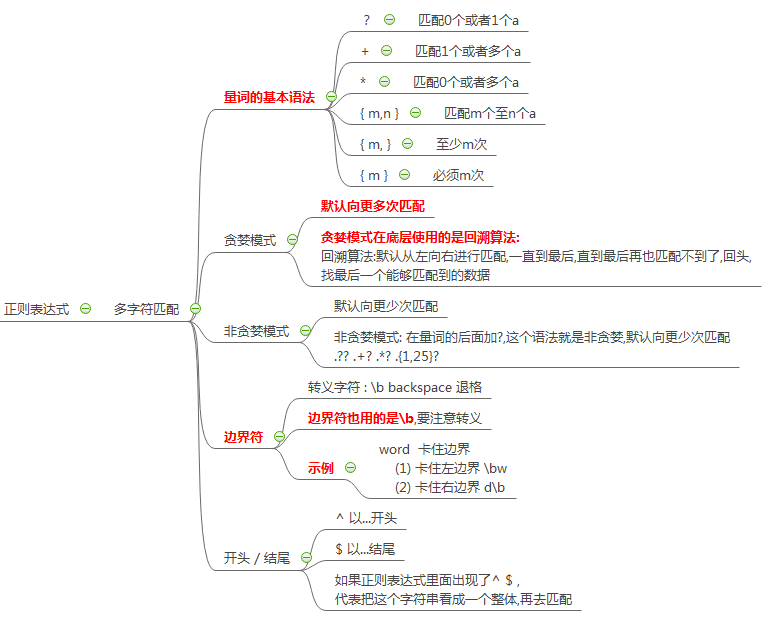
# ### 正则表达式 => 多个字符匹配 # (1) 量词基本语法
import re
'''1) ? 匹配0个或者1个a '''
print(re.findall('a?b','abbzab abb aab')) # ab b ab ab b ab '''2) + 匹配1个或者多个a '''
print(re.findall('a+b','b ab aaaaaab abb')) # ab aaaaaab ab '''3) * 匹配0个或者多个a '''
print(re.findall('a*b','b ab aaaaaab abbbbbbb')) # b ab aaaaaab ab b b b b b b '''4) {m,n} 匹配m个至n个a '''
"""1<= x <=3"""
print(re.findall('a{1,3}b','aaab ab aab abbb aaz aabb')) # aaab ab aab ab aab
# {m,} 至少m次
print(re.findall('a{2,}b','aaab ab aab abbb aaz aabb')) # aaab aab aab
# {m} 必须m次
print(re.findall('a{2}b','aaab ab aab abbb aaz aabb')) #aab aab aab # (2)贪婪模式与非贪婪模式
"""
贪婪模式 : 默认向更多次匹配
非贪婪模式: 默认向更少次匹配 贪婪模式在底层使用的是回溯算法:
回溯算法:默认从左向右进行匹配,一直到最后,直到最后再也匹配不到了,回头,找最后一个能够匹配到的数据 非贪婪模式: 在量词的后面加?,这个语法就是非贪婪,默认向更少次匹配
.?? .+? .*? .{1,25}?
"""
# 贪婪模式
strvar = "刘能和刘德华和刘铁锤子777子888"
lst = re.findall("刘.",strvar) #刘能 刘德 刘铁
print(lst) lst = re.findall("刘.?",strvar) #刘能 刘德 刘铁
print(lst) lst = re.findall("刘.+",strvar) #['刘能和刘德华和刘铁锤子777子888']
print(lst) lst = re.findall("刘.*",strvar) #['刘能和刘德华和刘铁锤子777子888']
print(lst) lst = re.findall("刘.{1,25}",strvar) #['刘能和刘德华和刘铁锤子777子888']
print(lst) lst = re.findall("刘.{1,25}子",strvar) # ['刘能和刘德华和刘铁锤子777子']
print(lst) # 非贪婪模式
strvar = "刘能和刘德华和刘铁锤子777子888"
lst = re.findall("刘.??",strvar) #['刘', '刘', '刘']
print(lst) lst = re.findall("刘.+?",strvar) #刘能 刘德 刘铁
print(lst) lst = re.findall("刘.*?",strvar) #['刘', '刘', '刘']
print(lst) lst = re.findall("刘.{1,25}?",strvar) #刘能 刘德 刘铁
print(lst) lst = re.findall("刘.{1,25}?子",strvar) # ['刘能和刘德华和刘铁锤子']
print(lst) # (3) 边界符
"""
转义字符 :\b backspace 退格
边界符也用的是\b,要注意转义
例如:word 卡住边界
(1) 卡住左边界 \bw
(2) 卡住右边界 d\b
"""
strvar = "pwd word szf"
lst = re.findall(r"\bw.*",strvar)
lst = re.findall(r"\bw.*?",strvar)
lst = re.findall(r"\bw.*? ",strvar)
lst = re.findall(r"\bw\S*",strvar) print(lst)
lst = re.findall(r"d\b",strvar)
lst = re.findall(r".*d\b",strvar)
lst = re.findall(r".*?d\b",strvar) # ['pwd', ' word']
print(lst) # (4) ^ $
"""
^ 以...开头
$ 以...结尾
如果正则表达式里面出现了^ $ ,代表把这个字符串看成一个整体,再去匹配
""" strvar = "大哥大嫂大爷"
print(re.findall('大.',strvar)) # 大哥 大嫂 大爷
print(re.findall('^大.',strvar)) # 大哥
print(re.findall('大.$',strvar)) # ['大爷']
print(re.findall('^大.$',strvar))# []
print(re.findall('^大.*?$',strvar)) # 大哥大嫂大爷
print(re.findall('^大.*?大$',strvar)) # []
print(re.findall('^大.*?爷$',strvar)) # ['大哥大嫂大爷'] print(re.findall('^g.*? ' , 'giveme 1gfive gay')) #giveme
print(re.findall('five$' , 'aassfive')) # five
print(re.findall('^giveme$' , 'giveme')) # giveme
print(re.findall('^giveme$' , 'giveme giveme')) # []
print(re.findall('giveme' , 'giveme giveme')) #[giveme giveme]
print(re.findall("^g.*e",'giveme 1gfive gay')) #giveme 1gfive
正则表达式_多字符匹配 示例代码
3. 正则表达式(匹配分组 / search / 命名分组)

# ### 正则表达式 => 匹配分组
import re
print(re.findall('.*?_good','wusir_good alex_good secret男_good'))
# 把想要匹配的内容,用小圆括号包起来,表达分组
print(re.findall('(.*?)_good','wusir_good alex_good secret男_good'))
# ?: 取消括号优先显示的功能
print(re.findall('(?:.*?)_good','wusir_good alex_good secret男_good')) # | 代表或 , a|b 匹配字符a 或者 匹配字符b . 把字符串长的写在前面,字符串短的写在后面
# abc 或者 abcd
strvar = "abcpiopipoabcd234"
lst = re.findall("abc|abcd",strvar)
print(lst) # 改写
lst = re.findall("abcd|abc",strvar)
print(lst) """
\ 可以把有意义的字符变得无意义,还可以把无意义的字符变得有意义,用来转义字符
\n : 换行
\. : 单纯的匹配一个点
"""
"""
5.6
\d\.\d 39.56
\d+\.\d+
"""
# 匹配小数
strvar = "3.56 89.. .898234 8,67 39.56 34"
lst = re.findall("\d+\.\d+",strvar)
print(lst) # 匹配小数和整数
lst = re.findall(r"\d+\.\d+|\d+",strvar)
print(lst) # 使用分组合并正则 匹配小数和整数
lst = re.findall(r"\d+(?:\.\d+)?",strvar)
print(lst) # 匹配135或171的手机号
lst = re.findall(r"(?:135|171)\d{8}","13566668888 17112345678 185996964545")
print(lst) lst = re.findall(r"^(?:135|171)\d{8}$","")
print(lst) # 匹配www.baidu.com 或者 www.oldboy.com
strvar = "www.oldboy.com www.baidu.com"
lst = re.findall(r"(?:www)\.(?:baidu|oldboy)\.(?:com)",strvar)
print(lst) # search
"""
findall 匹配所有内容,缺陷:不能把匹配到的内容和分组里面的内容同时显示出来,返回的是列表
search 匹配到一个内容就直接返回,优点:可以把分组的内容,和实际匹配到的内容分开,同时显示,返回的是对象obj obj.group() 获取匹配到的内容
obj.groups() 获取分组里面的内容
"""
strvar = "www.oldboy.com www.baidu.com"
obj = re.search(r"(www)\.(baidu|oldboy)\.(com)",strvar)
print(obj)
# 获取匹配到的内容
res = obj.group()
print(res)
# 获取分组里面的内容 (推荐)
res = obj.groups()
print(res) # 获取分组里第一个元素
res = obj.group(1)
print(res)
# 获取分组里第二个元素
res = obj.group(2)
print(res)
# 获取分组里第三个元素
res = obj.group(3)
print(res) # "5*6-7/3" 匹配 5*6 或者 7/3
strvar = "5*6-7/3"
obj = re.search(r"\d+[*/]\d+",strvar)
res = obj.group()
print(res) 30
""
replace("5*6","") "5*6-7/3"
正则表达式_匹配分组_search函数 示例代码
# ### 正则表达式 => 匹配分组
import re
print(re.findall('.*?_good','wusir_good alex_good secret男_good'))
# 把想要匹配的内容,用小圆括号包起来,表达分组
print(re.findall('(.*?)_good','wusir_good alex_good secret男_good'))
# ?: 取消括号优先显示的功能
print(re.findall('(?:.*?)_good','wusir_good alex_good secret男_good')) # | 代表或 , a|b 匹配字符a 或者 匹配字符b . 把字符串长的写在前面,字符串短的写在后面
# abc 或者 abcd
strvar = "abcpiopipoabcd234"
lst = re.findall("abc|abcd",strvar)
print(lst) # 改写
lst = re.findall("abcd|abc",strvar)
print(lst) """
\ 可以把有意义的字符变得无意义,还可以把无意义的字符变得有意义,用来转义字符
\n : 换行
\. : 单纯的匹配一个点
"""
"""
5.6
\d\.\d 39.56
\d+\.\d+
"""
# 匹配小数
strvar = "3.56 89.. .898234 8,67 39.56 34"
lst = re.findall("\d+\.\d+",strvar)
print(lst) # 匹配小数和整数
lst = re.findall(r"\d+\.\d+|\d+",strvar)
print(lst) # 使用分组合并正则 匹配小数和整数
lst = re.findall(r"\d+(?:\.\d+)?",strvar)
print(lst) # 匹配135或171的手机号
lst = re.findall(r"(?:135|171)\d{8}","13566668888 17112345678 185996964545")
print(lst) lst = re.findall(r"^(?:135|171)\d{8}$","")
print(lst) # 匹配www.baidu.com 或者 www.oldboy.com
strvar = "www.oldboy.com www.baidu.com"
lst = re.findall(r"(?:www)\.(?:baidu|oldboy)\.(?:com)",strvar)
print(lst) # search
"""
findall 匹配所有内容,缺陷:不能把匹配到的内容和分组里面的内容同时显示出来,返回的是列表
search 匹配到一个内容就直接返回,优点:可以把分组的内容,和实际匹配到的内容分开,同时显示,返回的是对象obj obj.group() 获取匹配到的内容
obj.groups() 获取分组里面的内容
"""
strvar = "www.oldboy.com www.baidu.com"
obj = re.search(r"(www)\.(baidu|oldboy)\.(com)",strvar)
print(obj)
# 获取匹配到的内容
res = obj.group()
print(res)
# 获取分组里面的内容 (推荐)
res = obj.groups()
print(res) # 获取分组里第一个元素
res = obj.group(1)
print(res)
# 获取分组里第二个元素
res = obj.group(2)
print(res)
# 获取分组里第三个元素
res = obj.group(3)
print(res) # "5*6-7/3" 匹配 5*6 或者 7/3
strvar = "5*6-7/3"
obj = re.search(r"\d+[*/]\d+",strvar)
res = obj.group()
print(res) 30
""
replace("5*6","") "5*6-7/3"
正则表达式_命名分组 示例代码
day21
最新文章
- vim 大全用法
- 如何催促Apple进行App审核
- 【转】关于Unity协同程序(Coroutine)的全面解析
- 树(一)——线段树
- Apache Shiro简介
- 解决在 使用 AjaxFileUploder 插件时,不能获取返回的 json 结果数据
- HTML5和Web Apps框架和方法
- 【转】Git详解之一:Git起步
- 基于百度定位SDK的定位服务的实现
- hdu1025(nlon(n)最长上升子序列)
- Best Coder #86 1002 NanoApe Loves Sequence
- Linux(以CentOS6.5示例)下安装Oracle官方最新版JDK(JDK1.8)
- 步步为营---- MuleEsb学习(一) 扫盲篇
- skywalking6.0.0安装配置(windows),以mysql作为储存。
- django 的后台管理
- java整数溢出问题及提升为long型
- 大叔学ML第五:逻辑回归
- Kettle 变量(arg位置参数)
- Qt Creator 搭配Git 版本控制
- python html css 初识
热门文章
- SQL语句 分组 多行合并成一行
- nginx反向代理配置及常见指令
- 喵星之旅-狂奔的兔子-rabbitmq的java客户端使用入门
- JAVA(4)之关于项目部署在tomcat
- thinkphp 3.2链接Oracle数据库,查询数据
- [转]Serverless
- [Qt 踩坑] 设置背景就卡退 报错 异常结束或者crashed 0xFFFFFFFF
- 吴裕雄 python 机器学习——模型选择验证曲线validation_curve模型
- Navicat连接两个不同机子上的mysql数据库,端口用换吗?--不用
- Computational Complexity of Fibonacci Sequence / 斐波那契数列的时空复杂度