HDFS 客户端读写操作详情
2024-08-28 07:24:06
1. 写操作

- 客户端向namenode发起上传请求
- namenode检查datanode是否已经存有该文件,并且检查客户端的权限
- 确认可以上传后,根据文件块数返回datanode栈
注:namenode触发副本放置策略,如果客户端在集群内的某一台机器,那么副本第一块放置在该服务器上,然后再另外挑两台服务器;如果在集群外,namenode会根据策略先找一个机架选出一个datanode,然后再从另外的机架选出另外两个datanode,然后namenode会将选出的三个datanode按距离组建一个顺序,然后将顺序返回给客户端- 客户端pop()栈顶的第一个节点,建立socket连接,然后第一个节点与第二个节点,第二个节点与第三个节点...依次建立socket连接
- datanode反顺序依次应答,直到应答给客户端
注:如果有datanode没有应答,客户端重新向namenode请求- 客户端向datanode上传文件块
- 上传文件块后,各datanode会通过心跳将位置信息汇报给namenode
注:如果上传文件块时,某个datanode节点挂掉了,该节点的上节点直接连接该节点的下游节点继续传输,最终在第7步汇报后,namenode会发现副本数不足,触发datanode复制更多副本- 客户端重复上传操作,逐一将文件块上传,同时dataNode汇报块的位置信息,时间线重叠
- 所有块上传完毕后,namenode将所有信息存在元数据中,客户端关闭输出流
2. 读操作
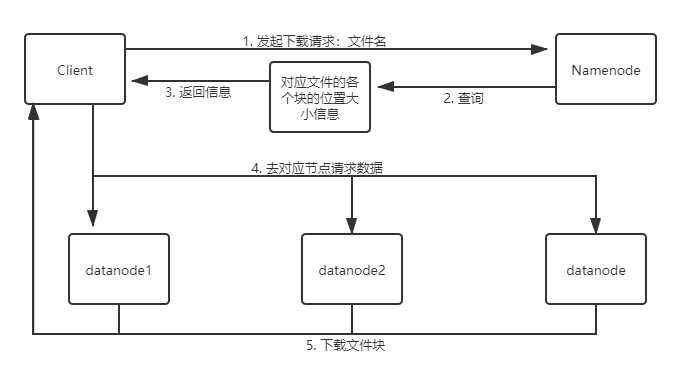
- 用户操作客户端查看文件,客户端带着文件名向namenode发起下载请求
- namenode在元数据中查找该文件对应各个块的大小位置信息,返回给客户端
- namenode向位置datanode节点发起下载请求
- datanode向客户端传输块数据
- 客户端下载完成所有块后会验证datanode中的MD5,保证块数据的完整性,最后关闭输入流
3. 读写过程中的数据单位
3.1 block
文件上传前需要分块,这个块就是block,一般为128MB。因为块太小:寻址时间占比过高。块太大:Map任务数太少,作业执行速度变慢。它是最大的一个单位。
3.2 packet
packet是第二大的单位,它是client端向datanode,或datanode的PipLine之间传数据的基本单位,默认64KB。
3.3 chunk
chunk是最小的单位,它是client向datanode,或datanode的PipLine之间进行数据校验的基本单位,默认512Byte,因为用作校验,故每个chunk需要带有4Byte的校验位。所以实际每个chunk写入packet的大小为516Byte。由此可见真实数据与校验值数据的比值约为128 : 1。(即64*1024 / 512)
最新文章
- Oracle 11g数据库详细安装步骤图解
- 对Live Writer支持的继续改进:设置随笔地址别名(EntryName)
- PHP / JavaScript / jQuery 表单验证与处理总结: 第①部分 PHP 表单验证与处理
- Oracle if else if for case
- SSL 通信及 java keystore 工具介绍
- XJOI网上同步训练DAY6 T2
- java classpath import package 机制 @Java的ClassPath, Package和Jar
- webpack中实现按需加载
- minecraft初探
- LeetCode - 804. Unique Morse Code Words
- flink入门
- python-面向对象-12_模块和包
- JS实现图片的淡入和淡出的两种方法,如有不足,还请前辈多多指导^-^~
- lua协程----ngx-lua线程学习笔记
- SQLAlchemy数据库连接和初始化数据库
- Cocostudio学习笔记(2) Button + CheckBox
- [Codeup 25481] swan
- C# 基于正则表达式的字符串验证
- List多个字段标识过滤
- jqGrid方法整理