The art of multipropcessor programming 读书笔记-硬件基础1
本系列是 The art of multipropcessor programming 的读书笔记,在原版图书的基础上,结合 OpenJDK 11 以上的版本的代码进行理解和实现。并根据个人的查资料以及理解的经历,给各位想更深入理解的人分享一些个人的资料
硬件基础
首先,我们无需掌握大量的底层计算机系统结构设计知识的细节,如果大家对于计算机系统结构非常感兴趣,那么我非常推荐大家搜一下 CSE 502 Computer Architecture 的课件,我看了这门课的 CPU 和 缓存章节,受益匪浅。这里列出的硬件基础知识,主要为了能让我们理解编程语言为了提高性能做的设计。
我们一般能轻松写出来适合单处理器运行的代码,但是面对多处理器的情况,可能同样的代码效率就低很多,请看下面这个例子:假设两个线程需要访问一个资源,这个资源不能被多线程同时访问,访问前必须上锁,拿到锁之后才能访问这个资源,并且需要在访问完资源后释放锁。
我们这里使用一个 boolean 域实现锁,如果这个 boolean 为 false 则锁是空闲状态,否则就是正在被使用。使用 compareAndSet 来获取锁,这个调用返回 true 就是修改成功,即获取锁成功,返回 false 则修改失败,即获取锁失败。假设我们有如下这个锁的接口:
public interface Lock {
void lock();
void unlock();
}
对于这个锁,我们有以下两种实现,第一个是:
import java.lang.invoke.MethodHandles;
import java.lang.invoke.VarHandle;
public class TASLock implements Lock {
private boolean locked = false;
//操作 lock 的句柄
private static final VarHandle LOCKED;
static {
try {
//初始化句柄
LOCKED = MethodHandles.lookup().findVarHandle(TASLock.class, "locked", boolean.class);
} catch (Exception e) {
throw new Error(e);
}
}
@Override
public void lock() {
// compareAndSet 成功代表获取了锁
while(!LOCKED.compareAndSet(this, false, true)) {
//让出 CPU 资源,这是目前实现 SPIN 效果最好的让出 CPU 的方式,当线程数量远大于 CPU 数量时,效果比 Thread.yield 好,从及时性角度效果远好于 Thread.sleep
Thread.onSpinWait();
}
}
@Override
public void unlock() {
//需要 volatile 更新,让其他线程感知到
LOCKED.setVolatile(this, false);
}
}
另一个锁的实现是:
public class TTASLock implements Lock {
private boolean locked = false;
//操作 locked 的句柄
private static final VarHandle LOCKED;
static {
try {
//初始化句柄
LOCKED = MethodHandles.lookup().findVarHandle(TTASLock.class, "locked", boolean.class);
} catch (Exception e) {
throw new Error(e);
}
}
@Override
public void lock() {
while (true) {
//普通读取 locked,如果被占用,则一直 SPIN
while ((boolean) LOCKED.get(this)) {
//让出 CPU 资源,这是目前实现 SPIN 效果最好的让出 CPU 的方式,当线程数量远大于 CPU 数量时,效果比 Thread.yield 好,从及时性角度效果远好于 Thread.sleep
Thread.onSpinWait();
}
//成功代表获取了锁
if (LOCKED.compareAndSet(this, false, true)) {
return;
}
}
}
@Override
public void unlock() {
LOCKED.setVolatile(this, false);
}
}
为了灵活性和统一,我们两个锁都是使用了句柄,而不是 volatile 变量或者是 AtomicBoolean,因为我们在这两个锁中会有 volatile 更新,普通读取,以及原子更新;如果读者不习惯,可以使用 AtomicBoolean 近似代替。
接下来我们使用 JMH 测试这两个锁的性能以及有效性,我们将一个 int 类型的变量使用多线程加 500 万次,并且使用我们实现的这两个锁确保并发安全,查看耗时。
//测试指标为单次调用时间
@BenchmarkMode(Mode.SingleShotTime)
//需要预热,排除 jit 即时编译以及 JVM 采集各种指标带来的影响,由于我们单次循环很多次,所以预热一次就行
@Warmup(iterations = 1)
//单线程即可
@Fork(1)
//测试次数,我们测试10次
@Measurement(iterations = 10)
//定义了一个类实例的生命周期,所有测试线程共享一个实例
@State(value = Scope.Benchmark)
public class Test {
private static class ValueHolder {
int count = 0;
}
//测试不同线程数量
@Param(value = {"1", "2", "5", "10", "20", "50", "100"})
private int threadsCount;
@Benchmark
public void testTASLock(Blackhole blackhole) throws InterruptedException {
test(new TASLock());
}
@Benchmark
public void testTTASLock(Blackhole blackhole) throws InterruptedException {
test(new TTASLock());
}
private void test(Lock lock) throws InterruptedException {
ValueHolder valueHolder = new ValueHolder();
Thread[] threads = new Thread[threadsCount];
//测试累加 5000000 次
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < 5000000 / threads.length; j++) {
lock.lock();
try {
valueHolder.count++;
} finally {
lock.unlock();
}
}
});
threads[i].start();
}
for (int i = 0; i < threads.length; i++) {
threads[i].join();
}
if (valueHolder.count != 5000000) {
throw new RuntimeException("something wrong in lock implementation");
}
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder().include(Test.class.getSimpleName()).build();
new Runner(opt).run();
}
}
结果是:
Benchmark (threadsCount) Mode Cnt Score Error Units
Test.testTASLock 1 ss 10 0.087 ± 0.012 s/op
Test.testTASLock 2 ss 10 0.380 ± 0.145 s/op
Test.testTASLock 5 ss 10 0.826 ± 0.310 s/op
Test.testTASLock 10 ss 10 1.698 ± 0.563 s/op
Test.testTASLock 20 ss 10 2.897 ± 0.699 s/op
Test.testTASLock 50 ss 10 5.448 ± 2.513 s/op
Test.testTASLock 100 ss 10 7.900 ± 5.011 s/op
Test.testTTASLock 1 ss 10 0.083 ± 0.003 s/op
Test.testTTASLock 2 ss 10 0.353 ± 0.067 s/op
Test.testTTASLock 5 ss 10 0.543 ± 0.123 s/op
Test.testTTASLock 10 ss 10 0.743 ± 0.356 s/op
Test.testTTASLock 20 ss 10 1.437 ± 0.161 s/op
Test.testTTASLock 50 ss 10 1.926 ± 0.769 s/op
Test.testTTASLock 100 ss 10 2.428 ± 0.878 s/op
可以看出,这两个锁虽然逻辑上是等价的,但是性能上确有很大差异,并且随着线程的增加,这个差异越来越大,如下图所示:
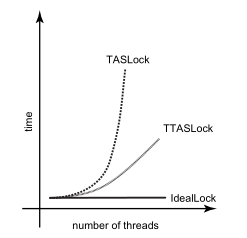
本章为了解释这个问题,会涵盖要写出高效的并发算法和数据结构所需要的关于多处理器系统结构的大多数知识。我们会考虑如下这些组件:
- 处理器(processors):执行软件线程(threads)的设备。通常情况下,线程数远大于处理器个数,处理器需要切换,即运行一个线程一段时间之后切换到另一个线程运行。
- 互连线(interconnect):连接处理器与处理器或者处理器与内存。
- 内存(memory):具有层次的存储数据的组件,包括多层高速缓存和速度相对较慢的大容量主内存。理解这些层次之间的相互关系是理解许多并发算法实际性能的基础。
最新文章
- Leetcode jump Game II
- [转载]给IT人员支招:如何跟业务部门谈需求分析?
- Android 工程师如何快速学会web前段
- 简明python教程 --C++程序员的视角(一):数值类型、字符串、运算符和控制流
- sql查询行转列
- ContentProvider与ContentResolver使用
- debian安装mysql
- (jQuery||Zepto).extend 的一个小问题
- 虎说:bootstrap源码解读(重置模块)
- C语言之形参和实参
- [ An Ac a Day ^_^ ][kuangbin带你飞]专题八 生成树 POJ 1679 The Unique MST
- Entity Framework细节追踪
- scala和java的区别
- js基本包装类型和引用类型
- Linux---基础指令(一)
- 15、JDBC-CallableStatement
- hust 1010 The Minimum Length(循环节)【KMP】
- 【LeetCode每天一题】Pascal's Triangle(杨辉三角)
- docker build 指定dockerfile
- Linux 下升级python和安装pip