#Week3 Linear Regression with Multiple Variables
一、Multiple Features
这节课主要引入了一些记号,假设现在有n个特征,那么:
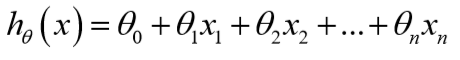
为了便于用矩阵处理,令\(x_0=1\):
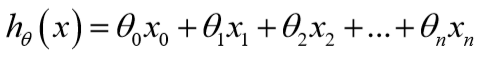
参数\(\theta\)是一个(n+1)*1维的向量,任一个训练样本也是(n+1)*1维的向量,故对于每个训练样本:\(h_\theta(x)=\theta^Tx\)。
二、Gradient Decent for Multiple Variables
类似地,定义代价函数:
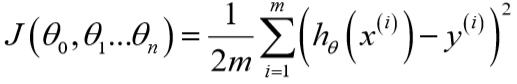
同时更新参数直到\(J\)收敛:
\]
三、Feature Scaling
这些特征的值如果有着近似的尺度,那么梯度下降会收敛得更快,其实就是归一化。
Andrew建议将特征的值缩放到[-1,1]之间:
\]
四、Learning Rate
1、梯度下降收敛所需的迭代次数是不确定的,可以通过绘制迭代次数与\(J\)的图来预测何时收敛;也可以通过代价函数的变化是否小于某个阈值来判断。
2、学习率一般可以尝试0.001,0.003,0.01,0.03,0.1,0.3,1...
五、Features and Polynomial Regression
线性回归有时候并不适用,有时需要多项式回归。
多项式回归可以转化为线性回归。
六、Normal Equation
正规方程通过直接求导,使得导数为0,进而求得\(\theta\)的解析解,使得\(J\)最小,而不需要像梯度下降那样迭代。
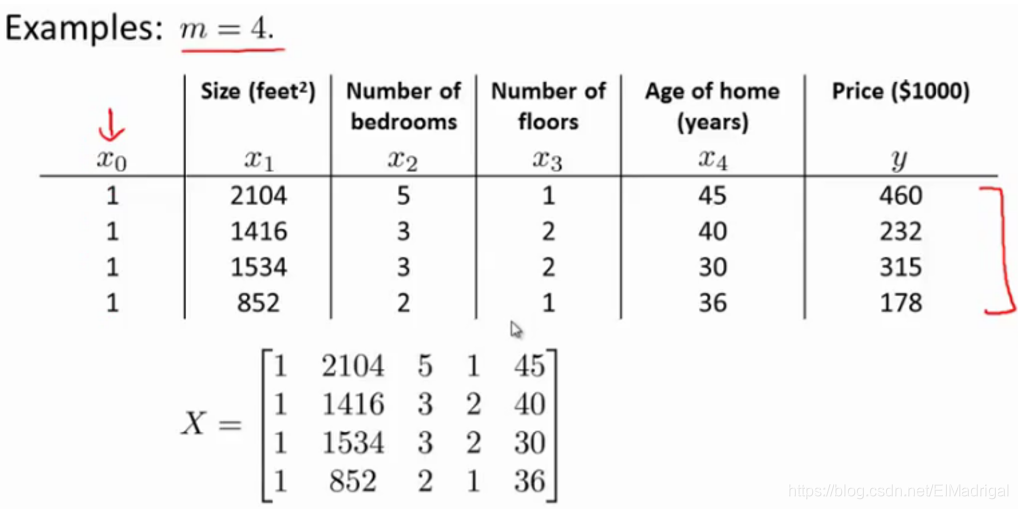
X是m*(n+1)特征矩阵,y是m*1向量,由图容易得出:
\(y=X\theta\)(这公式显然是错的。。。\(y\)只是采集到的标签),解出\(\theta=X^{-1}y\)(所以结论也是错的),这样得到的\(\theta\)显然不能使得损失函数最小。
课程里写成了\(\theta=(X^TX)^{-1}X^Ty\),详细推导是通过对代价函数求导得到的。这个公式不能化简为\(\theta=X^{-1}y\),因为只有\(X^T\)和\(X\)都可逆,才有\((X^TX)^{-1}=X^{-1}(X^T)^{-1}\)。
两种算法的比较:

正规方程只适用于线性模型,而且不需要Feature Scaling。
最新文章
- python 三元运算
- RHEL查看CPU等机器信息
- PHP裁剪图片并上传完整demo
- 由fdopen和fopen想到的
- asp.net系统过滤器、自定义过滤器
- dropdownlist分页
- AngularJS中的控制器示例
- ASP.NET 操作配置文件
- 转:jQuery事件绑定.on()简要概述及应用
- Win7+ubuntu kylin+CentOS 6.5三系统安装图文教程
- ASP.NET 页面之间传值的几种方式
- RoportNG报表显示中文乱码和TestNG显示中文乱码实力解决办法
- Java基础笔记4
- PHP UEditor富文本编辑器 显示 后端配置项没有正常加载,上传插件不能正常使用
- SQL Server 批量插入
- 语音通信中终端上的时延(latency)及减小方法
- Spring学习1:Spring基本特性
- luogu P4403 [BJWC2008]秦腾与教学评估
- iOS UI基础-18.0 UIView
- 利用Jquery和fullCalendar制作日程表