【消息中间件】kafka
一、kafka整体架构
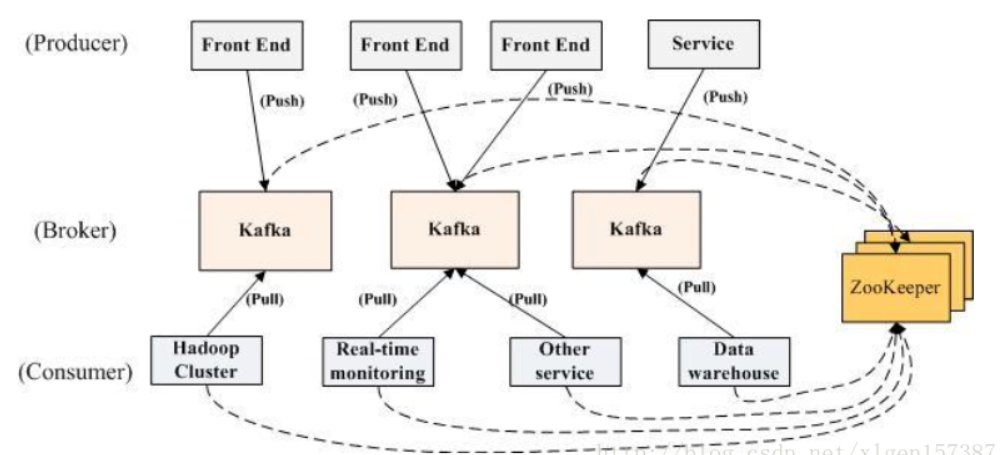
kafka是一个发布订阅模式的消息队列,生产者和消费者是多对多的关系,将发送者与接收者真正解耦;
生产者将消息发送到broker;
消费者采用拉(pull)模式订阅并消费消息;
二、生产者介绍
分区器:制定partition,按照msg key进行分区,保证同样key的消息投递到同一个partiton。例如,按照uid最后两位作为key,可以有100partiron,来保证相同uid的时间在一个partition中。
kafka发送消息是 批量发送+异步的方式来发送,性能提升,消息有序性无法保证;
三、消费者介绍
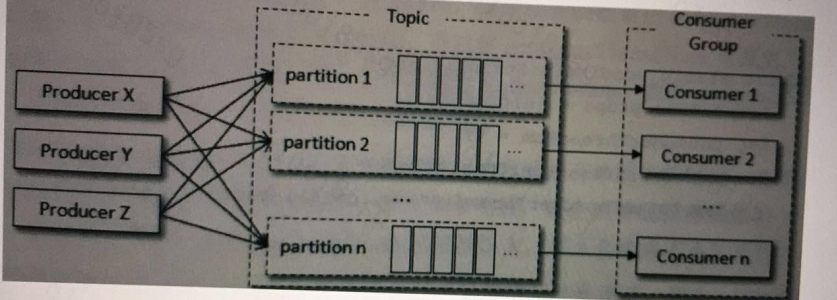
消费者是指调用poll方法的实体,可以是一个线程,也可以是一个服务;
为了避免消费者的浪费,消费者数量要小于partition数量;
3、拉取、处理消息模型
(1)同步消息处理:一个线程对应一个partiton,能够保证partiton内消息有序,消费性能受限于处理消息的速度。
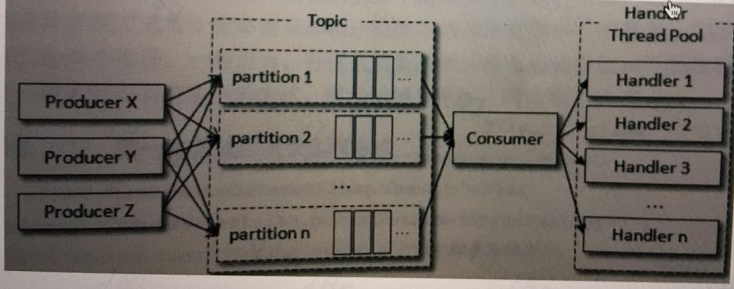
(2)异步处理消息:一个线程负责拉取消息,线程池负责处理消息的模式,不能保证partition内消息有序,消息消费速度快,节省tcp连接开销。
四、消息有序性及重复性
1、消息乱序产生原因:
(1)发送者:异步发送 + 发送失败重试导致的消息乱序
(2)接收者:单个拉消息的线程,多线程同时处理消息的先后顺序不同,导致消息被处理的时间乱序;
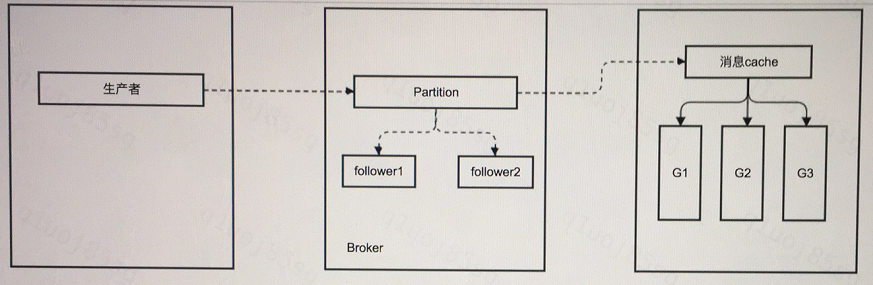
多个拉消息的线程,由于gc导致的消息被处理的乱序;
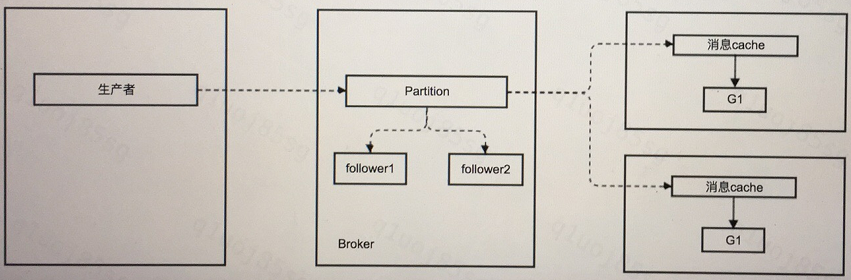
(3)broker:单partition内消息有序,多个partition之间消息无序;
2、消息重复产生原因
消费者提交消息offset与真正处理消息的时差导致的消息重复消费;
增加消费者引起的partiton与消费者之间的“再均衡”导致的消息重复消费;
结论,在保证性能的前提下,消息中间件不可能保证消息不重复投递,除非牺牲性能和高可用,需要下游做幂等。
3、从业务角度看到消息有序
要保证消息的严格有序,需要生产者、消费者、broker之间严密的配合并且牺牲掉系统的并发性,例如将topic的partiton设置为1个。而对于99%的业务需求来说,并不需要100%的按照时间戳的全局严格有序。
可以将全局消息拆成按照业务类型分区的有序,例如订单A的发单、完单、支付与订单B的发单、完单、支付之间并不需要严格有序,但是订单内各种事件的消息顺序却很重要,一个业务需要首先发单事件,并且在随后的支付事件时依赖于前面那个发单事件的一些属性。
所以我们可以将全局的消息按照业务属性拆成局部有序。
从上面的分析看,要保证消息有序性就要降低系统并行度,系统整体吞吐量下降。
严格的按照消息生产的时间戳有序是几乎不可能实现的,所以一个可用的系统是在正常情况下保证消息有序,在几种异常情况下允许乱序,并且对这几种异常情况导致的乱序做好监控和补救措施。
对于消息重复的情况,应该要求下游做好幂等,不能完全依赖于mq,因为mq在保证高可用和高吞吐凉的前提下是不可能做到消息不重复的。
最新文章
- [转]save all TWebbrowser Frame Sources?
- vs2015密钥 企业版 专业版 (vs.net)
- [C++][重载]
- iText导出pdf、word、图片
- Python概述_软件安装_常见问题
- PowerDesigner 面向对象模型(OOM)
- Ubuntu下Geary安装
- HDU 1286 找新朋友
- linux netstat 命令详解
- 在GNU/Linux下将CD音乐转为mp3
- 使用JQuery结合HIghcharts实现从后台获取JSON实时刷新图表
- NSDate详解及获取当前时间等常用操作
- RLP
- 通过traceroute追踪并打印成图片
- ucos-ii的任务调度机制
- 微信商户/H5支付申请 被拒原因:网站存在不实内容或不安全信息
- cocoa-charts 导入其依赖库TABlib 报UIKit Foundation找不到的问题
- oracle instantclient_11_2 配置文件tnsnames.ora
- 关于java项目中的XML文件
- 第一天:html+JavaScript函数