064 SparkStream与kafka的集成,主要是编程
这里面包含了如何在kafka+sparkStreaming集成后的开发,也包含了一部分的优化。
一:说明
1.官网
指导网址:http://spark.apache.org/docs/1.6.1/streaming-kafka-integration.html

2.SparkStream+kafka
Use Receiver
内部使用kafka的high lenel consumer API
consumer offset 只能保持到zk/kafka中,只能通过配置进行offset的相关操作
Direct
内部使用的是kafka的simple consumer api
自定义对kafka的offset偏移量进行控制操作
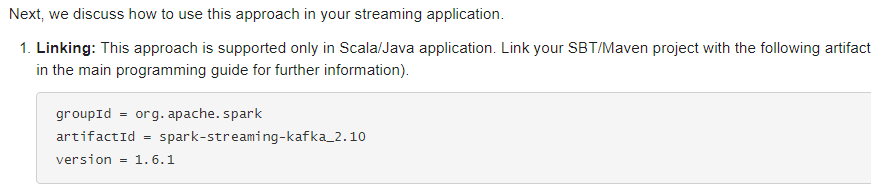
集成依赖pom配置:
二:单Receiver的程序
1.先启动服务
在这里需要启动kafka的生产者
2.程序
package com.stream.it import kafka.serializer.StringDecoder
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext} object KafkaWordcount {
def main(args: Array[String]): Unit = {
val conf=new SparkConf()
.setAppName("spark-streaming-wordcount")
.setMaster("local[*]")
val sc=SparkContext.getOrCreate(conf)
val ssc=new StreamingContext(sc,Seconds(15)) /*
def createStream[K: ClassTag, V: ClassTag, U <: Decoder[_]: ClassTag, T <: Decoder[_]: ClassTag](
ssc: StreamingContext,
kafkaParams: Map[String, String],
topics: Map[String, Int],
storageLevel: StorageLevel
): ReceiverInputDStream[(K, V)]
*/
val kafkaParams=Map("group.id"->"stream-sparking-0",
"zookeeper.connect"->"linux-hadoop01.ibeifeng.com:2181/kafka",
"auto.offset.reset"->"smallest"
)
val topics=Map("beifeng"->1)
val dStream=KafkaUtils.createStream[String,String,StringDecoder,StringDecoder](
ssc, //给定sparkStreaming的上下文
kafkaParams, //kafka的参数信息,通过kafka HightLevelComsumerApi连接
topics, //给定读取对应的topic的名称以及读取数据的线程数量
StorageLevel.MEMORY_AND_DISK_2 //数据接收器接收到kafka的数据后的保存级别
).map(_._2) val resultWordcount=dStream
.filter(line=>line.nonEmpty)
.flatMap(line=>line.split(" ").map((_,1)))
.reduceByKey(_+_)
resultWordcount.foreachRDD(rdd=>{
rdd.foreachPartition(iter=>iter.foreach(println))
}) //启动
ssc.start()
//等到
ssc.awaitTermination()
}
}
3.效果
在kafka producer输入内容,将会在控制台上进行展示
三:多Receiver
1.说明
当当个reveiver接收的数据被限制的时候,可以使用多个receiver
2.程序
package com.stream.it import kafka.serializer.StringDecoder
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext} object MulReceiverKafkaWordcount {
def main(args: Array[String]): Unit = {
val conf=new SparkConf()
.setAppName("spark-streaming-wordcount2")
.setMaster("local[*]")
val sc=SparkContext.getOrCreate(conf)
val ssc=new StreamingContext(sc,Seconds(15)) /*
def createStream[K: ClassTag, V: ClassTag, U <: Decoder[_]: ClassTag, T <: Decoder[_]: ClassTag](
ssc: StreamingContext,
kafkaParams: Map[String, String],
topics: Map[String, Int],
storageLevel: StorageLevel
): ReceiverInputDStream[(K, V)]
*/
val kafkaParams=Map("group.id"->"stream-sparking-0",
"zookeeper.connect"->"linux-hadoop01.ibeifeng.com:2181/kafka",
"auto.offset.reset"->"smallest"
)
val topics=Map("beifeng"->4)
val dStream1=KafkaUtils.createStream[String,String,StringDecoder,StringDecoder](
ssc, //给定sparkStreaming的上下文
kafkaParams, //kafka的参数信息,通过kafka HightLevelComsumerApi连接
topics, //给定读取对应的topic的名称以及读取数据的线程数量
StorageLevel.MEMORY_AND_DISK_2 //数据接收器接收到kafka的数据后的保存级别
).map(_._2) val dStream2=KafkaUtils.createStream[String,String,StringDecoder,StringDecoder](
ssc, //给定sparkStreaming的上下文
kafkaParams, //kafka的参数信息,通过kafka HightLevelComsumerApi连接
topics, //给定读取对应的topic的名称以及读取数据的线程数量
StorageLevel.MEMORY_AND_DISK_2 //数据接收器接收到kafka的数据后的保存级别
).map(_._2) //合并dstream
val dStream=dStream1.union(dStream2) val resultWordcount=dStream
.filter(line=>line.nonEmpty)
.flatMap(line=>line.split(" ").map((_,1)))
.reduceByKey(_+_)
resultWordcount.foreachRDD(rdd=>{
rdd.foreachPartition(iter=>iter.foreach(println))
}) //启动
ssc.start()
//等到
ssc.awaitTermination()
}
}
3.效果
一条数据是一个event
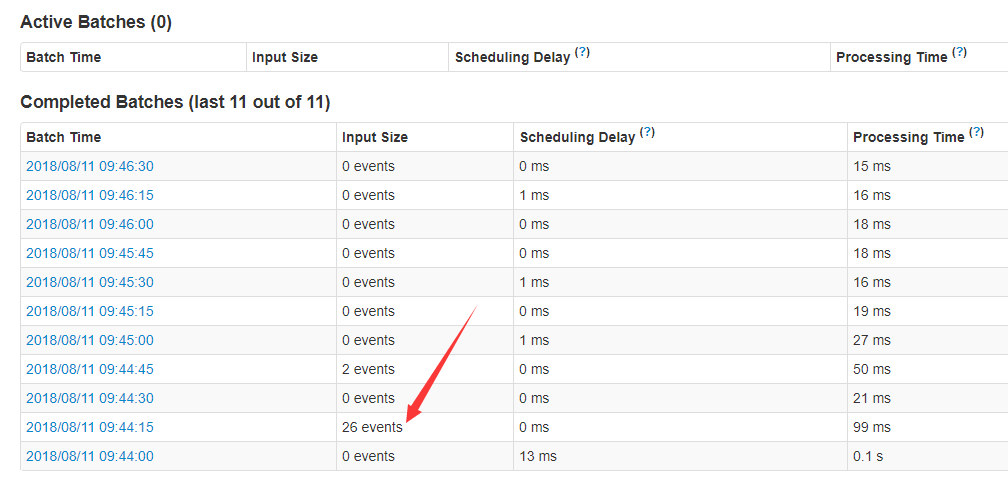
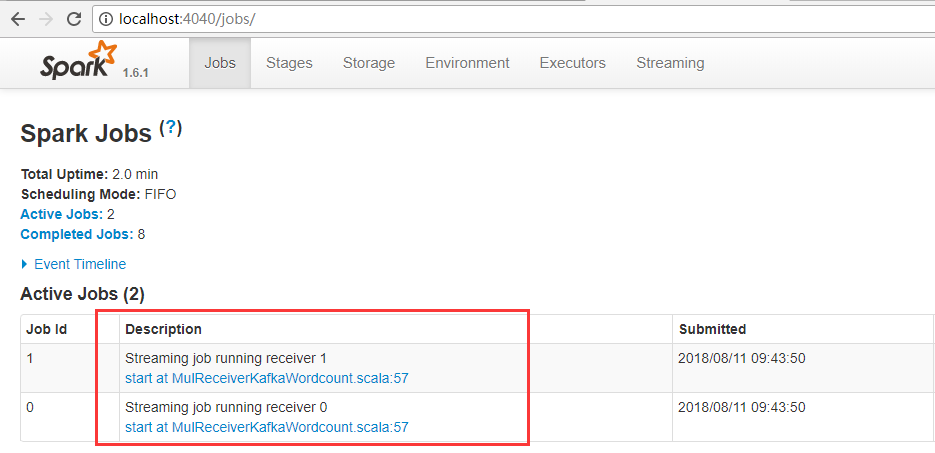
这里有两个receiver。
四:Direct
1.说明
直接读取,不存在receiver
不足,kafkaParams指定连接kafka的参数,内部使用的是kafka的SimpleConsumerAPI,所以,offset只能从头或者从尾开始读取,不能设置。
topics:topic的名称
2.程序
package com.stream.it import kafka.serializer.StringDecoder
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext} object DirectKafkaWordcount {
def main(args: Array[String]): Unit = {
val conf=new SparkConf()
.setAppName("spark-streaming-wordcount")
.setMaster("local[*]")
val sc=SparkContext.getOrCreate(conf)
val ssc=new StreamingContext(sc,Seconds(15)) val kafkaParams=Map(
"metadata.broker.list"->"linux-hadoop01.ibeifeng.com:9092,linux-hadoop01.ibeifeng.com:9093,linux-hadoop01.ibeifeng.com:9094",
"auto.offset.reset"->"smallest"
)
val topics=Set("beifeng")
val dStream=KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](
ssc,
kafkaParams,
topics).map(_._2) val resultWordcount=dStream
.filter(line=>line.nonEmpty)
.flatMap(line=>line.split(" ").map((_,1)))
.reduceByKey(_+_)
resultWordcount.foreachRDD(rdd=>{
rdd.foreachPartition(iter=>iter.foreach(println))
}) //启动
ssc.start()
//等到
ssc.awaitTermination()
}
}
3.效果
没有receiver。
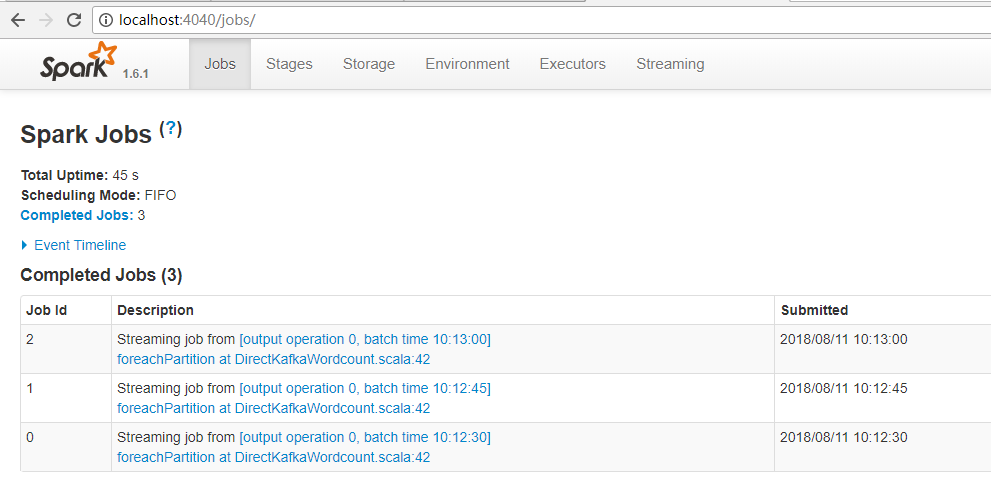
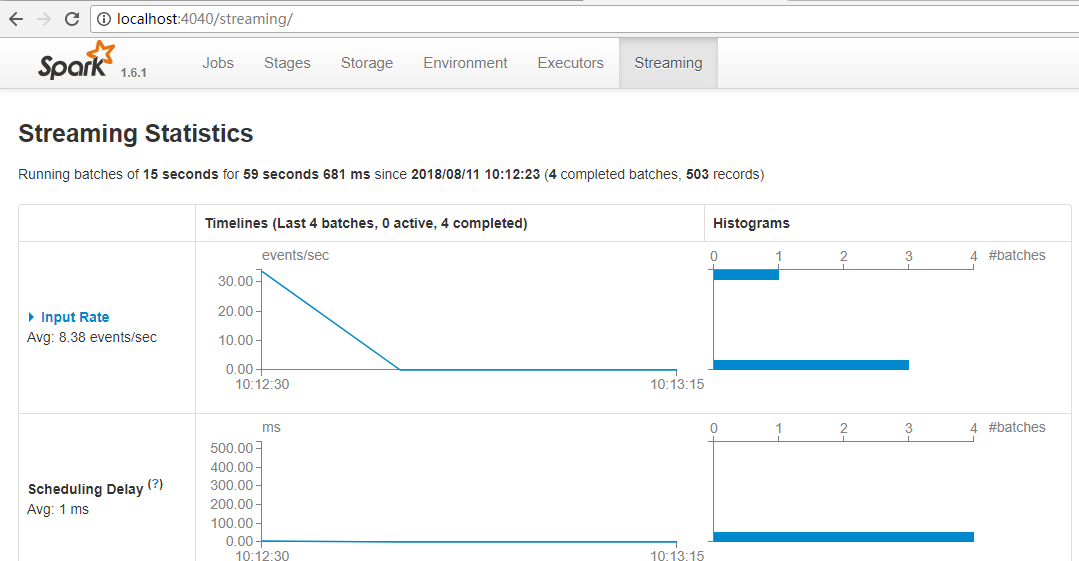
五:Direct实现是累加器管理offset偏移量
1.程序
kafkaParams 中只有这个参数下才能生效。
数据先进行保存或者打印,然后更新accumulable中的offset,然后下一批的dstream进行更新offset。
累加器需要在外面进行定义。
package com.stream.it import scala.collection.mutable
import kafka.common.TopicAndPartition
import kafka.message.MessageAndMetadata
import kafka.serializer.StringDecoder
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{Accumulable, AccumulableParam, SparkConf, SparkContext} object AccumubaleKafkaWordcount {
def main(args: Array[String]): Unit = {
val conf=new SparkConf()
.setAppName("spark-streaming-wordcount")
.setMaster("local[*]")
val sc=SparkContext.getOrCreate(conf)
val ssc=new StreamingContext(sc,Seconds(15))
val accumu = DroppedAccumulable.getInstance(sc) val kafkaParams = Map(
"metadata.broker.list" -> "linux-hadoop01.ibeifeng.com:9092,linux-hadoop01.ibeifeng.com:9093,linux-hadoop01.ibeifeng.com:9094,linux-hadoop01.ibeifeng.com:9095"
) // TODO: 从某一个存储offset的地方读取offset偏移量数据, redis\hbase\其他地方.....
val fromOffsets = Map(
TopicAndPartition("beifeng", 0) -> -1L, // 如果这里给定的偏移量是异常的,会直接从kafka中读取偏移量数据(largest)
TopicAndPartition("beifeng", 1) -> 0L,
TopicAndPartition("beifeng", 2) -> 0L,
TopicAndPartition("beifeng", 3) -> 0L
) val dstream = KafkaUtils.createDirectStream[String, String, kafka.serializer.StringDecoder, kafka.serializer.StringDecoder, String](
ssc, // 上下文
kafkaParams, // kafka连接
fromOffsets,
(message: MessageAndMetadata[String, String]) => {
// 这一块在Executor上被执行
// 更新偏移量offset
val topic = message.topic
val paritionID = message.partition
val offset = message.offset
accumu += (topic, paritionID) -> offset
// 返回value的数据
message.message()
}
) val resultWordCount = dstream
.filter(line => line.nonEmpty)
.flatMap(line => line.split(" ").map((_, 1)))
.reduceByKey(_ + _) resultWordCount.foreachRDD(rdd => {
// 在driver上执行
try {
rdd.foreachPartition(iter => {
// 代码在executor上执行
// TODO: 这里进行具体的数据保存操作
iter.foreach(println)
}) // TODO: 在这里更新offset, 将数据写入到redis\hbase\其他地方.....
accumu.value.foreach(println)
} catch {
case e: Exception => // nothings
}
}) //启动
ssc.start()
//等到
ssc.awaitTermination()
}
}
object DroppedAccumulable {
private var instance: Accumulable[mutable.Map[(String, Int), Long], ((String, Int), Long)] = null def getInstance(sc: SparkContext): Accumulable[mutable.Map[(String, Int), Long], ((String, Int), Long)] = {
if (instance == null) {
synchronized {
if (instance == null) instance = sc.accumulable(mutable.Map[(String, Int), Long]())(param = new AccumulableParam[mutable.Map[(String, Int), Long], ((String, Int), Long)]() {
/**
* 将t添加到r中
*
* @param r
* @param t
* @return
*/
override def addAccumulator(r: mutable.Map[(String, Int), Long], t: ((String, Int), Long)): mutable.Map[(String, Int), Long] = {
val oldOffset = r.getOrElse(t._1, t._2)
if (t._2 >= oldOffset) r += t
else r
} override def addInPlace(r1: mutable.Map[(String, Int), Long], r2: mutable.Map[(String, Int), Long]): mutable.Map[(String, Int), Long] = {
r2.foldLeft(r1)((r, t) => {
val oldOffset = r.getOrElse(t._1, t._2)
if (t._2 >= oldOffset) r += t
else r
})
} override def zero(initialValue: mutable.Map[(String, Int), Long]): mutable.Map[(String, Int), Long] = mutable.Map.empty[(String, Int), Long]
})
}
} // 返回结果
instance
}
}
2.效果
可以将以前的信息打出来。

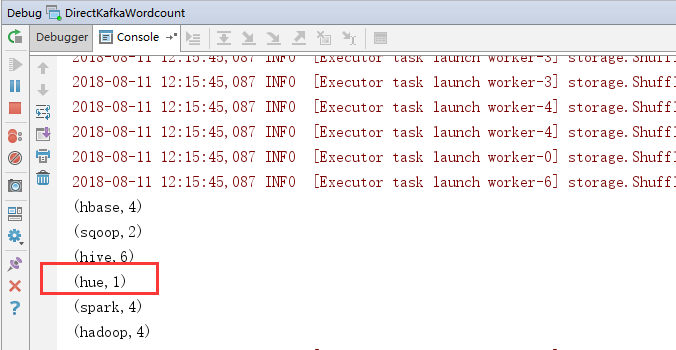
最新文章
- java与c#的反射性能比较
- hdfs创建级联文件夹
- 关于eclipse android 在manifest改app应用包名注意事项
- web 网站安全证书已过期或不可信 是否继续浏览
- 获取aplicationContext对象,从而获取任何注入的对象
- Activity 模版样式简介
- 工程中.pch文件的作用 及使用方法
- linux命令:rsync, 同步文件和文件夹的命令
- HUST 1351 Group
- LauncherModel.Callbacks接口
- css之幽灵空白节点
- confluence 5.8.6升级到5.10.1
- Android RxJava
- Ajax的实现及使用-原生对象
- 抓取awr、语句级awr、ashrpt
- [POJ 3984] 迷宫问题(BFS最短路径的记录和打印问题)
- 4.4基于switch语句的译码器
- Win-Lin双系统重装Windows找回Linux启动
- 【codevs1690】开关灯 (线段树 区间修改+区间求和 (标记))
- Lucene整理--索引的建立