强化学习之QLearning
注:以下第一段代码是 文章 提供的代码,但是简书的代码粘贴下来不换行,所以我在这里贴了一遍。其原理在原文中也说得很明白了。
算个旅行商问题
基本介绍
戳 代码解释与来源
代码整个计算过程使用的以下公式-QLearning
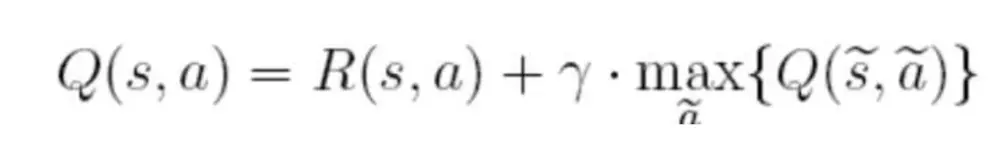
在上面的公式中,S表示当前的状态,a表示当前的动作,s表示下一个状态,a表示下一个动作,γ为贪婪因子,0<γ<1,一般设置为0.8。Q表示的是,在状态s下采取动作a能够获得的期望最大收益,R是立即获得的收益,而未来一期的收益则取决于下一阶段的动作
算法过程

面对问题
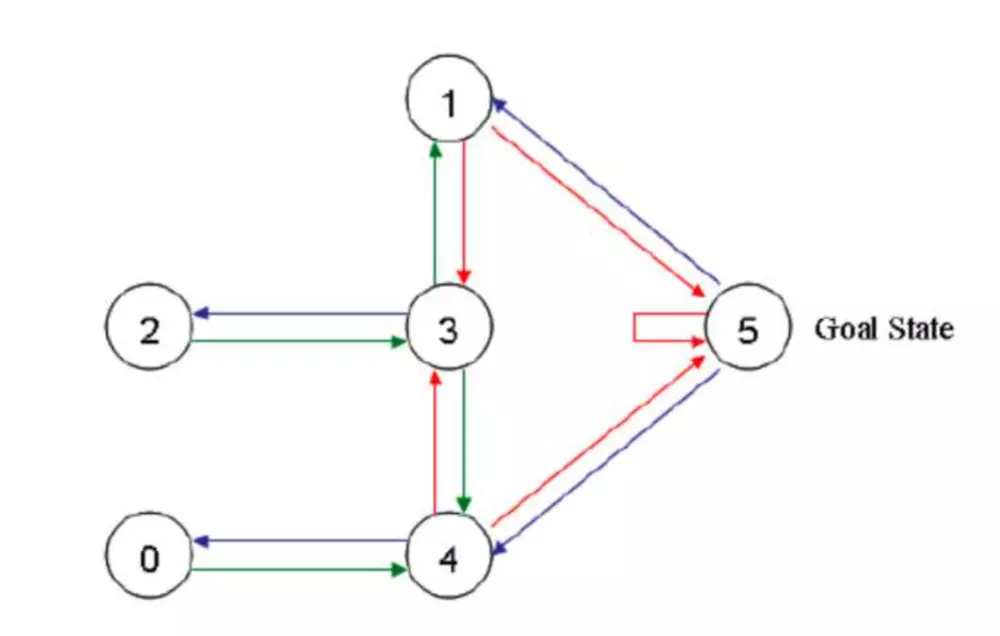
这是一个把一个代理(玩家)随机丢入一个房间,代理如何能最快速到达指定房间(在这里是5号房间) 的问题。
代码全文
import numpy as np
import random
r = np.array([[-1, -1, -1, -1, 0, -1], [-1, -1, -1, 0, -1, 100], [-1, -1, -1, 0, -1, -1], [-1, 0, 0, -1, 0, -1], [0, -1, -1, 0, -1, 100], [-1, 0, -1, -1, 0, 100]])
q = np.zeros([6,6],dtype=np.float32)
gamma = 0.8
step = 0
for step in range(100):
print("step:", step)
state = random.randint(0,5)
if state != 5:
next_state_list=[]
for i in range(6):
if r[state,i] != -1:
next_state_list.append(i)
next_state = next_state_list[random.randint(0,len(next_state_list)-1)]
qval = r[state,next_state] + gamma * max(q[next_state])
q[state,next_state] = qval
print(q)
for i in range(10):
print("第{}次验证".format(i + 1))
state = random.randint(0, 5)
print('机器人处于{}'.format(state))
count = 0
while state != 5:
if count > 20:
print('fail')
break
q_max = q[state].max()
q_max_action = []
for action in range(6):
if q[state, action] == q_max:
q_max_action.append(action)
next_state = q_max_action[random.randint(0, len(q_max_action) - 1)]
print("the robot goes to " + str(next_state) + '.')
state = next_state
count += 1
关于视频教程
视频教程中的demo实现没有看懂,然后我就按照上述文章的思路实现了视频中demo的基本功能。还不算完善,完善之后再追加。
简述:视频中demo的功能是实现一个单项运动,从1走到6就算成功。但是机器本身不知道应该按照什么样的方式走,应该加或者减,通过多次强化学习之后,可以通过回报表(Q表)知道自己应该一路加上去,从1加到6.
代码
import numpy as np
import random
r = np.array([[-1, 0, -1, -1, -1, -1], [0, -1, 0, -1, -1, -1], [-1, 0, -1,0, -1, -1], [-1, -1, 0, -1,0, -1], [-1, -1, -1, 0, -1, 100], [-1, -1,-1, -1, 0, 100 ]])
#能走的标记为0,不能走的方向标记为-1,到达终点标记为100
#因为是从1走到6一字排开,所以1能到2,2能到1,1不能到3酱紫
q = np.zeros([6,6],dtype=np.float32)
gamma = 0.8
#贪婪因子
step = 0
for step in range(10):
state = 0
time = 0
while state != 5:
time =time + 1
next_state_list=[]
for i in range(6):
if r[state,i] != -1:
next_state_list.append(i)
next_state = next_state_list[random.randint(0,len(next_state_list)-1)]
qval = r[state,next_state] + gamma * max(q[next_state])
q[state,next_state] = qval
state = next_state
############################我是分割线##########################
print(q)#打印Q表
state = 0
while state != 5:
next_state = q[state].argmax(axis = 0)#取得Q表当前行最大值的索引
print(next_state)
state = next_state
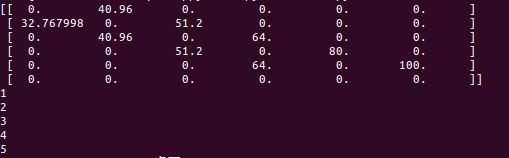
打印结果
解释
分割线之上通过强化学习(QLearning)得到Q表
分割线之下是通过Q表得到路线图(即一路上加)
打印结果表示下一步到哪 。初始在位置0,然后依次顺序打印应该到哪个位置。
总结
神经网络适合拟合、图像视频识别与分类能,强化学习适合做类似于阿尔法狗/走迷宫酱紫的智能活动
参考
文章:
https://www.itcodemonkey.com/article/3646.html
https://www.jianshu.com/p/29db50000e3f?utm_medium=hao.caibaojian.com&utm_source=hao.caibaojian.com
视频:
https://www.bilibili.com/video/av16921335/?p=6 对应代码
最新文章
- 浅谈webWorker
- XidianOJ 1097 焊板子的xry111
- MFC中快速应用OpenCV(转)
- Shortest Word Distance 解答
- Oracle性能优化学习笔记WHERE在连接顺序的条款
- FFMpeg编译之路
- 论文翻译:Neural Networks With Few Multiplications
- 我的 FPGA 学习历程(08)—— 实验:点亮单个数码管
- 基于udp简单聊天的系统
- Vim怎么批量处理文件将tab变为space
- python,小练习(计算两点之间直线长度)
- 图片上传插件:webuploader
- linux怎么不输入路径直接运行程序脚本
- leetcode 121 买卖股票的最佳时机
- Python对象(上)
- 蓝桥杯 ALGO-2:最大最小公倍数
- Mybatis最入门---代码自动生成(generatorConfig.xml配置)
- Minecraft Forge编程入门二 “工艺和食谱”
- mvn deploy
- rem和em的区别