什么是HBASE(三) HBase的压缩和编码
2024-09-26 22:50:33
在存储层面节省空间的处理上,Hbase提供了两种方案,一个是基于key的编码,一个是基于数据块(data block)的压缩。前者用于将key重复部分进行简单处理达到节约空间的目的,后者则是对数据块进行压缩,实现节省硬盘。不过压缩和解压缩是影响处理性能的,都是那时间换空间;所以要权衡清楚。
关于key的编码,主要是这对于key很长而且有大量部分重复的场景,如果key大部分长得都不一样,那么编码几乎没有优势:
prefix
简单讲就是把key中和前一条记录相同的部分省略不计;然后再增加一列,记录省略的长度(相同部分的长度)
下图是原始数据
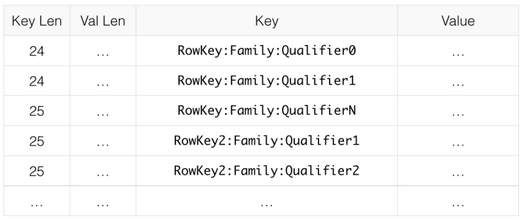
下图是编码后的数据,可以看到增加了prefix len一列,记录从第一位开始重复的位数,但是key一列的记录被简化了。

Diff
diff则是基于prefix基础之上模式,它直接将和上条记录一样部分省略;diff和prefix不同之处在于它认为每条记录都有一个唯一主键,所以,diff增加了两列,一列是timestamp,一列是type;这样处理好处是主键被分割后可以在压缩后有比较好的效率;默认diff是被禁用的,因为在scan的时候diff的性能比较差。

Fast Diff
处理机制和diff类似,不过它增加了一列flag来标志当前行是否和上一行一样,一样则不记录;Fast Diff是推荐的编码模式,尤其适用于key很长的情况;
Prefix Tree
提供的机制和上面类似,但是其随机读写速度很快,但是编码速度比较慢;适用于内存的命中率比较高的场景,在HBase 0.9.6版本中提出并处于试验阶段。可以在和FastDiff比较多时候,多做做测试;
压缩
关于压缩,压缩的使用主要是用在value字段比较大的场景,比如是图片,或者二进制流;如果只是普通的文本,那么压缩意义并不是很大,而且在解压的时候需要耗费资源来做,影响性能;
压缩的技术选择主要就是在Gzip, LZO和Snappy中选择,对于冷数据(很少被使用到)可以采用GZip,因为GZip的压缩率比较高,但是解压消耗的CPU比较多;
对于热数据主要是采用Snappy和LZO,Snappy是谷歌(2011年)推出的压缩算法,在CPU的使用和效率方面都比LZO要好,但是因为授权(许可证)的因素,hadoop的native library没有提供支持,只能是后安装在os上面之后才能够使用。
压缩的本质是HFile的压缩,HFile是物理存储hdfs中,所以压缩的本质是hdfs的压缩,压缩算法的支持本质是hdfs支持的算法。

最新文章
- Linux下安装php加速器xcache
- Android DDMS检测内存泄露
- MapReduce:详解Shuffle过程(转)
- NET
- Emmet:HTML/CSS代码快速编写神器(转)
- Tempdb对SQL Server性能的影响
- 中文乱码?不,是 HTML 实体编码!(转)
- 大前端服务器渲染 发布和部署 Vue + vue(SSR)
- JavaScript 获取完整当前域名
- [Swift]LeetCode25. k个一组翻转链表 | Reverse Nodes in k-Group
- JavaScript中关于页面URL地址的获取
- 有时间研究一下Spark的HashPartitioner和RangePartitioner
- eclipse 启动tomcat 出现错误Could not publish server configuration: null. java.lang.NullPointerException
- C++ const方法及对象
- NOI.AC NOIP模拟赛 第二场 补记
- 基于遗传算法求解TSP问题(Java界面)
- <图形图像,动画,多媒体> 读书笔记 --- AirPlay
- Ubuntu 安装 Kubernetes
- 利用jsPerf优化Web应用的性能
- 【转】Android自定义控件(二)——有弹性的ScrollView
热门文章
- poj1496 Word Index / poj1850 Code(组合数学)
- Linux及安全实践二
- AOP Schema配置
- 2018-2019 Russia Open High School Programming Contest (Unrated, Online Mirror, ICPC Rules, Teams Preferred)
- 2012NOIP模拟试题
- tp5.1报错 页面错误!请稍后再试
- Kotlin中常量和静态方法
- Leetcode 18
- css单位长度
- python3 中文乱码,UnicodeEncodeError: 'latin-1' codec can't encode characters in position 10-13: ordinal not in range(256)