28、对多次使用的RDD进行持久化或Checkpoint
2024-10-21 12:02:18
一、图解
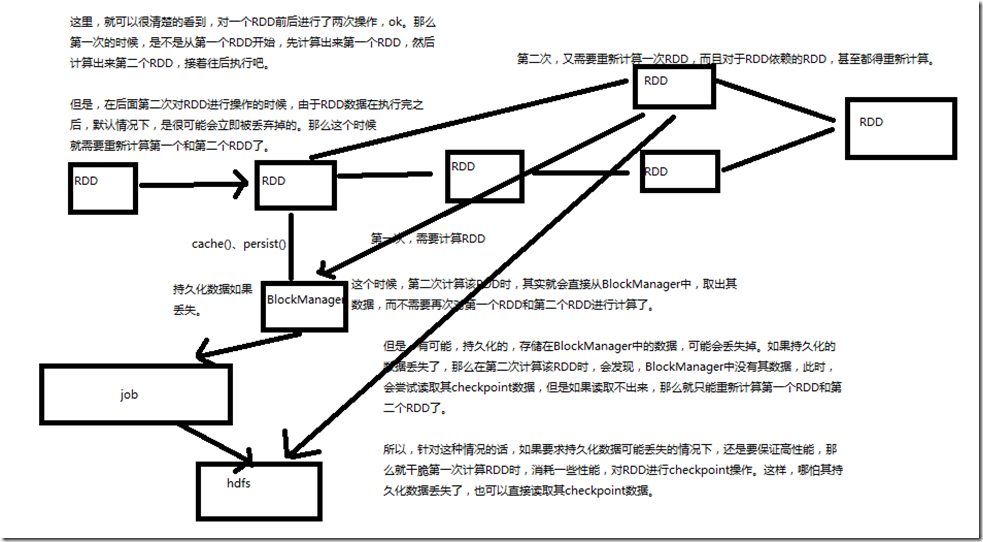
二、说明
如果程序中,对某一个RDD,基于它进行了多次transformation或者action操作。那么就非常有必要对其进行持久化操作,以避免对一个RDD反复进行计算。 此外,如果要保证在RDD的持久化数据可能丢失的情况下,还要保证高性能,那么可以对RDD进行Checkpoint操作。 持久化,再checkpoint
这样,第一次,需要重新计算RDD; 第二次计算该RDD,其实会从BlockManager中,取出其数据,而不需要再次对第一个RDD和第二个RDD进行计算了; 但是,有可能持久化的数据,存储在BlockManager中的数据,可能会丢失掉。如果持久化的数据丢失了,那么在第二次计算该RDD时,会发现,BlockManager中没有数据
,此时,会尝试读取器checkpoint数据,如果读取不出来,只能重新计算第一个RDD和第二个RDD了; 所以,如果持久化数据可能丢失的情况下,还要保证高性能,那么就干脆第一次计算RDD时,消耗一些性能,对RDD进行checkpoint操作,这样,哪怕其持久化数据丢失
了,也可以直接读取其checkpoint的数据;
三、序列化的持久化级别
除了对多次使用的RDD进行持久化操作之外,还可以进一步优化其性能。因为很有可能,RDD的数据是持久化到内存,或者磁盘中的。那么,此时,如果内存大小不是特别充足,
完全可以使用序列化的持久化级别,比如MEMORY_ONLY_SER、MEMORY_AND_DISK_SER等。使用RDD.persist(StorageLevel.MEMORY_ONLY_SER)这样的语法即可。 这样的话,将数据序列化之后,再持久化,可以大大减小对内存的消耗。此外,数据量小了之后,如果要写入磁盘,那么磁盘io性能消耗也比较小。 对RDD持久化序列化后,RDD的每个partition的数据,都是序列化为一个巨大的字节数组。这样,对于内存的消耗就小的多了。但是唯一的缺点就是,获取RDD数据时,
需要对其进行反序列化,会增大其性能开销。 因此,对于序列化的持久化级别,还可以进一步优化,也就是说,使用Kryo序列化类库,这样,可以获得更快的序列化速度,并且占用更小的内存空间。但是要记住,
如果RDD的元素(RDD<T>的泛型类型),是自定义类型的话,在Kryo中提前注册自定义类型。
最新文章
- 时间戳TimeStamp处理
- python 定义类方法
- [水煮 ASP.NET Web API2 方法论](3-2)直接式路由/属性路由
- Centos下samba共享打印机
- Operand forms
- Ubuntu16.04.1 安装Redis-Cluster
- Python学习的一些好资料
- TaobaoProtect.exe,Alipaybsm.exe进程删除----让流氓软件滚粗
- SQL Server 服务器磁盘测试之SQLIO篇
- 第三节,入门知识和windows系统安装python环境
- js 输出HTML 样式
- TCP/IP Protocol Fundamentals Explained with a Diagram
- JDBC中rs.beforeFirst()
- YII框架CGridView sql有条件分页实现
- Struts2——namespace、action、以及path问题
- unicode解码
- Your ApplicationContext is unlikely to start due to a @ComponentScan of the default package
- (C/C++学习笔记) 二十二. 标准模板库
- FortiGate基本信息
- 对datagridview进行增删改(B)