007-IP报文协议
一、概述
IP协议是TCP/IP协议的核心,所有的TCP,UDP,IMCP,IGMP的数据都以IP数据格式传输。要注意的是,IP不是可靠的协议,这是说,IP协议没有提供一种数据未传达以后的处理机制,这被认为是上层协议:TCP或UDP要做的事情。
Internet上连接的所有计算机,从大型机到微型计算机都是以独立的身份出现,我们称它为主机。为了实现各主机间的通信,每台主机都必须有一个唯一的网络地址。就好像每一个住宅都有唯一的门牌一样,才不至于在传输资料时出现混乱。
Internet的网络地址是指连入Internet网络的计算机的地址编号。所以,在Internet网络中,网络地址唯一地标识一台计算机。
nternet是由无数台计算机互相连接而成的。而我们要确认网络上的每一台计算机,靠的就是能唯一标识该计算机的网络地址,这个地址就叫做IP(Internet Protocol的简写)地址,即用Internet协议语言表示的地址。
1.1、IP协议功能
(1)寻址和路由;(根据对方的IP地址,寻找最佳路径传输信息);
(2)传递服务:① 不可靠(IP协议只是尽自己最大努力去传输数据包),可靠性由上层协议提供(TCP协议); ② 无连接(事先不建立会话),不维护任何关于后续数据报的信息;
(3)数据包的分片和重组。
1.2、IP地址分类以及子网掩码
关于IP的介绍:002-IP地址及分类以及子网掩码
二、IP协议报文
2.1、IP协议头


2.2、解释说明
版本号:4个bit,用来标识IP版本号。这个4位字段的值设置为二进制的0100表示IPv4,设置为0110表示IPv6。目前使用的IP协议版本号是4。
首部长度:4个bit。标识包括选项在内的IP头部字段的长度。
服务类型:8个bit。服务类型字段被划分成两个子字段:3bit的优先级字段和4bit TOS字段,最后一位置为0。4bit的TOS分别代表:最小时延,最大吞吐量,最高可靠性和最小花费。4bit中只能将其中一个bit位置1。如果4个bit均为0,则代表一般服务。
总长度:16个bit。接收者用IP数据报总长度减去IP报头长度就可以确定数据包数据有效负荷的大小。IP数据报最长可达65535字节。
标识:16个bit。唯一的标识主机发送的每一份数据报。接收方根据分片中的标识字段是否相同来判断这些分片是否是同一个数据报的分片,从而进行分片的重组。通常每发送一份报文它的值就会加1。
标志:3个bit。用于标识数据报是否分片。第1位没有使用,第2位是不分段(DF)位。当DF位被设置为1时,表示路由器不能对数据包进行分段处理。如果数据包由于不能分段而未能被转发,那么路由器将丢弃该数据包并向源发送ICMP不可达。第3位是分段(MF)位。当路由器对数据包进行分段时,除了最后一个分段的MF位被设置为0外,其他的分段的MF位均设置为1,以便接收者直到收到MF位为0的分片为止。
片偏移:13个bit。在接收方进行数据报重组时用来标识分片的顺序。用于指明分段起始点相对于报头起始点的偏移量。由于分段到达时可能错序,所以位偏移字段可以使接收者按照正确的顺序重组数据包。当数据包的长度超过它所要去的那个数据链路的MTU时,路由器要将它分片。数据包中的数据将被分成小片,每一片被封装在独立的数据包中。接收端使用标识符,分段偏移以及标记域的MF位来进行重组。
生存时间:8个bit。TTL域防止丢失的数据包在无休止的传播。该域包含一个8位整数,此数由产生数据包的主机设定。TTL值设置了数据报可以经过的最多的路由器数。TTL的初始值由源主机设置(通常为32或64),每经过一个处理它的路由器,TTL值减1。如果一台路由器将TTL减至0,它将丢弃该数据包并发送一个ICMP超时消息给数据包的源地址。
协议:8个bit。用来标识是哪个协议向IP传送数据。ICMP为1,IGMP为2,TCP为6,UDP为17,GRE为47,ESP为50。
首部检验和:根据IP首部计算的校验和码。
源地址:IP报文发送端的IP地址
目的地址:IP报文接收端的IP地址
选项:是数据报中的一个可变长的可选信息。选项字段以32bit为界,不足时插入值为0的填充字节。保证IP首部始终是32bit的整数倍。
可以通过IP报文抓包分析
2.3、IP分片偏移重组
当一个IP数据报被分片后,直到它到达最终目的地才会被重组。(因为同一个数据报的不同分片,可能经由不同的路径到达相同的最终目的地,所以中途有可能无法重组)
ip分组后,每一个分片都是一个完整的ip数据报。其中首部里的“总长度”字段,是该分片的总长度。
分片技术与ip首部中以下三个字段有关:标识、标志、片偏移
标识符:
主机将数据报分片后,在发送前,会给每一个分片数据报一个ID值,放在16位的标识符字段中。
这个ID值可以用来识别哪些分片是属于同一个数据报的,方便重组。
标志:
标志字段在IP报头中占3位,
第1位作为保留,置0;
第2位,分段,有两个不同的取值:该位置0,表示可以分段;该位置1,表示不能分段;
第3位,更多分段,同样有两个取值:该位置0,表示这是数据流中的最后一个分段,该位置1,表示数据流未完,后续还有分段,当一个数据报没有分段时,则该位置0,表示这是唯一的一个分段。
当目的主机接收到一个IP数据报时,会首先查看该数据报的标识符,并且检查标志位的第3位是置0或置1,以确定是否还有更多的分段,如果还有后续报文,接收主机则将接收到的报文放在缓存直到接收完所有具有相同标识符的数据报,然后再进行重组。
偏移量:
就像之前说过的,各个IP分片数据报在发送到目的主机时可能是无序的,所以就需要“偏移量”字段来指明“该分片在原数据报中的位置顺序”。
发送主机对第一个数据报的偏移量置为0,而后续的分片数据报的偏移量则以网络的MTU大小赋值。
如:
假设:网络接口MTU大小为1400字节,要传输的数据报为3800字节。
那么,将要传输的数据报分为3片即可(3800=1400+1400+1000)
偏移量的计算方法为:已经“装载”好的分片字节数/8(偏移量就是某片在原分组的相对位置,所以8个字节作为偏移单位。)
分片1偏移量为:0(0=0/8,因为该偏移量之前没有装载过任何分片,自然也就是0除以8了)
分片2偏移量为:175(175=1400/8,由于分片1已经装载好了1400字节,所以此分片的位置就在1400字节之后,也就用1400除以8了)
分片3偏移量为:350(350=2800/8,目前已经装好了两个分片也就是2800字节已经装载完了,那么分片3自然就跟在2800字节之后了,也就是用2800除以8)
2.3.1、分片重组原因
链路层通常对可传输的每一个帧的最大长度都有上限。为了使超过此上限的ip数据报能够正常传输,IP引入了“分片”和“重组”。
当IP层接收到要发送的IP数据报时,通过查找“转发表”,会判断该数据报应该从那个本地“接口”发送以及MTU(最大传输单元,指一种通信协议的某一层上面所能通过的最大数据包大小(以字节为单位))是多少。
不同的网络类型,其MTU都不相同,如以太网中MTU为1518字节,FDDI为4500字节。如果IP数据报超过MTU值,则进行分片。IPv4的分片可以在原始发送方主机和端到端路径上的任何中间路由器上进行,即:一个分片在到达接收主机的路径中,还可能被继续分片。(而IPv6只允许源主机进行分片)
以太网的MTU是1500。如果IP层有数据包要传,而且数据包的长度超过了MTU,那么IP层就要对数据包进行分片(fragmentation)操作,使每一片的长度都小于或等于MTU。我们假设要传输一个UDP数据包,以太网的MTU为1500字节,一般IP首部为20字节,UDP首部为8字节,数据的净荷(payload)部分预留是1500-20-8=1472字节。如果数据部分大于1472字节,就会出现分片现象。
2.3.2、不同传输层协议的分片
(1)TCP协议
对于TCP协议来说尽量避免分片,因为当在IP层进行了分片后,如果其中的某片数据丢失,则需对整个数据报进行重传。因为IP层本身没有超时重传机制,当来自TCP报文段的某一片丢失后,TCP在超时后重发整个TCP报文段,该报文段对应于一份IP数据报,没有办法只重传数据报中的一个数据报片。
TCP协议可以避免分片,避免的机制是首先,TCP在建立连接时会进行3次握手,而在这3次握手中,客户端和服务端通常会协商一个值,那就是MSS(最长报文大小),用来表示本段所能接收的最大长度的报文段。MSS=MTU-TCP首部大小-IP首部大小,MTU值通过查询链路层得知。
当两端确认好MSS后进行通信,TCP层往IP层传输数据时,如果TCP层缓冲区的大小大于MSS,那么TCP层都会将其中的数据分组进行传输,这样就避免了在IP层进行分片。
(2)UDP协议
对于UDP而言,由于UDP是不需要保证可靠性的,没有超时和重传机制,这使得UDP很容易导致IP分片。
UDP协议分片会根据IP报文字段中的标识字段、标志字段、片偏移字段来解决。

对于每份IP数据报来说,其16位标识字段都包含一个唯一值。在数据报被分片时,这个值同时被复制到每个片中。用来识别分片的数据是否为同一个数据报文。
在IP首部中,我们看到有一个占了3位的标志字段,其中第1位是R作为保留字段未用;第2位分段是DF用来表示一个数据报是否允许在IP层被分片,DF=0时允许分片,DF=1时不允许分片;而第3位是MF更多分片字段,则是当数据报被分片时,让接收端知道在什么时候完成所有的分片组装,除了最后一片外,其他每个组成数据报的片都要把该比特置1。
而如果将其中的分段标志比特位置1,表示不允许IP层对数据报进行分片。例如当路由器收到一份需要分片的数据报,而在IP首部又设置了不分片(DF)的标志比特,路由器会丢弃数据报并发送一个ICMP差错报文(“需要进行分片但设置了不分片比特”)。
IP首部的13位片偏移字段表示IP分片再整个数据流中的位置,第一个数据报分片的偏移量置为0,而后续的分片偏移量则是根据网络的MTU大小设置,且必须为8的整数倍。
2.3.3、分片字段
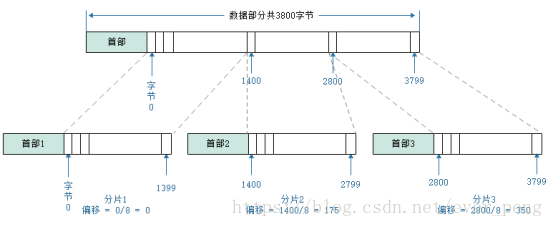
上图中我们看到把一个报文长度为3800字节的报文分片为三个。他们每一个分片都会含有一个标识(IP地址 + 标识),到达目的地要对其所有的分片进行重新组装;
片偏移计算过程;首部分大体的内容是一样,因为都属于同一个数据报文
2.3.4、IP报文重组
IP报文分片后进行重组,只能在目标主机进行重组。
IP报文分片重组时,采用了一组重组定时器,片重组的控制主要根据数据首部中的标识、标志、偏移字段进行重组。
分片重组策略如下:
(1)第一个分片的偏移值时0
(2)将第一个分片携带的数据长度除以8,结果就是第二个分片的偏移值
(3)将第一个和第二个分片携带数据的总长度除以8,结果就是第二个分片的偏移值
(4)继续以上过程。直到之后分片的MF标志位为0
2.4、IP报文校验
2.4.1、IP报文校验和计算方式
(1)为了计算一份数据报的IP检验和,首先需要把检验和字段置为0
(2)对首部中每个16bit进行二进制反码求和(整个首部看成是由一串16bit的字组成)
PS:路由器收到IP报文,然后转发之后,是需要对TTL(Time to Live)字段减一,那么这样的话IP报文校验和数值也需要进行相应改变
2.4.2、IP报文不对数据校验原因
上层传输层是端到端的协议,进行端到端的校验比进行点到点的校验开销小。
2.4.3、IP报文对IP首部校验原因
IP首部属于IP层协议的内容,上层协议无法处理。
IP首部的部分字段在点到点的传递过程中是不断变化的,只能在每个中间点重新形成校验数据,在相邻点完成校验。
方式
最新文章
- IntelliJ IDEA上创建maven Spring MVC项目
- Django博客功能实现—文章评论的显示
- 写一些封装part1 (事件绑定移除,圆形矩形碰撞检测)
- spring 3.1 配置 JCR 303 Bean Validation
- java 锁!
- n枚硬币问题(找假币)
- 一个优秀的Android应用从建项目开始
- lua cURL使用笔记
- dede cms列表页调用文章简介(借鉴)
- AJAX 基础知识
- POJ 3422 Kaka's Matrix Travels (最小费用最大流)
- Spring框架学习之高级依赖关系配置(一)
- android 开发从入门到精通
- WPF如何得到一个在用户控件内部的元素的坐标位置
- 如何实现文件上传 - JavaWeb
- php_D3_“简易聊天室 ”实现的关键技术 详解
- linux 按文件大小排序
- JS高程关于ajax的学习笔记
- JAVA & .NET创建对象构造函数调用顺序
- datatables后端分页