python爬取千库网
2024-10-09 16:10:31
url:https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/
有水印
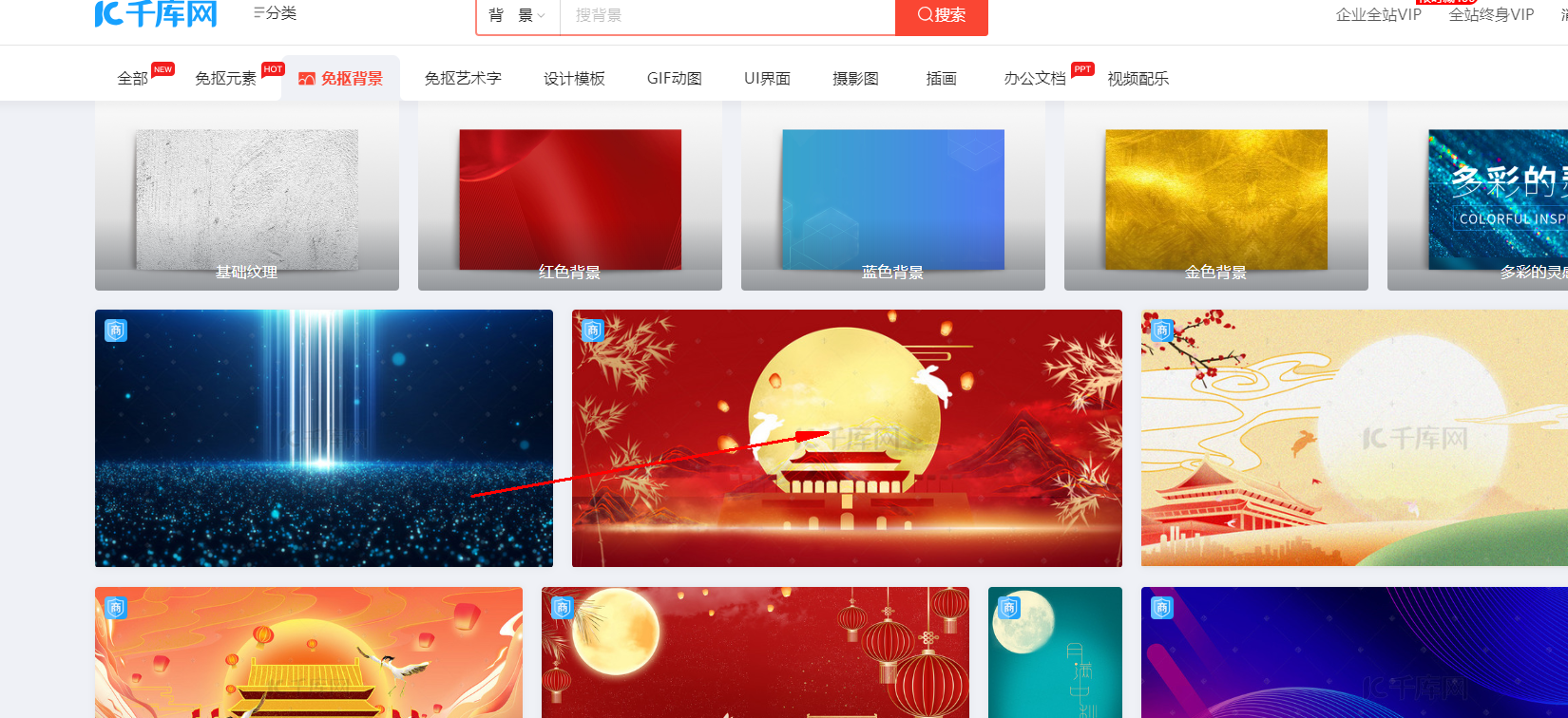
但是点进去就没了
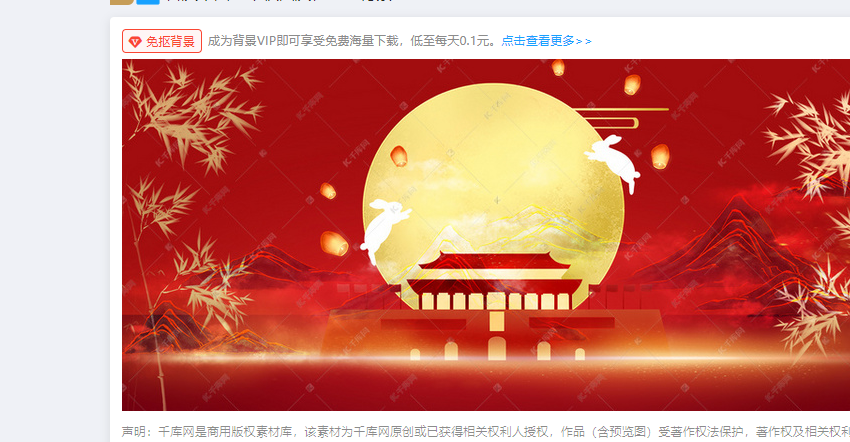
这里先来测试是否有反爬虫
import requests
from bs4 import BeautifulSoup
import os
html = requests.get('https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/')
print(html.text)
输出是404,添加个ua头就可以了
可以看到每个图片都在一个div class里面,比如fl marony-item bglist_5993476,是3个class但是最后一个编号不同就不取
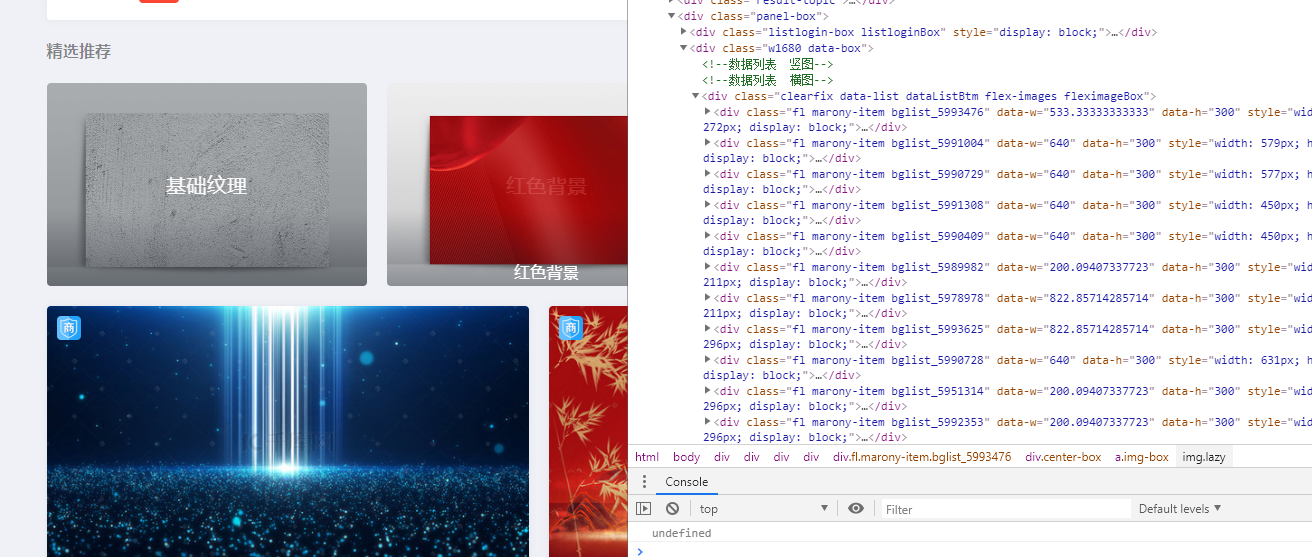
我们就可以获取里面的url
import requests
from bs4 import BeautifulSoup
import os
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
html = requests.get('https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/',headers=headers)
soup = BeautifulSoup(html.text,'lxml')
Urlimags = soup.select('div.fl.marony-item div a')
for Urlimag in Urlimags:
print(Urlimag['href'])
输出结果为
//i588ku.com/ycbeijing/5993476.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5991004.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5990729.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5991308.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5990409.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5989982.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5978978.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5993625.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5990728.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5951314.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5992353.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5993626.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5992302.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5820069.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5804406.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5960482.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5881533.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5986104.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5956726.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5986063.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5978787.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5954475.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5959200.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5973667.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5850381.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5898111.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5924657.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5975496.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5928655.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5963925.html
//i588ku.com/comnew/vip/
这个/vip是广告,过滤一下
for Urlimag in Urlimags:
if 'vip' in Urlimag['href']:
continue
print('http:'+Urlimag['href'])
然后用os写入本地
import requests
from bs4 import BeautifulSoup
import os
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
html = requests.get('https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/',headers=headers)
soup = BeautifulSoup(html.text,'lxml')
Urlimags = soup.select('div.fl.marony-item div a')
for Urlimag in Urlimags:
if 'vip' in Urlimag['href']:
continue
# print('http:'+Urlimag['href'])
imgurl = requests.get('http:'+Urlimag['href'],headers=headers)
imgsoup = BeautifulSoup(imgurl.text,'lxml')
imgdatas = imgsoup.select_one('.img-box img')
title = imgdatas['alt']
print('无水印:','https:'+imgdatas['src'])
if not os.path.exists('千图网图片'):
os.mkdir('千图网图片')
with open('千图网图片/{}.jpg'.format(title),'wb')as f:
f.write(requests.get('https:'+imgdatas['src'],headers=headers).content)
然后我们要下载多页,先看看url规则
第一页:https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/
第二页:https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-2/
import requests
from bs4 import BeautifulSoup
import os
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
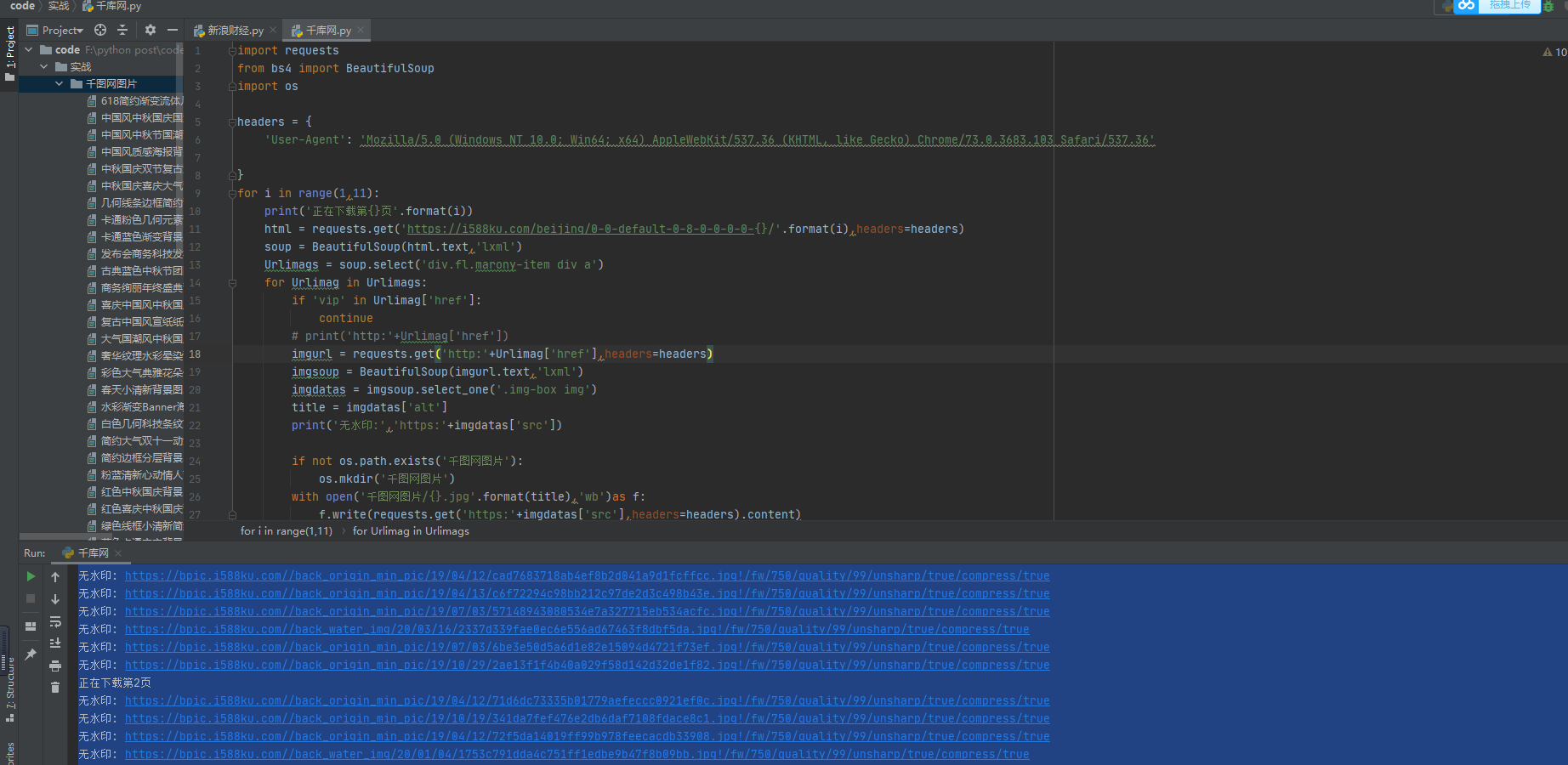
for i in range(1,11):
print('正在下载第{}页'.format(i))
html = requests.get('https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-{}/'.format(i),headers=headers)
soup = BeautifulSoup(html.text,'lxml')
Urlimags = soup.select('div.fl.marony-item div a')
for Urlimag in Urlimags:
if 'vip' in Urlimag['href']:
continue
# print('http:'+Urlimag['href'])
imgurl = requests.get('http:'+Urlimag['href'],headers=headers)
imgsoup = BeautifulSoup(imgurl.text,'lxml')
imgdatas = imgsoup.select_one('.img-box img')
title = imgdatas['alt']
print('无水印:','https:'+imgdatas['src'])
if not os.path.exists('千图网图片'):
os.mkdir('千图网图片')
with open('千图网图片/{}.jpg'.format(title),'wb')as f:
f.write(requests.get('https:'+imgdatas['src'],headers=headers).content)
最新文章
- 使用django开发博客过程记录2——博客首页及博客详情的实现
- PHP 过滤器
- springboot 的dataSource 一些配置
- Jenkins安装与基本配置
- sqoop将关系型数据库的表导入hive中
- 记录Hibernate的缓存知识
- Hbase之取出行数据指定部分+版本控制(类似MySQL的Limit)
- uestc 1720无平方因子数
- 零基础学Python 3之环境准备
- Python基础类型
- iosTableView 局部全部刷新以及删除编辑操作
- 分针网—每日分享: 怎么轻松学习JavaScript
- mysql 多列索引的生效规则
- 51nod 1752 哈希统计
- python+opencv读取视频,调用摄像头
- Flask-Migrate
- 版本控制工具Git工具快速入门-Windows篇
- Ajax_Json
- SSE sqrt还是比C math库的sqrtf快了不少
- 一些 Linux 常用命令说明