SparkSQL学习进度9-SQL实战案例
Spark SQL 基本操作
将下列 JSON 格式数据复制到 Linux 系统中,并保存命名为 employee.json。
{ "id":1 , "name":" Ella" , "age":36 }
{ "id":2, "name":"Bob","age":29 }
{ "id":3 , "name":"Jack","age":29 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":5 , "name":"Damon" }
{ "id":5 , "name":"Damon" }
为 employee.json 创建 DataFrame,并写出 Scala 语句完成下列操作:
(1) 查询所有数据;
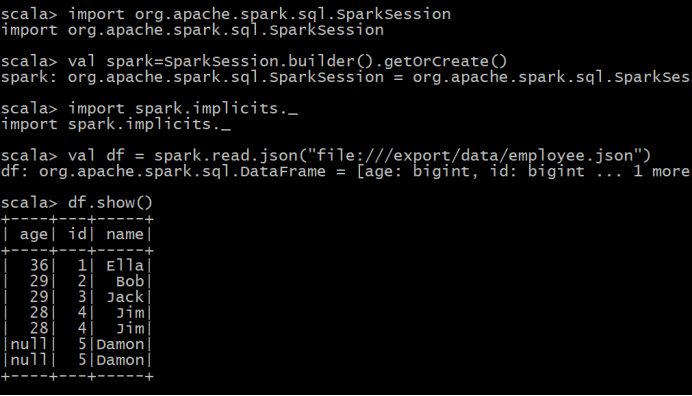
(2) 查询所有数据,并去除重复的数据;
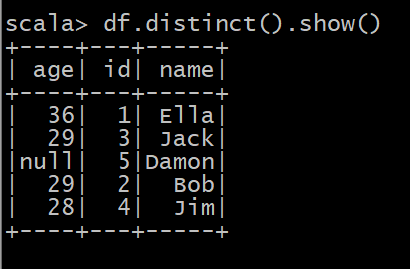
(3) 查询所有数据,打印时去除 id 字段;

(4) 筛选出 age>30 的记录;

(5) 将数据按 age 分组;

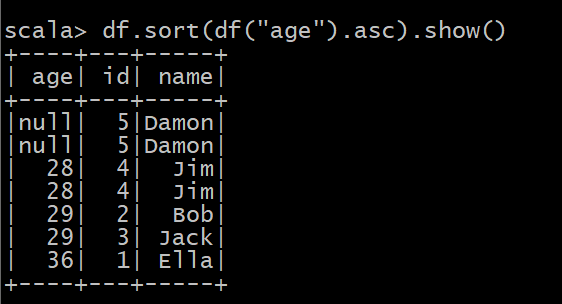
(6) 将数据按 name 升序排列;
(7) 取出前 3 行数据;

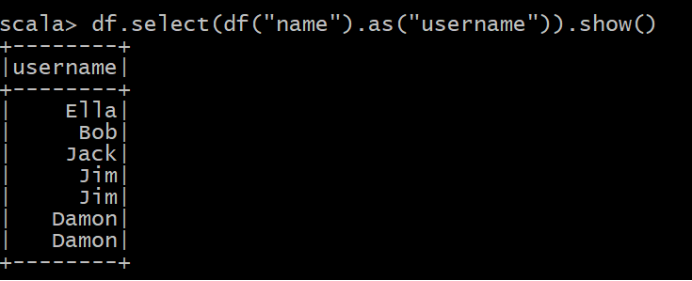
(8) 查询所有记录的 name 列,并为其取别名为 username;
(9) 查询年龄 age 的平均值;
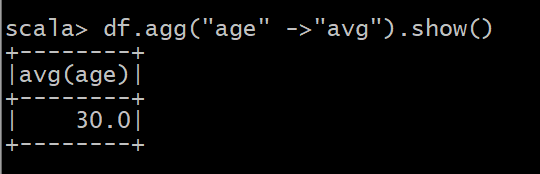
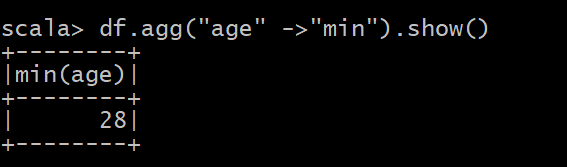
(10) 查询年龄 age 的最小值。
编程实现将 RDD 转换为 DataFrame
源文件内容如下(包含 id,name,age):
1,Ella,36
2,Bob,29
3,Jack,29
请将数据复制保存到 Linux 系统中,命名为 employee.txt,实现从 RDD 转换得到DataFrame,并按“id:1,name:Ella,age:36”的格式打印出 DataFrame 的所有数据。请写出程序代码。
package cn.itcast.spark.mook import org.apache.spark.sql.SparkSession
import org.junit.Test class RDDtoDataFrame { @Test
def test(): Unit ={
val spark=SparkSession.builder()
.appName("datafreame1")
.master("local[6]")
.getOrCreate() import spark.implicits._
val df=spark.sparkContext.textFile("dataset/employee.txt").map(_.split(","))
.map(item => Employee(item(0).trim.toInt,item(1),item(2).trim.toInt))
.toDF()
df.createOrReplaceTempView("employee")
val dfRDD=spark.sql("select * from employee")
dfRDD.map(it => "id:"+it(0) +",name:"+it(1)+",age:"+it(2) )
.show()
}
}
case class Employee(id:Int,name:String,age:Long)

编程实现利用 DataFrame 读写 MySQL 的数据
(1)在 MySQL 数据库中新建数据库 sparktest,再创建表 employee,包含如表 6-2 所示的两行数据。
表 6-2 employee 表原有数据
id name gender Age
1 Alice F 22
2 John M 25

(2)配置 Spark 通过 JDBC 连接数据库 MySQL,编程实现利用 DataFrame 插入如表 6-3 所示的两行数据到 MySQL 中,最后打印出 age 的最大值和 age 的总和。
表 6-3 employee 表新增数据
id name gender age
3 Mary F 26
4 Tom M 23
package cn.itcast.spark.mook
import org.apache.spark.sql.{SaveMode, SparkSession}
import org.apache.spark.sql.types.{FloatType, IntegerType, StringType, StructField, StructType}
object MysqlOp {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("mysql example")
.master("local[6]")
.getOrCreate()
val schema = StructType(
List(
StructField("id", IntegerType),
StructField("name", StringType),
StructField("gender", StringType),
StructField("age", IntegerType)
)
)
val studentDF = spark.read
//分隔符:制表符
.option("delimiter", ",")
.schema(schema)
.csv("dataset/stu")
studentDF.write
.format("jdbc")
.mode(SaveMode.Append)
.option("url", "jdbc:mysql://hadoop101:3306/spark02")
.option("dbtable", "employee")
.option("user", "spark")
.option("password", "fengge666")
.save()
spark.read
.format("jdbc")
.option("url", "jdbc:mysql://hadoop101:3306/spark02")
.option("dbtable","(select max(age),SUM(age) from employee) as emp")
.option("user", "spark")
.option("password", "fengge666")
.load()
.show()
}
}
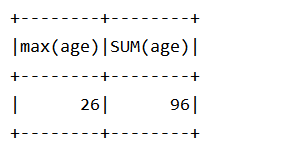
最新文章
- AWS助理架构师样题解析
- Sizeof运算符小结
- Keep Alive
- VMware Workstation 12 Pro虚拟机下载(含序列号)
- 关于oracle误删数据的恢复
- Python几个算法实现
- 【转载】java数据库操作
- C# winform 弹出输入框
- dedecms织梦建站总结
- iOS10适配——错误:Code=3000
- 隐藏index.php
- Apache Spark 章节1
- [JAVA]字节数组流
- p132代码解析
- 深入理解Aspnet Core之Identity(1)
- golang struct转map
- lucene 学习一
- AVL树插入(Python实现)
- aes并发加密Cipher not initialized 异常
- Action方法调用