keras Model 2 多输入和输出
2024-09-01 13:36:15
函数式模型有一个很好用的应用实例是:编写拥有多个输入和输出的模型。函数式模型使得在复杂网络中操作巨大的数据流变的简单。
我们实现下面这样的模型
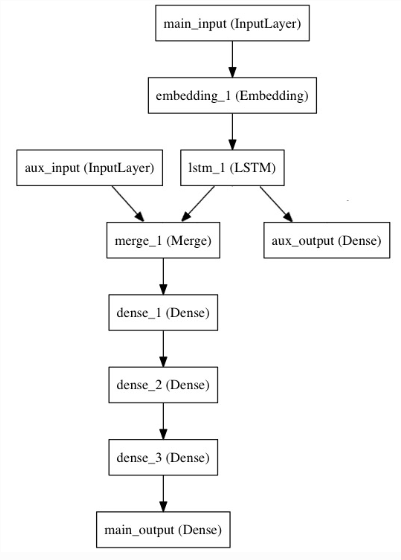
from keras.layers import Input, Embedding, LSTM, Dense
from keras.models import Model # Headline input: meant to receive sequences of 100 integers, between 1 and 10000.
# Note that we can name any layer by passing it a "name" argument.
main_input = Input(shape=(100,), dtype='int32', name='main_input') # This embedding layer will encode the input sequence
# into a sequence of dense 512-dimensional vectors.
x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input) # A LSTM will transform the vector sequence into a single vector,
# containing information about the entire sequence
lstm_out = LSTM(32)(x)
这里有 两个知识点
1、embedding层的使用。这里有个背景知识:我们输入的是100整数,每个整数都是0-1000的。代表的含义是:我们有个1000词的词典,输入的是100词的标题
然后经过embedding层,进行编码,输出512的向量
2、 LSTM(32)返回值是一个model,它可以向layer一样直接被调用
然后我们插入一个辅助层,它可以使得即使在模型的主损失值很大的时候 ,LSTM和Embedding层也可以得到平滑的训练
auxiliary_output = Dense(1, activation='sigmoid', name='aux_output')(lstm_out)
我们加入一个平滑的输入 ,把它和LSTM的输出连接在一起
auxiliary_input = Input(shape=(5,), name='aux_input')
x = keras.layers.concatenate([lstm_out, auxiliary_input]) # We stack a deep densely-connected network on top
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x) # And finally we add the main logistic regression layer
main_output = Dense(1, activation='sigmoid', name='main_output')(x)
这样,我们的模型就有两个输入和两个输出
model = Model(inputs=[main_input, auxiliary_input], outputs=[main_output, auxiliary_output])
我们编译我们的模型,并且给平滑损失一个0.2的权重。可以用列表或者字典定义不同输出对应损失权重,如果对loss传入一个数 ,则损失权重会被用于全部的输出。
model.compile(optimizer='rmsprop', loss='binary_crossentropy',
loss_weights=[1., 0.2])
然后fit数据进行训练
model.fit([headline_data, additional_data], [labels, labels],
epochs=50, batch_size=32)
当然,也可以通过字典来 实现这个目的:
model.compile(optimizer='rmsprop',
loss={'main_output': 'binary_crossentropy', 'aux_output': 'binary_crossentropy'},
loss_weights={'main_output': 1., 'aux_output': 0.2}) # And trained it via:
model.fit({'main_input': headline_data, 'aux_input': additional_data},
{'main_output': labels, 'aux_output': labels},
epochs=50, batch_size=32)
最新文章
- Sql server之sql注入篇
- delphi XE Berlin ReadProcessMemory WriteProcessMemory
- django shell 集合
- Oracle存储过程中传入参数,传出字符串
- mysql如何修改表类型(表引擎)
- Android --Android Stuido 导入jar包
- 无shell情况下的mysql远程mof提权利用方法详解
- SkyDrive Pro client now available as standalone download. Hurray!
- byte数组和int互转
- NGINX配置小随笔
- LeetCode_Minimum Path Sum
- Xcode6和Xcode5获取app名字
- 利用arpspoof和urlsnarf 进行ARP嗅探
- 伊布(ib)
- Python档案袋( Json、pickle、加密与解密)
- 使用Apache JMeter对SQL Server、Mysql、Oracle压力测试(三)
- Maccms8.x 命令执行漏洞分析
- BizTalk RosettaNet解决方案搭建
- windows设置程序开机自启动
- nginx防盗链、nginx访问控制、nginx解析php相关配制、nginx代理