Spark之开窗函数
2024-08-31 08:56:18
一.简介
开窗函数row_number()是按照某个字段分组,然后取另外一个字段排序的前几个值的函数,相当于分组topN。如果SQL语句里面使用了开窗函数,那么这个SQL语句必须使用HiveContext执行。
二.代码实践【使用HiveContext】
package big.data.analyse.sparksql
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
/**
* Created by zhen on 2019/7/6.
*/
object RowNumber {
/**
* 设置日志级别
*/
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
/**
* 创建spark入口,支持Hive
*/
val spark = SparkSession.builder().appName("RowNumber")
.master("local[2]").enableHiveSupport().getOrCreate()
/**
* 创建测试数据
*/
val array = Array("1,Hadoop,12","5,Spark,6","3,Solr,15","3,HBase,8","6,Hive,16","6,TensorFlow,26")
val rdd = spark.sparkContext.parallelize(array).map{ row =>
val Array(id, name, age) = row.split(",")
Row(id, name, age.toInt)
}
val structType = new StructType(Array(
StructField("id", StringType, true),
StructField("name", StringType, true),
StructField("age", IntegerType, true)
))
/**
* 转化为df
*/
val df = spark.createDataFrame(rdd, structType)
df.show()
df.createOrReplaceTempView("technology")
/**
* 应用开窗函数row_number
* 注意:开窗函数只能在hiveContext下使用
*/
val result_1 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top <= 1")
result_1.show()
val result_2 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top <= 2")
result_2.show()
val result_3 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top <= 3")
result_3.show()
val result_4 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top > 3")
result_4.show()
}
}
三.结果【使用HiveContext】
1.初始数据
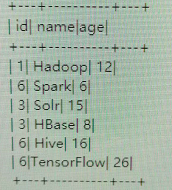
2.top<=1时
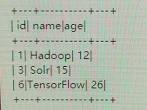
3.top<=2时

4.top<=3时
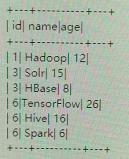
5.top>3时【分组中最大为3】
四.代码实现【不使用HiveContext】
package big.data.analyse.sparksql
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
/**
* Created by zhen on 2019/7/6.
*/
object RowNumber {
/**
* 设置日志级别
*/
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
/**
* 创建spark入口,不支持Hive
*/
val spark = SparkSession.builder().appName("RowNumber")
.master("local[2]").getOrCreate()
/**
* 创建测试数据
*/
val array = Array("1,Hadoop,12","5,Spark,6","3,Solr,15","3,HBase,8","6,Hive,16","6,TensorFlow,26")
val rdd = spark.sparkContext.parallelize(array).map{ row =>
val Array(id, name, age) = row.split(",")
Row(id, name, age.toInt)
}
val structType = new StructType(Array(
StructField("id", StringType, true),
StructField("name", StringType, true),
StructField("age", IntegerType, true)
))
/**
* 转化为df
*/
val df = spark.createDataFrame(rdd, structType)
df.show()
df.createOrReplaceTempView("technology")
/**
* 应用开窗函数row_number
* 注意:开窗函数只能在hiveContext下使用
*/
val result_1 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top <= 1")
result_1.show()
val result_2 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top <= 2")
result_2.show()
val result_3 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top <= 3")
result_3.show()
val result_4 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top > 3")
result_4.show()
}
}
五.结果【不使用HiveContext】
最新文章
- 【转】Linux常用命令大全
- Repeater 获取数据值
- [转]处理程序“PageHandlerFactory-Integrated”在其模块列表中有一个错误模块“ManagedPipelineHandler”
- AppCache 离线存储 应用程序缓存 API 及注意事项
- java基础笔记
- hbase-site.xml 参数设置
- poj 2888 Magic Bracelet
- 史上最简单的带流控功能的http server
- vue指令v-else-if示例解析
- 转:python request属性及方法说明
- 非关心数据库无法进行连表查询 所以我们需要在进行一对多查询时候 无法满足 因此需要在"1"的一方添加"多"的一方的的id 以便用于进行连表查询 ; 核心思想通过id进行维护与建文件
- 《剑指offer》-找到字符串中第一个只出现一个的字符
- /usr/bin/ld: cannot find -lncurses是咋回事?
- python基础-abstractmethod、__属性、property、setter、deleter、classmethod、staticmethod
- 主成分分析(PCA)原理及推导
- 关于ArrayList和List的区别
- zabbix搭建并结合mikoomi插件监控hadoop集群
- 170403、java 版cookie操作工具类
- P1272
- 周记【距gdoi:126天】
热门文章
- Spring @RequestMapping 参数说明
- 基于Vue SEO的四种方案
- Html JavaScript网页制作与开发完全学习手册
- php提供一维数组模糊查询
- java.lang.ClassNotFoundException: org.apache.http.impl.client.HttpClientBuilder
- Centos7快速安装Rancher
- Difference between LinkedList vs ArrayList in Java
- 【miscellaneous】编码格式简介(ANSI、GBK、GB2312、UTF-8、GB18030和 UNICODE)
- 研发的困境----DEVOPS
- 前端与算法 leetcode 27.移除元素