开源大数据技术专场(下午):Databircks、Intel、阿里、梨视频的技术实践
2024-08-22 09:49:18
摘要: 本论坛第一次聚集阿里Hadoop、Spark、Hbase、Jtorm各领域的技术专家,讲述Hadoop生态的过去现在未来及阿里在Hadoop大生态领域的实践与探索。
开源大数据技术专场下午场在阿里技术专家封神的主持下开始,参与分享的嘉宾有Spark Commiter、来自Databriks的范文臣,HDFS committer、Intel 研发经理郑锴,逸晗网络科技大数据平台负责人杨智,Intel技术专家毛玮,以及阿里云技术专家木艮。
Databricks范文臣:Deep Dive Into Catalyst——Apache Spark 2.0's Optimizer
在本次演讲中范文臣首先重点介绍了Catalyst。在Spark中,DataSet以及DataFrame均依赖于Catalyst,Catalyst不仅是SQL的解析引擎,还是Spark中的优化器。文臣先从最简单最基础的Spark RDD API实例以及解决方案讲起,逐步阐明如何通过最容易有效的方法来让程序自动地进行优化,即通过优化器来自动地找到用户程序中最有效的执行计划,最后引出了Catalyst优化器:
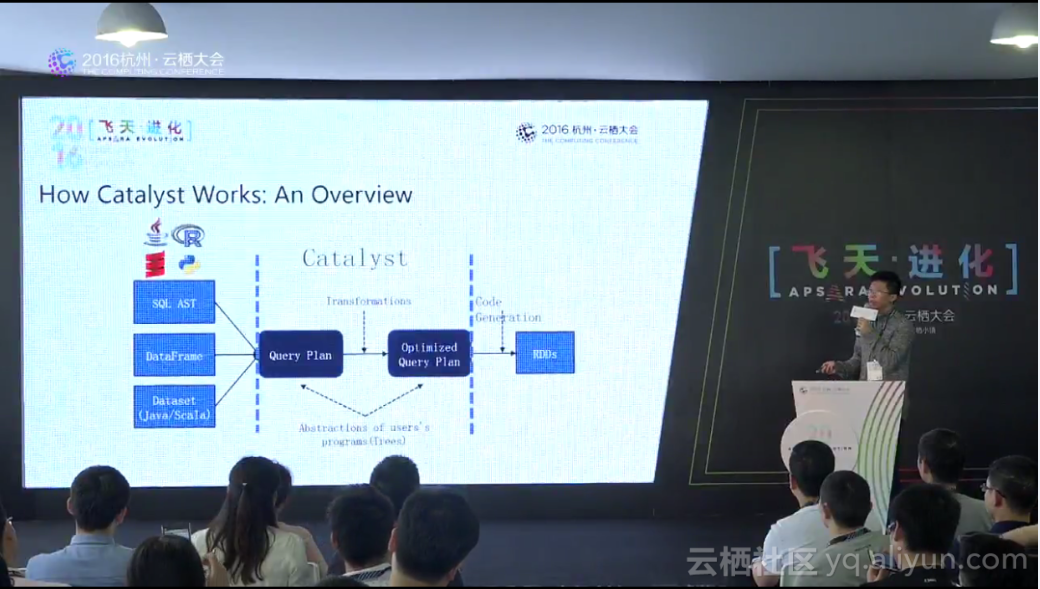
Catalyst介于Spark RDD和SQL、DataFrame、DataSet之间,优化原始的查询计划,可将其看成为树状的表达式结构,可以将表达式、逻辑计划以及物理计划进行相应的转换:
不改变树的类型的转换:Expression => Expression;Logical Plan => Logical Plan;Physical Plan => Physical Plan。将一种树转换为另一种:Logical Plan => Physical Plan从而可以清晰地看到Catalyst一整套规则:
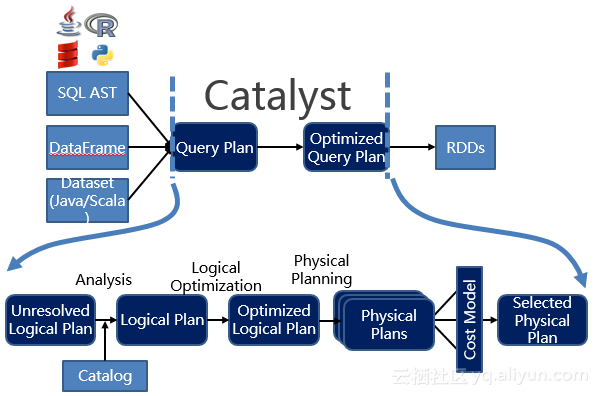
最后,范文臣还是希望在Spark 2.0的环境下,开发者可以使用更高级的API(SQL,DataFrame以及DataSet),而Catalyst作为底层的优化器,会继续为程序提供更加自动、有效的优化。
Intel研发经理郑锴:海量数据分布式存储——Apache HDFS之最新进展
郑锴首先给对大数据发展趋势进行了分享,包括:(1)存储和处理的数据量越来越大;(2)处理速度的期望越来越高;(3)存储的场景更复杂、更丰富;(4)存储越来越廉价,速度越来越快;(5)网络宽带也越来越高;(6)存储和计算分离,大数据加速向云端迁移。在此基础上,对HDFS存储的演化进行了分享,包括:
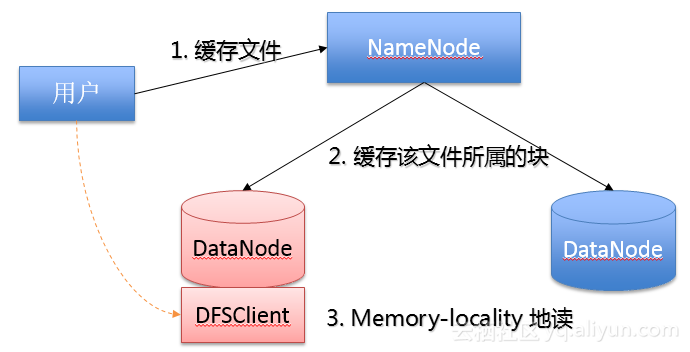
(1)HDFS Cache支持:
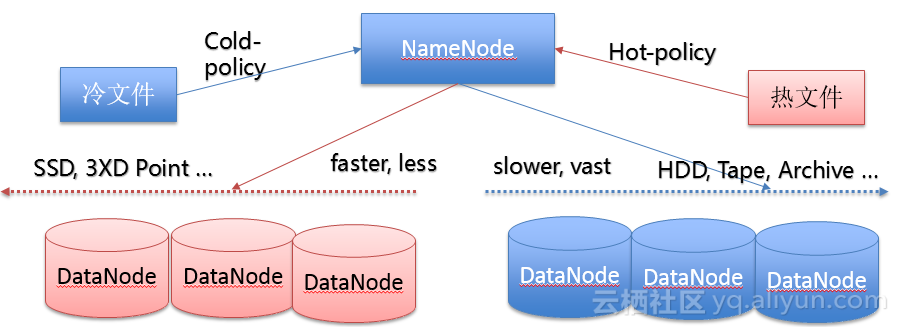
(2)HDFS HSM多层次存储体系:
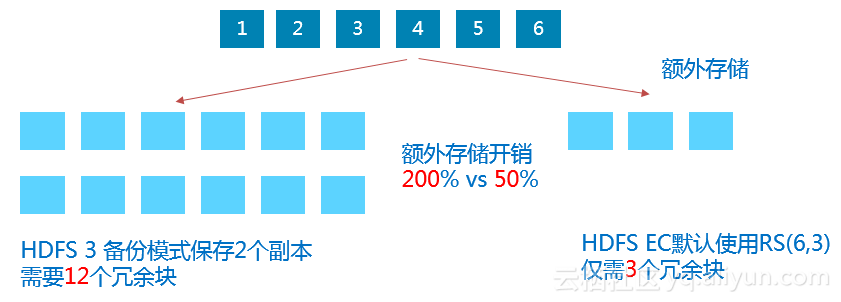
(3)HDFS 纠删码的支持:
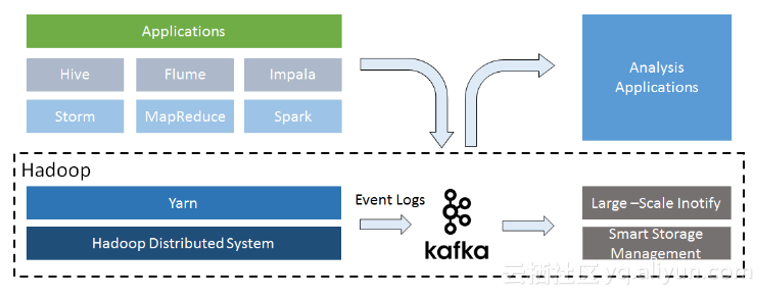
在演讲的最后,对HDFS的未来技术发展进行了展望,对目前HDFS面临的问题挑战进行了分析,他认为未来HDFS的发展方向包括:(1)智能存储管理(Smart Storage Management,SSM ),提供端到端的全面的智能存储解决方案,完整地收集集群的存储和数据访问统计,简化地、智能地和全面地及时感知集群存储状态变化并作出存储策略调整,未来Kafka将引入到Hadoop当中,作为基础服务(KafkaService):
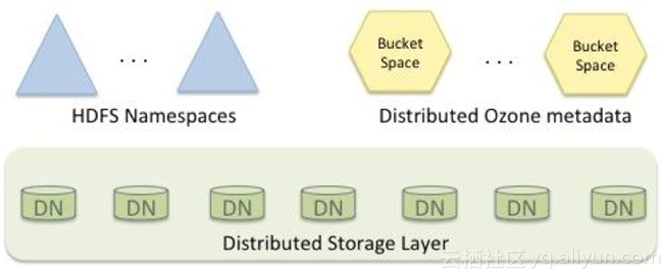
(2)对象存储(Object Storage),Hadoop正在演化成为一个更为通用的平台,甚至支持传统的服务和应用,未来会支持对象存储,因为对象存储是一个流行的趋势,包括S3、AXURE、AliYun等目前都支持对象存储:
(3)存储在云端:提供统一的Hadoop文件系统和API,包括S3、AXURE、AliYun上的存储支持,同时支持快速弹性的HDFS缓存层。

梨视频大数据负责人杨智:基于E-MapReduce梨视频推荐系统
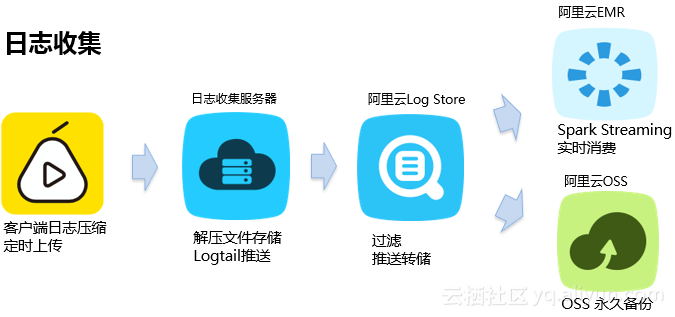
杨智首先对基于Logtail和阿里云的Logstore日志收集处理流程进行介绍,对数据如何保存在阿里云的OSS上进行永久备份保存、如何通过EMR中的Spark Streaming实时消费Logstore中的日志进行了详细介绍。
在此基础上,详细介绍了如何以EMR为中心,构建符合公司实际情况的大数据处理中心,对产品中的基础数据进入EMR,并依托于EMR进行任务管理、数据存储的逻辑及数据分层框架进行了详细介绍。
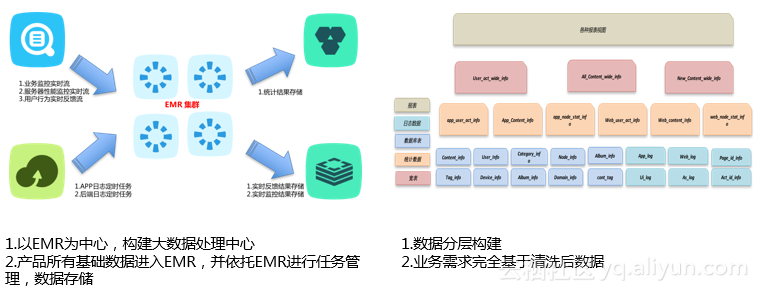
随后,分享了梨视频推荐系统的整体概貌:
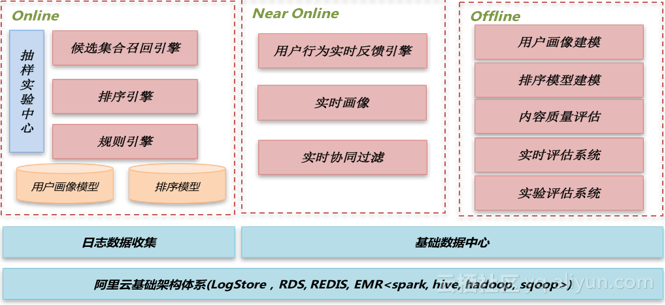
对Online的招回和排序、Near Online实时反馈系统、Offline用户兴趣画像、基础排序模型中的内容质量评估及推荐的整体流程都进行了详尽的介绍。为其它企业基于EMR构建一套数据处理系统和推荐系统提供了重要的案例参考。
阿里云技术专家毛玮:分布式流处理框架——功能对比和性能评估
毛玮给大家分享了主流的分布式流处理架构Spark Streaming、Storm、Storm Trident、Flink、Apache Gearpump及Heron的功能差异及性能评估情况。
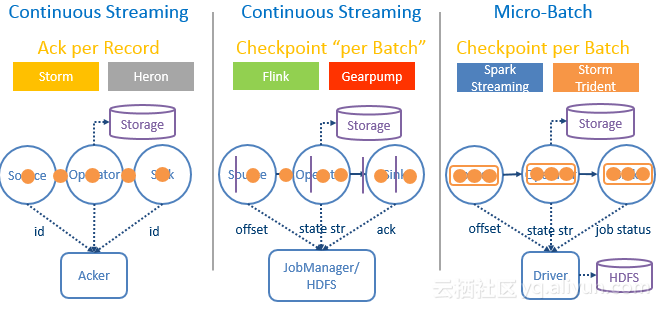
首先介绍了六个框架之间执行模型(Execution Model)和容错机制(Fault Tolerance Mechanism)方面的差异,分别就各大框架间的具体容错方法、延迟性(Latency)、送达保证(Delivery Guarantee)、本地状态操作(Native State Operator)及动态负载均衡和恢复速度(Dynamic Load Balance & Recovery Speed)等方面进行了比较。
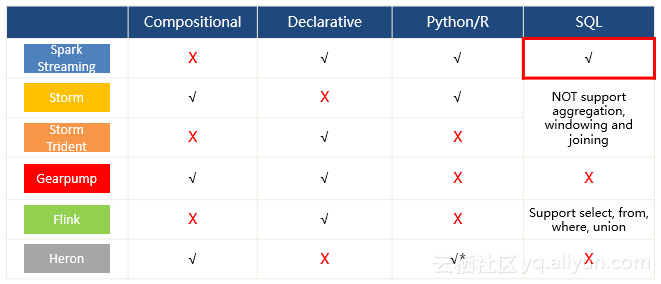
然后对各大框架的API的特点进行了比较,详细介绍了Storm、Gearpump、Heron 组合式(Compositional) API特点,Spark、 Storm Trident、Flink及Gearpump声明式(Declarative)API特点,Spark、Storm及Heron基于Python的统计式(Statistical)API特点,Spark及Flink的SQL API特点,并对各框架支持的API类型进行了详细总结:
随后,对各框架间的运行时模型进行了详细介绍,然后就各框架在窗口操作(Window Operation)、无序处理(Out-of-Order Processing)、内存管理(Memory Management)、资源管理(Resource Management)、Web UI及社区成熟度(Community Maturity)等方面进行了详细比较,最后对各框架间的性能进行了比较,并就实际使用场景给出了框架造型参考。
阿里云技术专家余根茂:Hadoop存储与计算分离实践
阿里云E-MapReduce团队的专家余根茂首先讲解了传统集群部署的实践,提到计算能力与存储能力的加成是集群所提供的能力。由于本地磁盘比网络传输快以及任务处理中数据获取开销大,他又强调了数据的本地性,因为计算会找数据,必须以数据为中心。
理想中的集群,会有更少的数据迁移和更高的资源利用率,但现实是带宽逐渐不是稀缺资源,磁盘不再是承载计算的主战场,集群的木桶效应会逐渐导致集群资源的浪费:

随后他提到了阿里云上的集群混合部署带来的新的挑战:1,冷数据不断积累,存储成本比较高;2,存储质量下降;3,数据Balance代价上升,集群维护成本也升高;4,数据服务性的要求越来越高。
而替代的方案是什么呢?余根茂提到了Hadoop+OSS的模式:
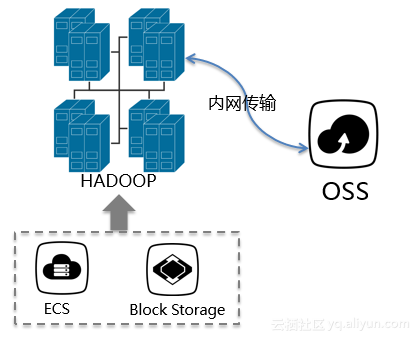
通过对场景的不断优化,不断地提升性能和稳定性,而今年9月份EMR-Core 1.2.0 支持的MetaService,使安全和易用性进一步增强,Hadoop也对OSS小文件和数据仓库做了针对性的优化,使其在读写的性能上表现不俗,几乎与HDFS相当,同时Hadoop+OSS的价格又低于传统的Hadoop+HDFS,只有合理组合才能带来性能和成本的双赢。E-MapReduce整体架构如下:
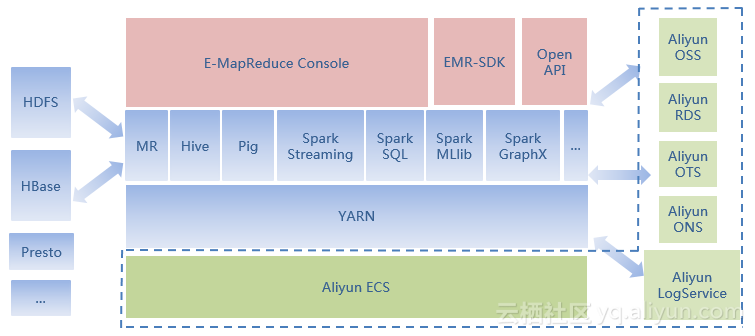
最后,余根茂强调了阿里云的E-MapReduce可为用户提供一站式大数据处理分析服务。
最新文章
- .NET中那些所谓的新语法之四:标准查询运算符与LINQ
- 你所不知道的ref
- C#网站实现QQ第三方登陆# C#快速开发教程
- TCP的流量控制(转载)
- Django学习(二) Django框架简单搭建
- 使用IntelliJ IDEA开发SpringMVC网站(二)开发环境
- CI框架主题切换的功能
- Zepto中的Swipe事件失效
- 权限系统与RBAC模型概述[绝对经典]
- springboot中HandlerMethodArgumentResolver的使用
- flex弹性盒子布局
- 码云IntelliJ IDEA
- mysql 去除重复 Select中DISTINCT关键字的用法 在使用mysql时,有时需要查询出某个字段不重复的记录,虽然mysql提供 有distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只用它来返回不重复记录的条数,而不是用它来返回不重记录的所有值。其原因是 distinct只能返回它的目标字段,而无法返回其它字段,这个问题让我困扰了很久,用distinct不能解决的话,
- netcore sqlserver linq contains生成的sql语句不是使用like而是charIndex
- 如何将Skyline66嵌入WPF中
- MySQL 在各种程序语音的连接字符串(转)
- WPF中自定义路由事件
- 容器启动报iptables错误
- A Package Manager for Xcode -Xcode模板管理工具Alcatraz使用
- Zip文件格式
热门文章
- 解决Sqoop报错Could not load db driver class: com.intersys.jdbc.CacheDriver
- [Android Pro] Android源码编译后,再重编译所需要做的清理工作
- mysql访问权限GRANT ALL PRIVILEGES ON,访问权限表
- C# 编程指南
- Cocos2d-x3.3RC0通过JNI调用Android的Java层URI代码发送短信
- java使用省略号代替多参数(参数类型... 参数名)
- JavaScript字符串数组拼接的性能测试及优化方法
- 巧妙使用div+css模拟表格对角线
- 提高你开发效率的十五个 Visual Studio 使用技巧
- Logistic Regression的几个变种