PHP 之Mysql优化
一、建立索引
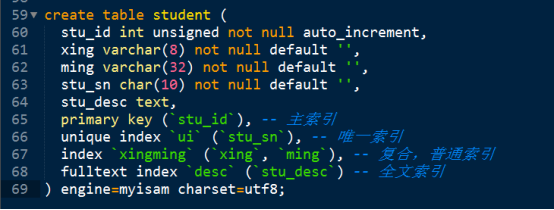
普通索引 index: 对关键字没有要求。
唯一索引 unique index: 要求关键字不能重复。同时增加唯一约束。
主键索引 primary key: 要求关键字不能重复,也不能为NULL。同时增加主键约束。
全文索引 fulltext key: 关键字的来源不是所有字段的数据,而是从字段中提取的特别关键词。
索引的管理:
- 建表时
- 更新表结构

1、前缀索引
建立前缀索引的语法:
alter table test add KEY (name(5));
name一定是字符类型(索引字段),5为长度
那好,如何确定取前面几个字符呢?显然,这个场景是一个观察的结果,也就是说,必须要有一定量的实际数据,我们才能分析出其规律,也就是说这个索引是在后期优化得来的,前期没必要建立。
- 计算不重复的概率:
select COUNT(DISTINCT name) / COUNT(*) as rate from test;
- 找出接近rate的一个n(试出最合理的n)
select COUNT(DISTINCT LEFT(name, 3)) / COUNT() as rate3 from test;
select COUNT(DISTINCT LEFT(name, 5)) / COUNT() as rate5 from test;
select COUNT(DISTINCT LEFT(name, 7)) / COUNT() as rate7 from test;
select COUNT(DISTINCT LEFT(name, 9)) / COUNT() as rate9 from test;
select COUNT(DISTINCT LEFT(name, 11)) / COUNT() as rate11 from test;
select COUNT(DISTINCT LEFT(name, 15)) / COUNT() as rate15 from test;
select COUNT(DISTINCT LEFT(name, 20)) / COUNT(*) as rate20 from test;
…
2、全文索引
该类型的索引特殊在:关键字的创建上。为了解决 like ‘%keyword%’这类查询的匹配问题。
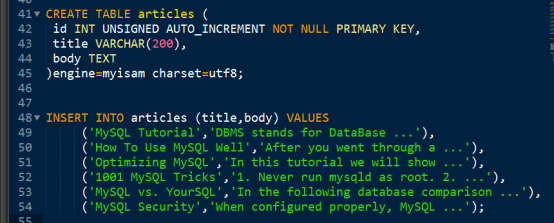
查询 标题或者内容包含 database 关键字的记录。
形成的SQL如下:
Select * from articles where title like ‘%database%’ or body like ‘%database%’;
此时需要建立全文索引

直接使用上面的SQL:
需要使用特殊的全文索引匹配语法才可以生效:
Match() against();

注意:mysql提供的全文索引不能对中文起作用,可以采用Sphinx索引引擎。
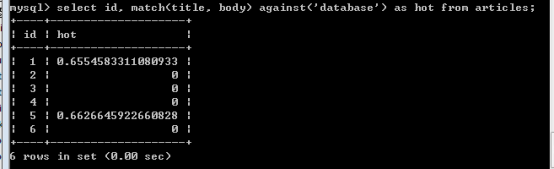
Match() against() ,返回的关键字的匹配度(关键字与记录的关联程度)。
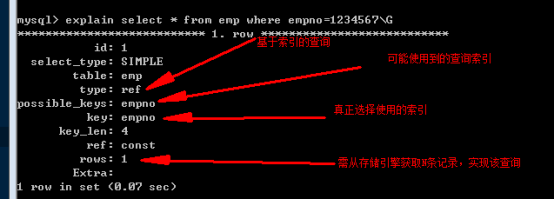
3、Explain 执行计划
可以通过在select语句前使用 explain,来获取该查询语句的执行计划,而不是真正执行该语句。
二、查询缓存(query_cache)
查看缓存配置:
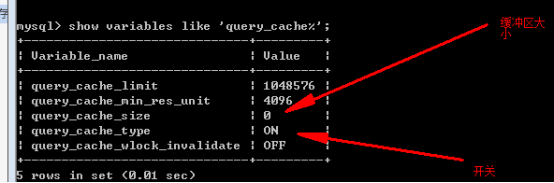
开启并设置大小:
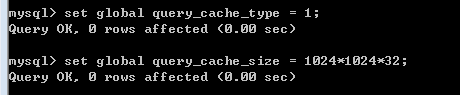
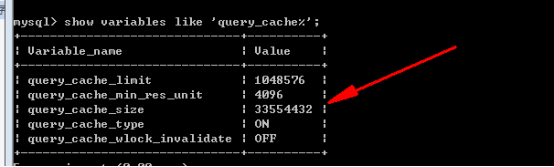
注意事项:
1、严格保证SQL一致,区分大小写等。
2、 如果查询时包含动态数据,则不能被缓存。
3、一旦开启查询缓存,MySQL会将所有可以被缓存的select语句都缓存。如果存在不想使用缓存的SQL执行,则可以使用 SQL_NO_CACHE语法提示达到目的。
三、分区
1、分区语法
Create table table_name (
定义
)
Partition by 分区算法 (参数) 分区选项。
注意:分区与存储引擎无关,是MySQL逻辑层完成的。
通过变量查看当前mysql是否支持分区:

分区算法:
MySQL提供4种
取余:Key,hash
条件:List,range
提示,参与分区的参数字段需要为主键的一部分。
- key - 按照某个字段进行取余
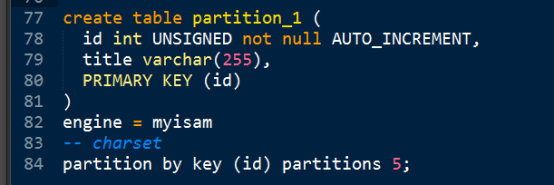
Hash - 按照某个表达式的值进行取余
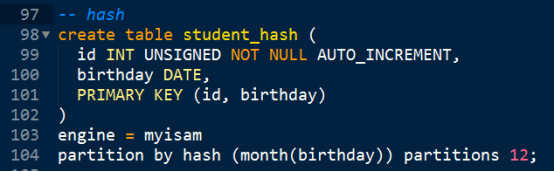
注意:Key,hash都是取余算法,要求分区参数,返回的数据必须为整数。
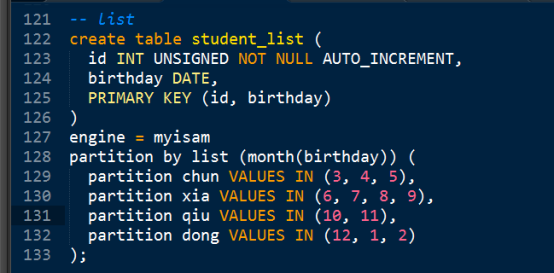
List - 需要指定的每个分区数据的存储条件
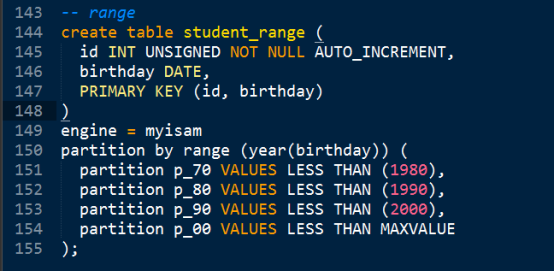
- Range - 条件依赖的数据是一个条件表达式
2、管理分区语法
- 取余:key和hash
增加分区数量:

减少分区数量:

采用取余算法的分区数量的修改,不会导致已有分区数据的丢失,需要重新分配数据到新大地分区。
- 条件:List和Range
添加分区:

删除分区:

注意:删除条件算法的分区,导致分区数据丢失。
四、分表
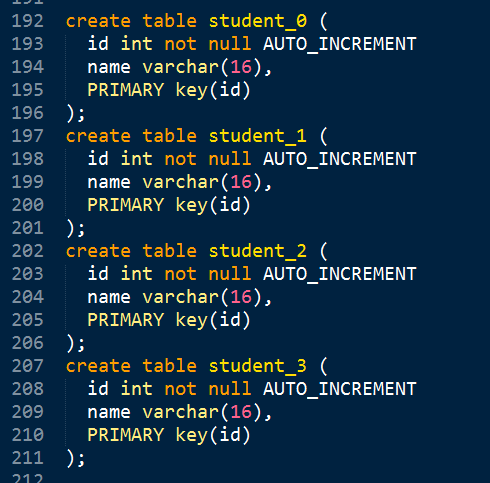
1、水平分表案例
创建结构相同的N个表:
再创建用于管理学生ID的表:
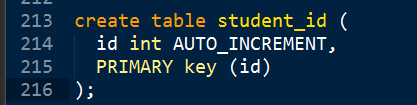
PHP客户端逻辑:
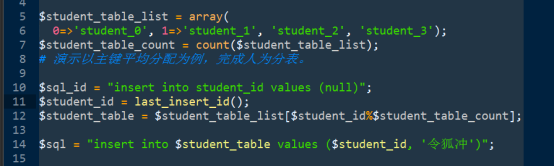
2、垂直分表
表中存在多个字段。
常用字段 - 非常有字段
主要目的,减少每条记录的长度。
例如学生表可以分成:
基础表和额外表,两张表中记录为1:1的关系。
案例:
基础信息表
Student_base
Id name age
额外信息表
Student_extra
Id 籍贯 政治面貌
五、架构层面

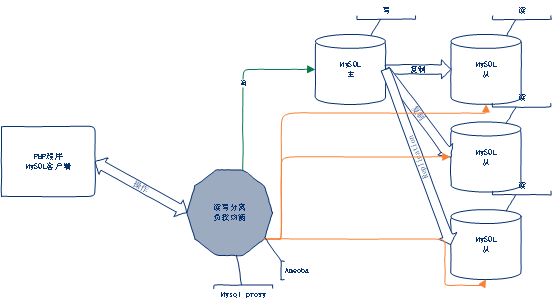
六、SQL语句
将复杂的SQL拆分多次执行。
案例:
商品,分类:
Select * from category;分类列表
Select cat_id, count(*) from goods group by goods;分类对应的商品数量。
分页
Limit offset, size;
Size = 10;
|
Page |
offset |
|
5 |
40, 10 |
|
50 |
490, 10 |
|
5000 |
4990, 10 |
|
500000 |
499990, 10 |
Limit 的使用,会大大提升无效数据的检索(被跳过)。
应该使用条件等过滤方式,将检索到的数据尽可能精确定位到需要的数据上。
例如分页:
Limit size;
七、慢查询日志
查看慢查询日志:
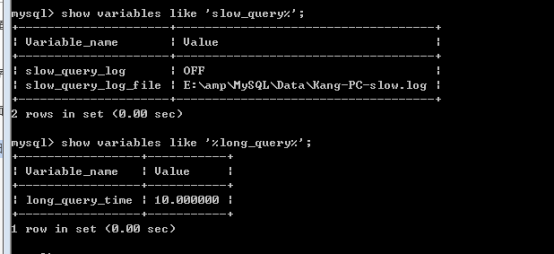
开启日志:
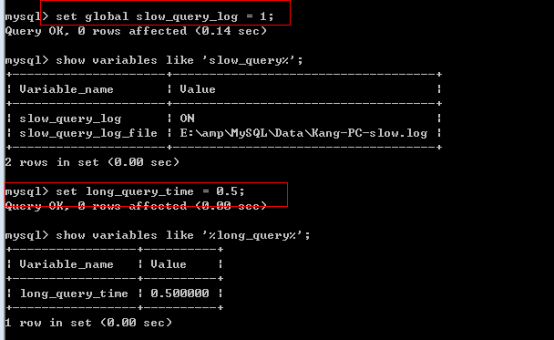
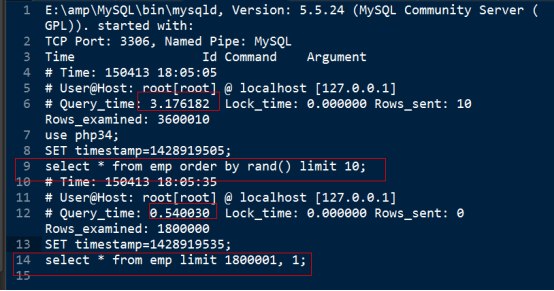
日志信息如下:
最新文章
- JSON数据和对象
- 全透明Activity
- JSON的parse()和stringfy()方法
- Loadrunner之API测试
- Android 内存泄漏总结
- PHP学习笔记:keditor的使用
- SQL Server之存储过程基础知识
- knockoutjs + easyui.treegrid 可编辑的自定义绑定插件
- java web -部署在linux
- 了解SOA是什么!
- Mysql 语句汇总(性能篇)
- ASP.NET——两个下拉框来实现动态联动
- Android可以拖动位置的ListVeiw
- 语音识别(LSTM+CTC)
- vscode打开django项目pylint提示has not "object" member
- loglog 函数的使用
- jquery发起get/post请求_或_获取html页面数据
- SpringBoot拦截器中无法注入bean的解决方法
- bzoj千题计划197:bzoj4247: 挂饰
- MySQL binlog导入失败