Hadoop集群搭建-05安装配置YARN
2024-10-17 00:17:43
先保证集群5台虚拟机,
| nn1 | nn2 | s1 | s2 | s3 | |
|---|---|---|---|---|---|
| hadoop | 是 | 是 | 是 | 是 | 是 |
| zookeeper | 是 | 是 | 是 | ||
| namenode | 是 | 是 | |||
| jouralnode | 是 | 是 | |||
| datanode | 是 | 是 | 是 |
1.然后启动yarn在nn1机器上:
[hadoop@nn1 hadoop]$ start-yarn.sh
然后查看各节点信息
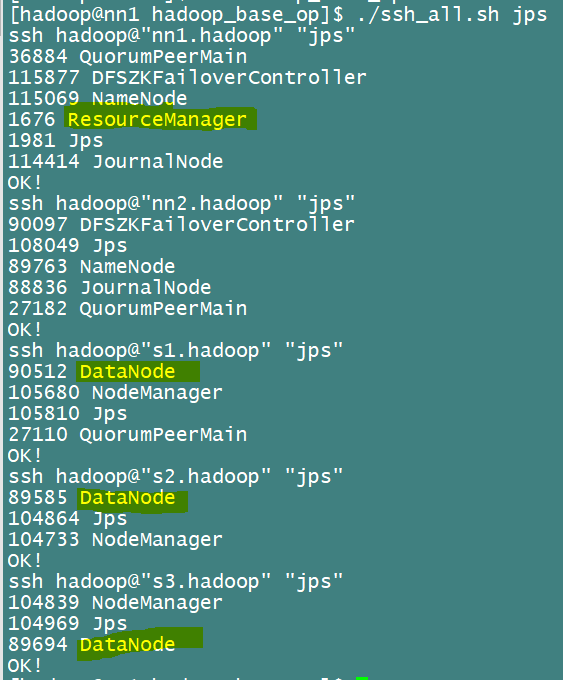
2.配置yarn的HA高可用
高可用就是好几台机器,一台突然挂掉了,其他机器就补上去,刚刚只启动了nn1作为yarn服务器,只有一台,所以这里要在nn2也开一台,来做简单的高可用
###############在nn2控制台操作####################
[hadoop@nn2 ~]$ yarn-daemon.sh start resourcemanager
如图查看jps
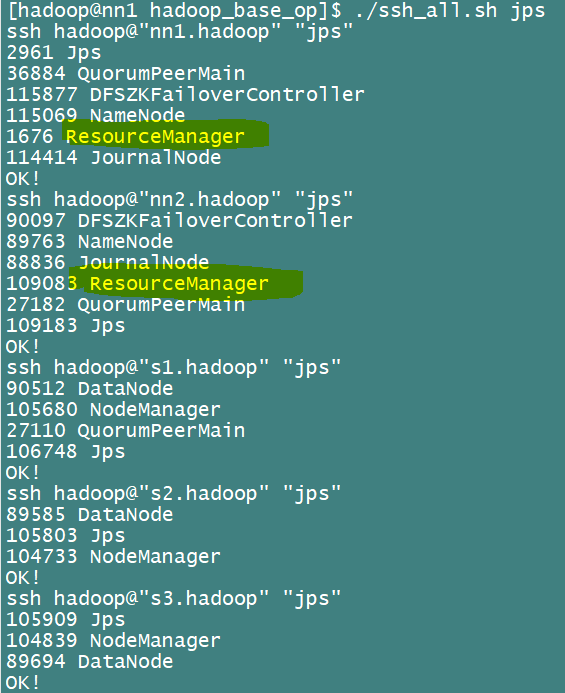
这里相比第一张图,在nn2多了一个resourceManager
##########查看状态############
[hadoop@nn1 hadoop_base_op]$ yarn rmadmin -getServiceState rm1
active
[hadoop@nn1 hadoop_base_op]$ yarn rmadmin -getServiceState rm2
standby
打开网页查看http://192.168.10.6:8088/cluster
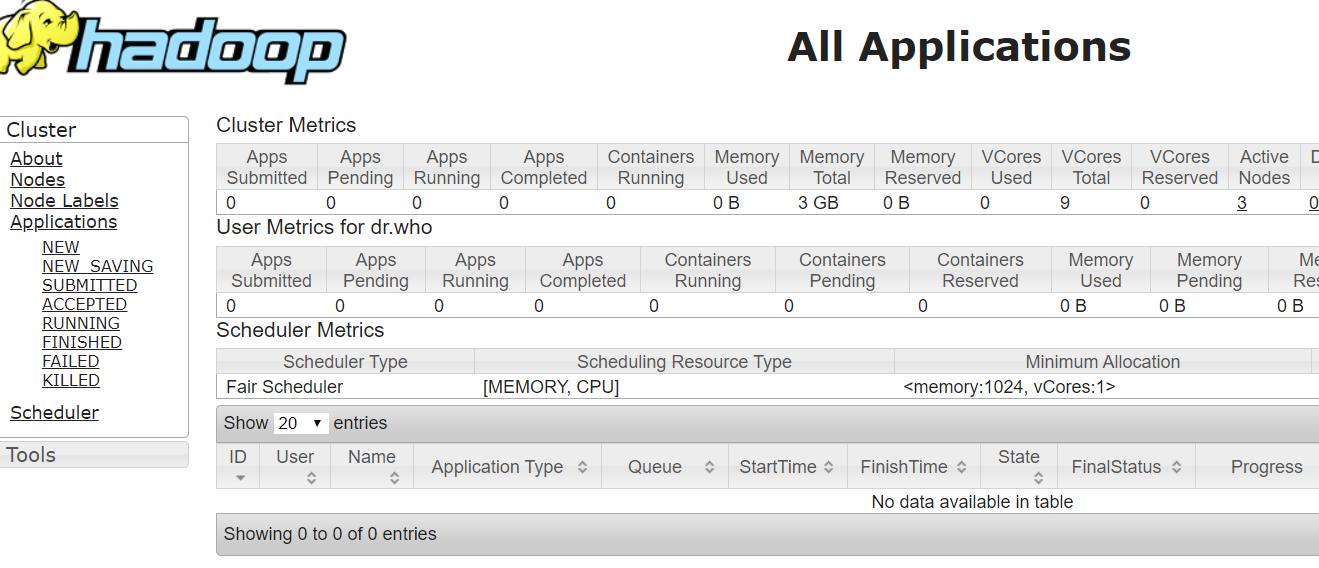
出现hadoop页面就是成功了,这时候因为nn1是active状态,所以你输入http://192.168.10.7:8088/cluster的话,或自动跳转到active机器,也就是自动跳转到nn1的ip上。
启动成功
来,跑个任务试试
用这个集群进行简单的wordcount任务
创建两个文件
vim abc1
aa bbb abc
aa aa
aa bb
aa cc aa
vim abc2
张三 张 三
张
三 张
把这两个文件上传到hadoop的hdfs上
[hadoop@nn1 ~]$ hadoop fs -mkdir -p /user/hadoop/abc/input
[hadoop@nn1 ~]$ hadoop fs -put ./abc* /user/hadoop/abc/input
查看网页端:
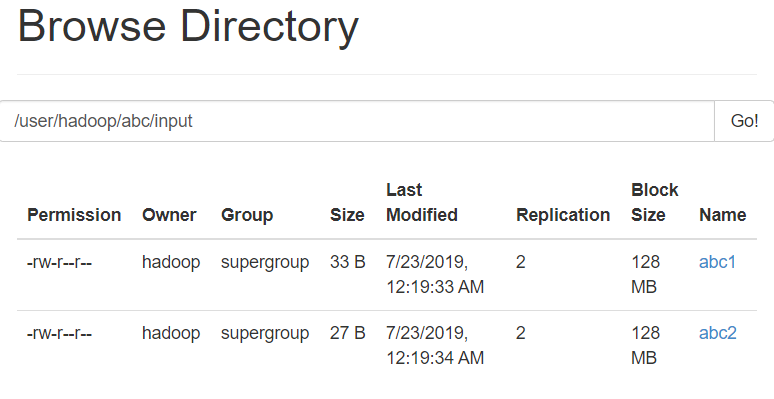
扔到MR里执行下
[hadoop@nn1 ~]$ hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /user/hadoop/abc/input /user/hadoop/abc/output

查看网页端的状态展示:
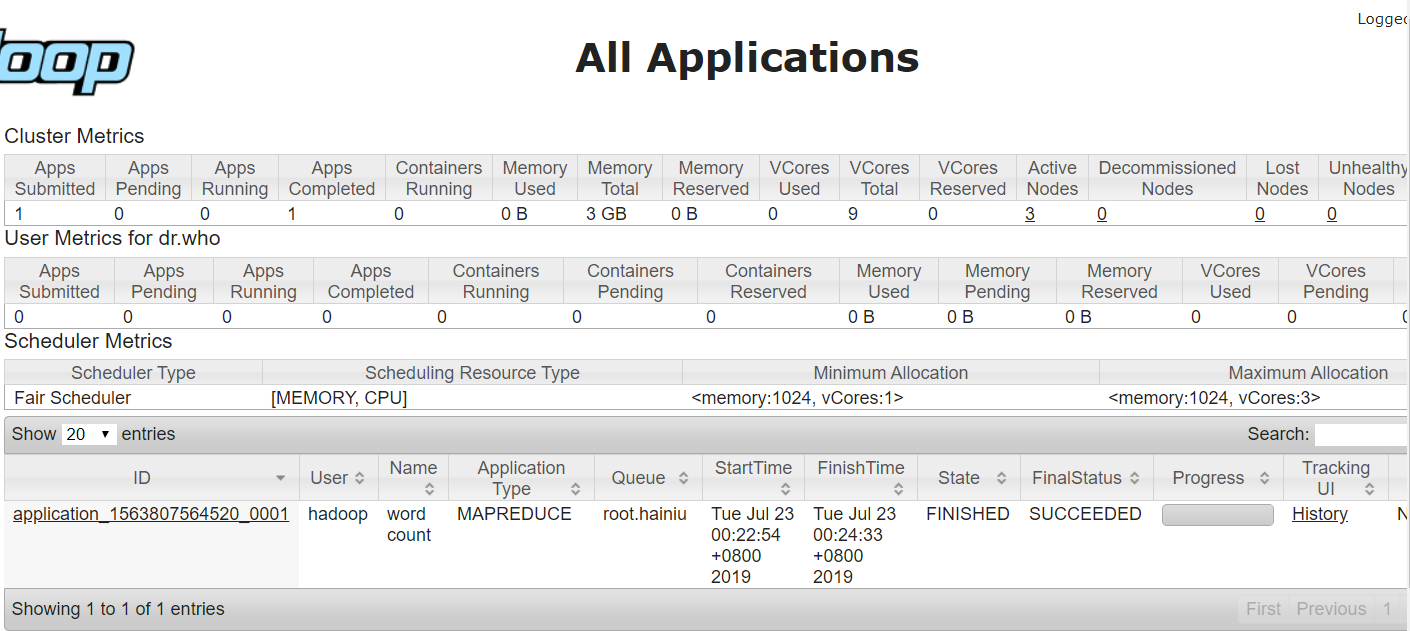
然后我们去hadoop那里查看结果文件
[hadoop@nn1 ~]$ hadoop fs -cat /user/hadoop/abc/output/part-r-00000
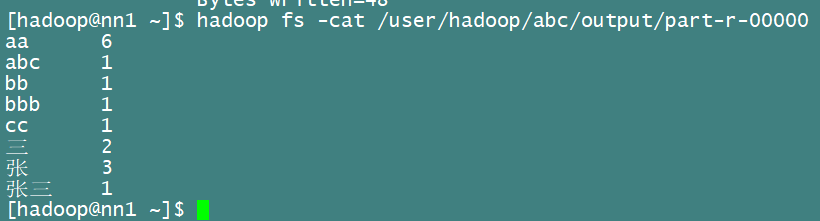
大功告成!!!
最新文章
- 似懂非懂的localStorage和sessionStorage
- golang DynamoDB sdk AccessDeniedException
- HBase、Redis、MongoDB、Couchbase、LevelDB主流 NoSQL 数据库的对比
- 更改printk打印级别
- require 和 file_get_contents
- Python print语句
- C#学习笔记8:HTML和CSS基础学习笔记
- python自动开发之第十八天
- android软键盘的管理和属性的设置
- Android锁定屏幕或关闭状态-screen,高速按两次音量向下键来实现拍摄功能(1.1Framework在实现的形式层广播)
- LINUX 笔记-DU 和 DF
- C++对象模型的那些事儿之一:对象模型(上)
- Ueditor1.3.6 setContent的一个bug
- 一个很有趣的示例Spring Boot项目,使用Giraphe CMS和Spring Boot
- 并发之AQS
- css-animate制作列表鼠标移动覆盖透明层
- Docker Swarm 环境搭建
- 自学Linux Shell9.4-基于Red Hat系统工具包存在两种方式之二:源码包
- Xmpp获取离线消息
- c++中double类型控制小数位数