Value Iteration Algorithm for MDP
Value-Iteration Algorithm:
For each iteration k+1:
a. calculate the optimal state-value function for all s∈S;
b. untill algorithm converges.
end up with an optimal state-value function
Optimal State-Value Function
As mentioned on the previous post, the method to pick up Optimal State-Value Function is shown below. From state s, we have multiple possible actions, what we will do is choose the best combination of immediate reward and state-value function from the next state.
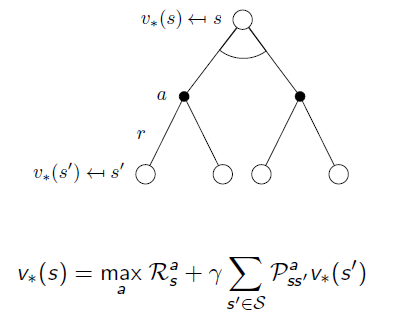
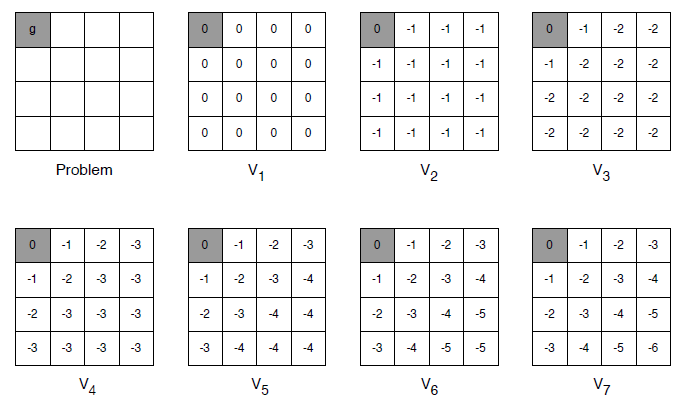
Example for a grid game, it is quite like information propagate from the terminal states backward:
From State-Value Function to Policy
After we've got the Optimal State-Value Function, the Optimal Policy can be aquired by maxmizing the Action-Value Function. This means we try all possible actions from state s, and then choose the one that has the maximum reward.
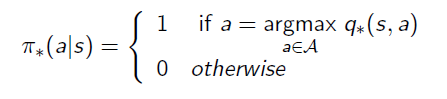
最新文章
- 繁星——jquery的data()方法
- equals和“==”
- 整理分享C#通过user32.dll模拟物理按键操作的代码
- Jmeter测试结果分析
- App Transport Security has blocked a cleartext
- C语言创始人
- [转]JAVA设计模式之单例模式
- ubuntu下matplotlib画图中文乱码问题
- 如何将cmd中命令输出保存为TXT文本文件
- JavaScript 权威指南第6版 - [阅读笔记]
- android 09
- 页面点击关闭弹出提示js代码
- Spring Boot 部署与服务配置
- jenkins+ANT+jmeter 接口测试环境搭建
- EntityFramework附加实体
- C++11 并发指南三(std::mutex 详解)
- linux系统下find命令的使用
- centos6.5重新调整/home和跟目录/大小
- C# EditPlus环境设置
- Java多线程编程之单例模式