Pytorch_Part7_模型使用
VisualPytorch beta发布了!
功能概述:通过可视化拖拽网络层方式搭建模型,可选择不同数据集、损失函数、优化器生成可运行pytorch代码
扩展功能:1. 模型搭建支持模块的嵌套;2. 模型市场中能共享及克隆模型;3. 模型推理助你直观的感受神经网络在语义分割、目标探测上的威力;4.添加图像增强、快速入门、参数弹窗等辅助性功能
修复缺陷:1.大幅改进UI界面,提升用户体验;2.修改注销不跳转、图片丢失等已知缺陷;3.实现双服务器访问,缓解访问压力
访问地址:http://sunie.top:9000
发布声明详见:https://www.cnblogs.com/NAG2020/p/13030602.html
共同贡献PyTorch常见错误与坑汇总文档:《PyTorch常见报错/坑汇总》
一、模型保存与加载
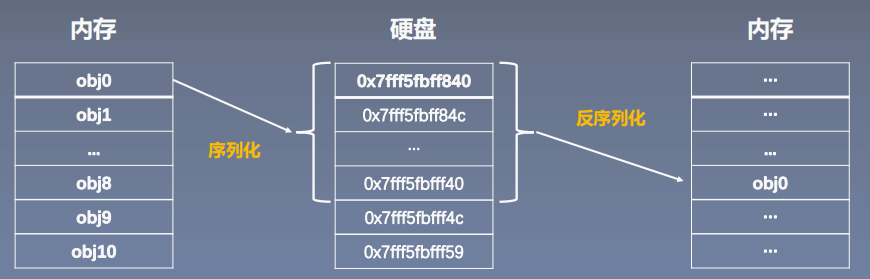
1. 序列化与反序列化
net = LeNet2(classes=2019)
# 法1: 保存整个Module,不仅保存参数,也保存结构
torch.save(net, path)
net_load = torch.load(path_model) # 网络名称、结构、模型参数、优化器参数均保留
# 法2: 保存模型参数(推荐,占用资源少)
state_dict = net.state_dict()
torch.save(state_dict , path)
net_new = LeNet2(classes=2019)
net_new.load_state_dict(state_dict_load)
2. 断点续训练
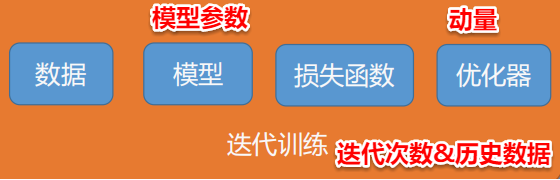
保存:
checkpoint = {
"model_state_dict": net.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"epoch": epoch
}
path_checkpoint = "./checkpoint_{}_epoch.pkl".format(epoch)
torch.save(checkpoint, path_checkpoint)
恢复:
# ============================ step 2/5 模型 ============================
net = LeNet(classes=2)
net.initialize_weights()
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss() # 选择损失函数
# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=6, gamma=0.1) # 设置学习率下降策略
# ============================ step 5+/5 断点恢复 ============================
path_checkpoint = "./checkpoint_4_epoch.pkl"
checkpoint = torch.load(path_checkpoint)
net.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
scheduler.last_epoch = checkpoint['epoch']
二、模型微调(Finetune)
1. Transfer Learning
机器学习分支,研究源域(source domain)的知识如何应用到目标域(target domain)
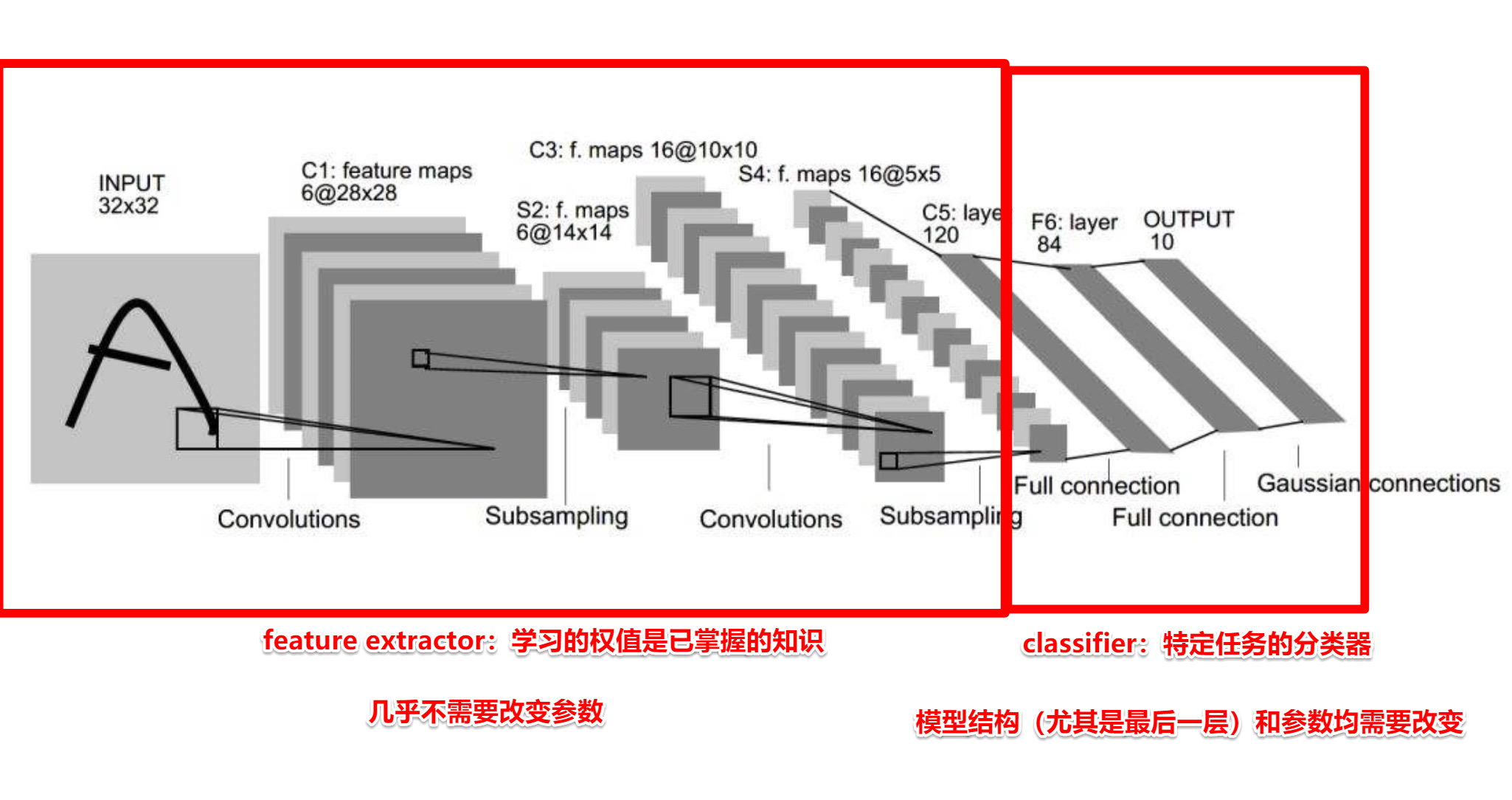
模型微调步骤:
- 获取预训练模型参数
- 加载模型(load_state_dict)
- 修改输出层
模型微调训练方法:
- 固定预训练的参数(requires_grad =False;lr=0)
- Features Extractor较小学习率(params_group)[推荐使用,更加灵活]
3. 将resnet18迁移
到蚂蚁-蜜蜂二分类任务,其中有114张训练,80张测试。可以看出来训练数据还是相当小的,必须有已经训练好的模型。
模型搭建如下:
# ============================ step 2/5 模型 ============================
# 1/3 构建模型
resnet18_ft = models.resnet18()
# 2/3 加载参数 !!!
path_pretrained_model = "resnet18-5c106cde.pth"
state_dict_load = torch.load(path_pretrained_model)
resnet18_ft.load_state_dict(state_dict_load)
# 法1 : 冻结卷积层,模型参数不再更新
for param in resnet18_ft.parameters():
param.requires_grad = False
# 3/3 替换fc层,将原本输出神经元个数改为 classes = 2 !!!
num_ftrs = resnet18_ft.fc.in_features
resnet18_ft.fc = nn.Linear(num_ftrs, classes)
如果不加载参数,训练了25个epoch仍只有70%正确率,最后Loss保持在0.5左右。而如果加载了参数,基本上第二个epoch就达到90%正确率。
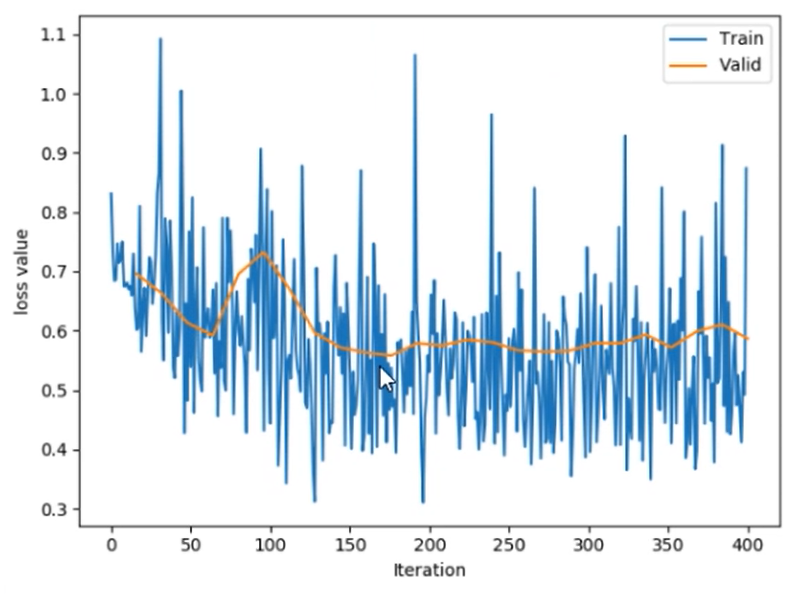
更推荐的用优化器控制学习率方法:分组灵活控制LR
# ============================ step 4/5 优化器 ============================
# 法2 : conv 小学习率
fc_params_id = list(map(id, resnet18_ft.fc.parameters())) # 返回的是parameters的 内存地址
base_params = filter(lambda p: id(p) not in fc_params_id, resnet18_ft.parameters())
optimizer = optim.SGD([
{'params': base_params, 'lr': LR*0.1}, # 0
{'params': resnet18_ft.fc.parameters(), 'lr': LR}], momentum=0.9)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=lr_decay_step, gamma=0.1) # 设置学习率下降策略
三、GPU的使用
CPU(Central Processing Unit, 中央处理器):主要包括控制器和运算器
GPU(Graphics Processing Unit, 图形处理器):处理统一的,无依赖的大规模数据运算
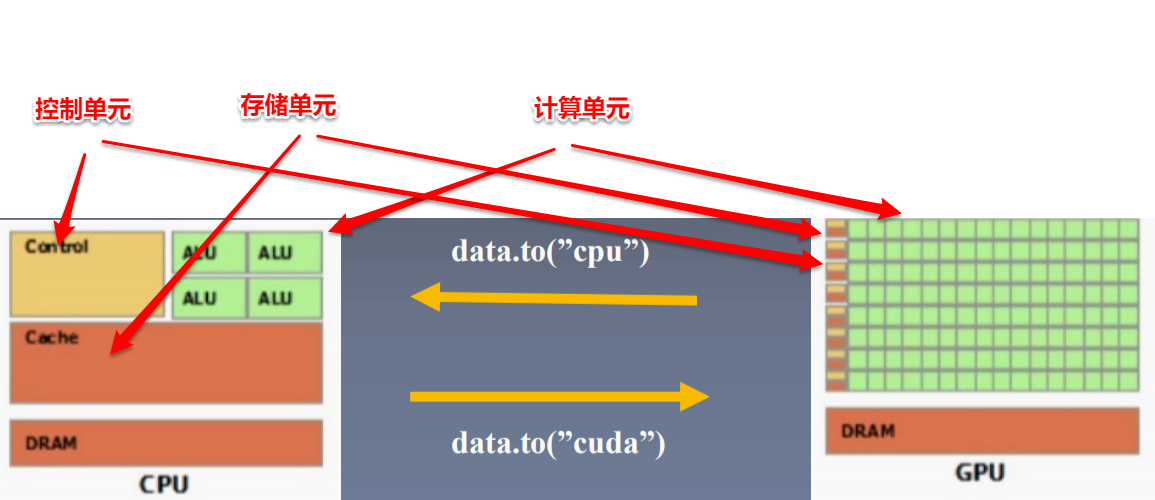
在模型训练/测试时必须使所有数据和模型参数都在同一类设备上,并且注意数据的to操作不是inplace操作。
经过实验,上面resnet18的迁移学习中,如果不采用GPU训练一个epoch耗时58.362s,而使用了GPU后仅需要6.626s!
1. to函数:转换数据类型/设备
- tensor.to(*args, **kwargs)
- module.to(*args, **kwargs)
区别:张量不执行inplace,模型执行inplace
x = torch.ones((3, 3))
x = x.to(torch.float64) # 数据类型
x = torch.ones((3, 3))
x = x.to("cuda") # 数据设备
linear = nn.Linear(2, 2)
linear.to(torch.double) # 模型数据类型,不改变存储位置
gpu1 = torch.device("cuda")
linear.to(gpu1) # 模型设备,不改变存储位置
2. torch.cuda常用方法
- torch.cuda.device_count():计算当前可见可用gpu数
- torch.cuda.get_device_name():获取gpu名称
- torch.cuda.manual_seed():为当前gpu设置随机种子
- torch.cuda.manual_seed_all():为所有可见可用gpu设置随机种子
- torch.cuda.set_device():设置主gpu为哪一个物理gpu(不推荐)
推荐: os.environ.setdefault("CUDA_VISIBLE_DEVICES", "2, 3")
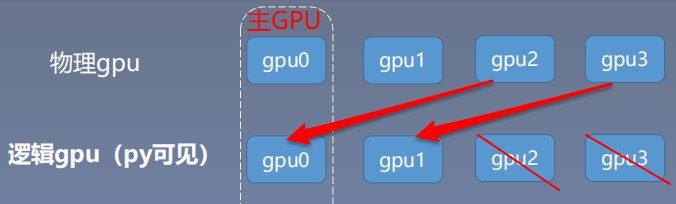
3. 多gpu运算的分发并行机制
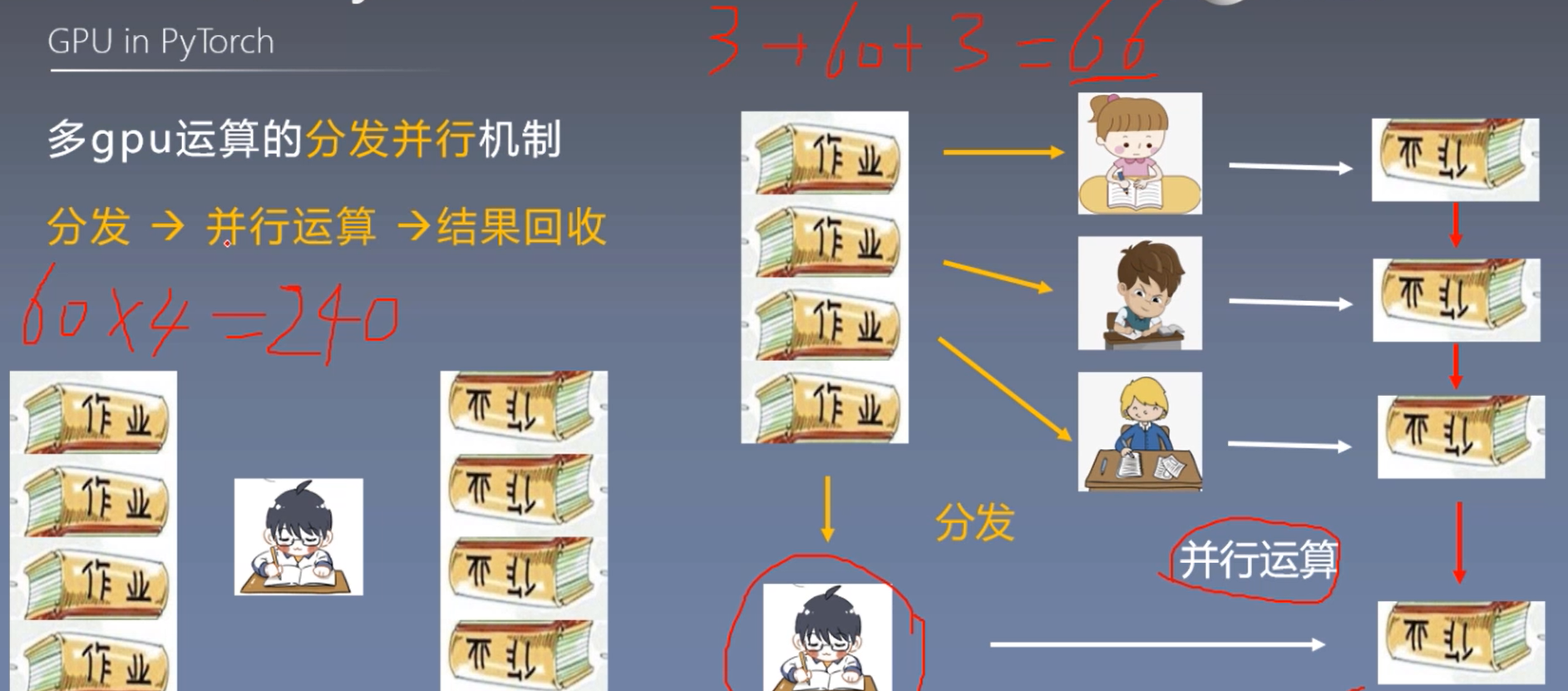
torch.nn.DataParallel(module, # 需要包装分发的模型
device_ids=None, # 可分发的gpu,默认分发到所有可见可用gpu
output_device=None, # 结果输出设备
dim=0
)
功能:包装模型,实现分发并行机制
查询当前gpu内存剩余:
def get_gpu_memory():
import os
os.system('nvidia-smi -q -d Memory | grep -A4 GPU | grep Free > tmp.txt')
memory_gpu = [int(x.split()[2]) for x in open('tmp.txt', 'r').readlines()]
os.system('rm tmp.txt')
return memory_gpu
gpu_memory = get_gpu_memory()
gpu_list = np.argsort(gpu_memory)[::-1]
gpu_list_str = ','.join(map(str, gpu_list))
os.environ.setdefault("CUDA_VISIBLE_DEVICES", gpu_list_str)
print("\ngpu free memory: {}".format(gpu_memory))
print("CUDA_VISIBLE_DEVICES :{}".format(os.environ["CUDA_VISIBLE_DEVICES"]))
>>> gpu free memory: [10362, 10058, 9990, 9990]
>>> CUDA_VISIBLE_DEVICES :0,1,3,2
gpu模型加载:
在没有GPU的机器上运行GPU代码:
RuntimeError: Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False...
解决:
torch.load(path_state_dict, map_location="cpu")在单GPU机器上加载多GPU训练模型参数(在参数key中会含有
module.)RuntimeError: Error(s) in loading state_dict for FooNet: Missing key(s) in state_dict: "linears.0.weight", "linears.1.weight", "linears.2.weight". Unexpected key(s) in state_dict: "module.linears.0.weight", "module.linears.1.weight", "module.linears.2.weight".
解决:
from collections import OrderedDict
new_state_dict = OrderedDict()
for k, v in state_dict_load.items ():
namekey = k[7:] if k.startswith('module.') else k
new_state_dict[namekey] =v
最新文章
- 用 string 进行插入、替代、查找输出下标等操作
- asp.net 网站开发流程总结
- 32位Windows7上8G内存使用感受+xp 32位下使用8G内存 (转)
- ViewPager设置 缓存个数、页卡间距、数据更新
- UIApplication相关
- CSDN markdown 编辑 三 基本语法
- 命令模式 & 策略模式 & 模板方法
- 【css3网页布局】flex盒子模型
- Postgres中表和元组的组织方式
- 爱奇艺2018春招Java工程师编程题题解
- Ubuntu命令操作
- LOJ #2116 Luogu P3241「HNOI2015」开店
- Penettation testing with the bush Shell
- 【慕课网实战】九、以慕课网日志分析为例 进入大数据 Spark SQL 的世界
- Spring MVC请求处理流程
- at android.view.Surface.unlockCanvasAndPost(Native Method)
- luogu2831 [NOIp2016]愤怒的小鸟 (状压dp)
- PHP浮点数的精确计算BCMath
- 180623、Git新建远程分支和删除
- git获取一个版本相对于另一个版本新增,修改,删除的文件