大白话5分钟带你走进人工智能-第30节集成学习之Boosting方式和Adaboost
目录
1、前述:
从本节开始我们讲解集成学习的思想和一个重要的算法Adaboost。
2、Bosting方式介绍:
之前我们介绍了blending的一种方式,uniformly blending,均匀的搅拌,也就是bagging形式,就是把所有g(x)加起来,取个符号,每个g(x)的结果认为是同样重要的,此时每个g(x)的权重就等于1。数学符号表达为:
今天开始我们讲解另一种blending的方式,linearly Blending,就是把结果线性组合一下。线性组合就是一次项前边可以和一个系数相乘,再相加叫做线性组合,线性组合关注的是,它不带平方关系,不带立方关系,只是一次项,我们称这种一次方的相乘相加就叫做线性的。因为它是直的,带平方它就变成曲线了,或者相乘就变成曲线了。假如g1(x)乘以g2(x)虽然没带平方,但它也不是线性的,它们彼此之间相乘了。它们不能相乘,只能有相加的关系,系数可以随便加,我们管这个东西叫做线性的Blending,简称Lineraly Blending 。也就是Boosting 方式,此时它们的权重是unequal,不相等的。数学符号表达为:
Boosting方式代表有Adaboost和GBDT。
为什么linearly Blending加α而uniformly Blending不加α,取决于怎么训练的模型。uniformly Blending之所以不加是因为我们公平地进行了一个随机抽样,而linearly Blending为什么会加?取决于训练的时候就决定了一定需要加了α才有意义。
Boosting是集成学习的一种思路,它通过多轮迭代生成多个弱分类器,它是用全部的数据,而Bagging不一定用全部的数据。Boosting通过多轮迭代,每轮产生一个弱分类器,最后将弱分类器的结果线性组合,得到强分类器的最终结果。
3、Adaboost例子:
我们先看下Adaboost的一个例子,对于下图:

假如只允许思考一秒钟,如何判断一个物体是苹果?

第一个人说圆的是苹果,那么会发现所有圆的里面,图上标的蓝色部分被分错了,有的是圆的,但是没有被标出来,有的是苹果,但是因为不是圆的所以也没被识别出来,总之就是看错了,弱分类器,允许犯错误。为了弥补这些错误,我们着重在错误的里面考虑,又发现红的是苹果。现在就是两个条件了,圆的和红的是苹果。发现在这两个条件下面,又有被分错的,如下图蓝色部分:

本来是苹果,因为颜色是绿色的所以在圆的和红的两个条件下面没有被识别出来。又因为番茄是圆的和红的,所以识别错了。再着重在错误的里面考虑,我们又会发现绿色的是苹果。这三个说法相当于我们每一次都得出一个弱分类器,来得出最后的判断。但是这3个弱分类器的靠谱程度显然不一样。我们需要组合去用他们,现在就得到了三个结果,一是圆的是苹果,二是红的是苹果,三是绿色是苹果,三不是很靠谱,翻译过来就是它的正确率不会太高,而前两个的正确率相对来说有点不相上下。我们给每一个赋予一个权重的概念,也就相当于投票。这三个投票的话,第一个靠谱一点的给它高一点权重,比如是1.5,第二个红的还可以,给1.45,绿的最差,给它0.1。比如我们拿下面的苹果做测试:

我们判断是不是苹果,就根据最后的结果,如果>0就是苹果<0不是苹果1。对于这一个来说,它不是红的,所以给它-1.5,对于第二个来说,它是圆的所以给+1.45,此时-1.5+1.45=-0.05,判断为不是苹果。但是如果跟第三个条件结合的话,-1.5+1.45+0.1=0.05。就会判断成苹果。而对于以下这种来说

因为是圆的和红色的所以,根据赋予的权重相加就是1.5+1.45,而对于第三个条件来说-0.1,不太怎么会影响最后的结果。所以说这些看起来不太靠谱的分类器,他们都是通过错误的子集训练出来的,在那些靠谱的分类器得不到正确结果的情况下,需要这些不太靠谱的分类器去平衡,而那些已经得到结论的时候它就不会太大程度的干扰结论。
我们通常称1,-1,0.1为权重。把错误的图片放大这个过程怎么理解?也就是在训练模型的时候,怎么实现让计算机考虑让分错的类别下次着重考虑?也是通过权重,那么这两个权重,是一个权重含义吗?肯定不是,因为第二个权重是跟着数据走的,在这个例子里是跟着每张图片走的,哪张图片大,也就是当前分错了,它权重就高一些;而第一个权重是跟着训练出来的分类器走的。我们把第一个叫做分类器权重,把第二个叫做数据权重。linearly Blending里有一个α,αgi(x)或者αgt(x) 。α跟着gi(x)走,gi(x)就是分类器得出来的结果,所以它是分类器权重,通常用α来表示。而数据权重通常用un来表示。
4、adaboost整体流程:
我们先粗略的看下adaboost的计算流程:
首先用全部数据训练一个弱分类器g1,弱分类器就能给出一个在训练集上,谁判断对了,谁判断错了的结果,我们利用结果修改训练集每一个数据的权重。 权重变了,训练出来的模型也就是新的弱分类器就跟以前不一样了,得到了g2。g2又能得到一组判断结果,这个判断结果又可以看它判断对了还是判断错了,之后又可以利用对错的结果去修改权数据权重,然后拿到新的数据权重,训练g3。一直循环,就达到了刚才苹果那个例子,拿到一堆弱分类器,但是每个人看的是一方面,最后大家综合讨论一下,结合所有人的意见,得到一个最终结果。这里需要强调下这是有监督的还是无监督的算法?答案是有监督的。因为我们必须知道每一个分类器对结果的判断对错,既然是判断对错就一定是有监督的,有了ŷ,没有yi怎么判断对错。所以在训练集上一定已经已知了yi,才有所谓的对错。总结下上面的描述,首先对样本赋予权重,赋予了权重这个值才能实现 着重看一下某些数据的这种方式,然后采用迭代的方式来构造每一步的弱分类器,最终通过弱分类器的linearly Blending(线性组合)得到强分类器,那么linearly Blending是G(x)= α1* g1(x)+ α2* g2(x)+……+αn* gn(x),如果用向量形式表示的话,就是[α1……αn]*[ g1(x)……gn(x)]。所以这个就表明了向量形式就是一种简写。它本质上就是这个东西,只不过我给它写成这种形式了。在这为什么没写行向量和列向量的点乘?向量的点乘也叫向量的内积,就是把前面向量跟后边向量对位相乘再相加,就是点乘的定义。[1,2,3]·[1,2,3],得到的结果是1×1+2×2+3×3,这是一种写法,它实际代表的还是咱们数学中的这些东西,所以所有线性代数它并不是发明了一种新的运算,它只是把特别长的一个式子给写成两个方块的形式了。
5、待解决问题:
了解了adaboost的计算流程之后,我们需要解决两个问题:
1、第一是如何迭代生成若干互不相同的g(x)。我们最终想要G(x),G(x)里边有两项,所有g(x)和所有的α;
2、第二是如何获得跟每一个x相配的与众不同的α。
6、解决第一个问题:如何获得不同的g(x):
我们一个一个来,先解决第一个问题。如何获得不同的g(x),也就是我们的每一个弱分类器。
我们先来回顾下随机森林的构造方式:也需要获得若干与众不同的g(x),通过bootstrap re-sample,re-sample就是有放回的重抽样,那么这里面g(x)有什么特点? 它们是公平的,它们训练过程中都是公平的,只不过每人看到的数据比较少,导致它比较弱。既然它是公平的,如何利用g(x)生成G(x)?均匀投票,每人一票不偏不倚。
而Adaboost:也需要得到若干不同的g(x),只是通过全部样本来获得,不再做bootstrap re-sample。如何让它与众不同?通过赋予样本不同的权重,就能获得不同的g(x)。这个权重是数据权重,通常用un来表示,为什么带一个n呢?说明有我们有N条样本,每一条样本背后都有自己的一个权重,代表我这条数据有多重要。重要多少取决于权重到底有多大,权重越大越重要。
对于Adaboost里面,所有boosting算法,都偏好于特别浅的层,不同于Bagging偏好深层。这个原因后面我们再具体解释。比如GBDT一般5到6层就够了,而Adaboost更加极端,通常使用1层。什么叫一层或者有的也叫两层?就是一分为二,每一个g(x)对数据就做一个一分为二,这个训练速度会很快。基分类器g(x)通常会使用decision-stump,stump是一个戳的概念或者桩子的概念。原来是一棵树,现在把上面都砍掉了就成了树桩了,它就像一个树桩一样,它只会一分为二,我们通常管它叫decision-stump。我们通过修改数据的权重,使本次训练的弱分类器在上次弱分类器做得不好的地方进行训练。跟刚才的例子是可以对应上的,你哪些地方做得不好,我就着重考虑你没做好的那些地方,这样最后投票的时候才能有所Boosting,有所提升。 为什么提升?因为每一棵树是对上一棵树的一个补强,而不是像原来弄出一大堆来,搞投票,它是一种补强的概念,它不能说更强,至少是把原来做的不好的地方给补上。
我们再普及下数据的正确率ACC怎么计算?正确的个数/总的个数,就是我们的普通形式的正确率。那么我们在Adaboost里边引入权重正确率。什么含义呢?数据又是怎么一个形式?假设我有N条数据,每一个数据都有一个权重记录它的重要性,假如第一条数据认为是0.1份的重要,第二条数据认为0.2份的重要,一直到最后一条数据。此时的权重正确率就不再是正确个数的总和了,而是正确样本对应权重的总和/总权重和。这代表每条数据不再认为它是同样的重要性了,而是有的数据重要,有的数据不重要。因此首先还得看每条数据是分对了还是分错了。excel举例说明下:

比如现在有五条数据,第一条数据权重0.1,第二条数据权重0.1,第三条数据权重0.5,第四条数据权重0.2,第五条数据权重1。假如已经训练出来一个分类器了,并且得到预测结果与真实结果的正确关系。此时它的权重正确率应该是(0.1+0.5+0.2)/(0.1+1)= 0.421,普通正确率是:正确的个数有3个,全部的个数5个,为0.6,所谓正确率ACC就是这么定义的,正确个数除以总个数。在没有数据权重的时候,通常都是追求正确率高,而加上数据权重了,我们此时去追求权重正确率高。假设决策桩(就是两层的决策树)就简单粗暴地以结果论英雄,我找到一个分裂条件,把数据就分成了两份,强制左边是+1,右边是-1,左边是正,右边是负。此时我遍历的条件不再是基尼系数了,不再是信息熵了,而是就看结果,谁的权重正确率最大,我就保留那种分裂条件。如果是这么一个机制的话,它会倾向于尽量把第五条样本数据判断对。因为第五条样本权重最高,一旦把它判断对了,根据权重正确率的计算方式,此时结果更容易获得高的权重正确率。
所以如果说要追求的是正确率最高,权重就没有用了,而如果我这棵树追求的是怎么分了之后权重正确率最高,它就会去尝试第一种分法权重正确率多少,第二种分法权重正确率是多少,当它突然尝试到某一种分法权重正确率特别高的时候,它就把此时分裂条件保留下来了。此时能保留下来的分裂条件更容易的把高权重的数据分队,因为只有高权重分对了,权重正确率才会相对容易高,不能说它绝对高。这样就叫做让计算机着重的去考虑高权重的数据,你给我尽量把它分对。
权重怎么来的?第一代的权重全是1,通过一次一次的迭代去改变的。对应苹果的例子,上来没有任何一张照片被放大了,直接看,此时每条数据是同等重要的。当权重全为1的时候,权重正确率和正确率就相等了。随着你迭代的加深,每一步样本权重一定是一直在变的,所以它变化就不一样了。迭代出来结果,有对错,我要把对的权重降低一点,把错的权重升高一点,下一个分类器就会着重去考虑上一个分类器没看到的问题。
这里不免有个问题,每次训练完了之后,要不要把正确的都踢出去,只在错误的里面重新训练?如果这样做的话,那就变成普通决策树了,普通决策树一分为二,在子集中再去分。 这里因为每次迭代都是全量的,改权重就够了,没必要把正确的剔出去了。注意这里的决策桩它的分裂条件是靠权重正确率判断的,而原来是基尼系数判断纯度。大体的规则是判断结果为对的要降低,判断结果为错的要升高,这样才能达到让后一代分类器,能着重看前一代分类器分错的这些东西,尽量把之前错的给分对。
而每次更改了权重都会生成一棵新的树,这些新的树之间彼此是什么关系? 这些树彼此之间看起来虽然是独立的,而且我这些树其实是桩子,都是一层的小树,现在新来一条数据的时候,也要加给每一个小树得到一个结果,之后我们就可以给每一个结果配上一个权重,α1* g1(x)+ α2* g2(x)+α3* g3(x)。这样就得到一个最终想要的G(x)。
而G(x)为什么有意义,参考刚才讲的例子,第一棵树看到的有可能就是红的权重正确率最高,然后通过放大了那些判断错的权重,第二棵树就认为红的是最好的,第三棵树会把所有绿的东西判断为苹果,然后再通过某种方法算出α,最终就得到了一个有道理的投票结果。
刚提到有两个权重,一个权重叫α,一个权重叫un,我们刚才跟着数据走的权重叫数据权重,通常用un来表示;而表达每一个分类器靠不靠谱的权重叫α,它是给最后预测结果去加一个权重,最后去组成G(x)用的。
α针对的是每一个弱分类器,α就是跟着小树走的,而un是跟着每条数据走的。 现在就知道它是通过某种方式计算出来的就可以了。un跟维度没关系,un要根据正确还是错误用,所以它是整条数据的权重,它不会去成到任何一个维度上。un是用来计算权重正确率的,你只要知道这条数据是判断对了,还是判断错了,对错是用yi和ŷ去比的,跟x并没有关系。x是遍历分裂条件的时候用的。因为我们生成一棵树需要遍历所有的分裂条件,x是因,而最后对错是果,你选了不好的x作为分裂条件会导致错误的特别多。
6.1 我们看下权重与函数的关系:
对于同一个算法 :
1、 训练集不同 ,生成的模型一定不同。
2、如果训练集相同,我们调整训练集中数据的权重,生成的模型也一定不同。
这个解释了为什么我们通过更新这一组un(它是捆绑在每一条数据后的一个数)之后就能获得一个新的G(x),因为G(x)在训练的过程中,它的机制就是要让权重正确率最高,权重变了肯定G(x)也会变。
对于同一个模型:
1、输入的数据权重不同, 模型预测的权重正确率也一定不同。
2、可以通过调整输入数据的权重, 让本来还不错的分类器的正确率达到1/2。
我们再来看下权重错误率的定义:
1、数据预测的错误率=错误数据的个数/全部数据的个数。刚才说的都是正确率,错误率也是一样的。
2、数据预测的权重错误率=预测错误数据的权重和/全部数据的权重和。
举例:有几个样本的实际标签yi是{+1,+1,+1,+1,-1},训练出来g1(x)分类器的预测结果是{+1,+1,+1,+1,+1},在所有权重都为1/5的时候,g1(x)的权重错误率是多少?错误率是多少?因为只对了一个,所以,错误率是0.2。如果权重都是1,权重错误率也是0.2,所以不太在乎权重相加到底等不等于1,我只是需要它的比例大。当-1这条样本数据权重是1/2,其它+1样本数据是1/8的时候权重正确率是多少?正确的权重和做分子,前四个正确了,它们的权重和就是1/2,总权重和是1,此时的权重正确率变成了0.5。既然ŷ没变,分类器就没变,分类器决定的其实是ŷ,ŷ还是ŷ,yi还是yi,但是当你把权重改了,权重正确率就变了。实际上分类器本身g1(x)一点都没变。所谓的把un2扔到g1(x)里边,这一组结果就是g1(x),算权重正确率的时候,你离不开权重,你把权重改了,同样的g1(x)的结果,它的权重正确率也变了。
6.2 gt和un的关系数学公式表达:
我们再来看下Adaboost中的数据权重un变化:
1、在训练集的每个数据背后都标注一个权重,初始权重设为1/N,也就是un1永远都等于1/N,或者说永远大家都等于1是一样的。
2、每一轮训练一个在当前权重下权重错误率最低,或者说权重正确率最高的g(x)。
3、然后迭代生成下一轮的权重。
考虑一下决策桩(decision-stump),如果下一轮数据的权重变了,训练出来分类器内部会发生什么改变?在刚才例子里,它会不会选择别的分裂维度去分裂?有可能会,刚才第一个是用圆和不圆分的,而改了权重之后,发现用绿和不绿分是更高的。既然如此,那我们就要考虑应该如何改变权重了,这个权重永远不去参与维度的运算,它只是最后用来加一加,最后算评分用的。先有两个函数,一个叫g函数,一个叫h函数,h函数从属于一个叫H的函数空间的。
解释一下,什么叫函数空间呢,就是你想象一个美好的世界里面生活着各种各样的函数,这些函数组成了一个函数空间,这个h是函数空间里的一员,在这个无穷无尽的函数里面,如果我们能找到一个能够让权重正确率最高的h,此时,恭喜你,你被升职了,你的名字叫做g,OK吧?虽然我们计算的是权重正确率,但其实大家的分母部分都是一样的,都是权重的总和,所以我们只需要找个分子部分最大的。也就是在H这个函数空间中,找到一个h,这个h能够使最后的权重错误率最小(或者权重正确率最大),此时这个h我们成为g。我们看下用公式怎么表达上面的思想:
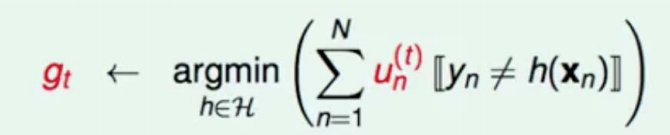
解释下上面公式:
首先所有t的标记都代表了第几棵树,因为我是一轮一轮迭代的,所以t1代表第一次的树,t2代表第二次的树,gt代表第t次的树,而gt+1代表gt的下一颗树,能理解吗?我们gt+1是通过gt生成出来的。那么gt有了就有了unt,我们知道un是训练集的前面的权重,是不是每一数据权重都会发生变化,所以迭代到t次我们是不是就有t个un?那un有多少个呢?un有N个,N是样本的数量,有多少个样本就有多少个un。
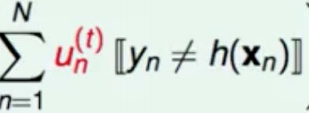
[[这两个中括号是if的意思,h是函数空间里找的那个h,也就是你尝试分裂的每一次树是不是就是一个h,它是一个候选人的概念,yn是数据真实的yn,也就是真实的标签,第n条数据的label。hxn是你扔给他之后它判断出来的结果。然后这个东西真实的标签不等于预测出来的标签的时候,这一项等于1否则就等于0,再通过加和它实际上是把所有错误的权重加了一遍和,因为不等于的时候是错误的时候,不等于的时候返回1,这里面它总共有n项加和,其中所有错误的项存活下来,正确的项因为这一项会返回零,就死掉了,所以最终这一项是所有错误的权重的和。我们要找的h是能够让错误权重和最小的那个h,也就是 正确权重和最大的那个h,所以我们找到了他就得到了gt,能理解吗?其实这个东西我解释了这么半天它就解释了一句话,就是当前轮的树训练的结果就是能够在当前的这个情况下表现权重错误率最小的那棵树。gt是能够让t轮的权重错误率最小的树,那gt+1自然就想让t+1轮的权重错误率最小的树。
6.3 引导Un+1的思路:
那我们思考一下,我现在待求的是什么?我希望它达到一个什么标准?也就是说你希望这个新的数据权重是什么样的呢?希望它扔在原来的弱分类器里错误率最小还是最大?思考一下这个问题,你想用新的权重训练出一个新的分类器来,这个新的分类器要做到原来的分类器做不到的地方,所以我们希望这个新的权重带入到原来的分类器里面是原来的弱分类器表现最差的权重,这样你用它表现的最弱的地方你才能训练出来一个补偿原来的弱分类器做不到的地方,能够理解我的意思吗?就相当于现在给你一副数据链让你做,你的了80分,对吗?接下来,你要做的是我就想针对你不会的那些题特训,你应该出一份什么卷子让他去学习,你应该出一份他先做只能做0分的卷子让他去学习,是不是才对他的提升是最大的?这个也是一样,你原来的弱分类器是在这个unt这轮表现得还不错了,那接下来我是不是要找一些你原来表现得不好的地方来着重训练才能训练出一个新的训练器,所以说新的权重应该是能够让原来的分类器在它上面测试是表现最差的,这个权重才能去补强下一个分类器,让下一个分类器具备这个分类器做不到的地方。
我们再捋一遍,我现在想训练新的分类器,新的分类器要有一个什么功能呢?要有一个旧的分类器做到不好的地方我要额外的好,我要补强你,对之前有所提升,那么如何让它有所提升呢?你就得训练新分类器的时候,将新分类器的权重带入到老分类器里面,并且是老分类器它做不到的地方进行训练,那怎么叫它做不到的呢,就是权重错误率最高就叫它做不到的地方,我不关注你做得好的地方,只关注做的最不好的地方。我最终要所有人一起投票,所有就是我不需要你做得好我也做得好,你做得差的我做好就行了,到时候投票的地方,你做得好的地方你负责说,你做的不好的地方我负责说,最后大家综合起来,得到结果,能明白吗?因为从一开始将那个苹果的例子就是让大家看你在错误的例子里面你怎么找到一个新的结果,能够理解吗?你提升的不是,一代比一代强,你提升的是最终的Gx。它是被提升的对象,通过什么提升,通过对不停的加进来原来做不到的地方他能做的好的分类器,好与不好是相对于每轮权重来说的,它是在这一轮权重上表现的好,并不是说他总体的好,我更新了权重也是想把他之前做的差的那些地方给补强了,让下一个分类器能够去重视。
所以我首先有了unt,我搞出来了一个gt,现在最终我想要的是gt+1,那怎么来呢?需要一个unt+1,那么gt+1跟gt有什么关系呢?就是希望gt+1在gt表现得不好的地方他能表现得好,gt+1不是设计出来的,而是训练出来的,你gt+1希望gt表现得不好的地方表现得好,那好,你就构建一个训练集,专门让gt表现得不好,能够理解吗?因为只要改变了这一组权重就会影响它的表现,对吧?我专门构建一个训练集让它表现得最不好,这个相当于对他特制的训练集就能够训练出来一个专门补强gt的训练器。
这个看完了大家大部分都绕过来了,那如何叫做gt在unt+1上表现得最不好呢?它的权重正确率和错误率应该等于多少?有人会说正确率为0是最不好的时候,其实正确率为0并不是最不好的,正确率如果为0了,你的模型反着用就是一个正确率百分之百的一个模型,那么最不好的分类模型永远是和瞎猜一样,这个叫最不好的模型,不会有任何规律可言,所以把旧的gt扔到新的unt+1上能够得到2/1的权重错误率,此时的unt+1就是我们要找的那个unt+1。因为错误率为1/2,就相当于瞎蒙一样。你之前的un甭管让gt得到一个什么样的权重正确率,无所谓。咱们不要骄傲自满,你0.99了我们也不在乎,我就专门出一个刁难你用的权重用它去训练下一个分类器,只有这样下一个分类器才能做到之前做不到的地方的补强,最终把他们聚合到一起的时候才会有各种各样不同的角度来看这个东西,所以如何得到下一轮的unt+1呢,我只需要让前一轮的错误率g(t)为2/1。
6.4 推导Un+1的由来:
接下来我们进行一些恒等推导,所谓恒等推导,就是拿等号左乘右乘导出来的一个结论。比如ax=3,x=3/a。
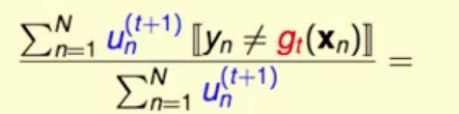
我们希望的是unt+1的所有权重在gt上的表现,使得gt的权重正确率是1/2,怎么能做到1/2,也就是错误的权重之和除以(错误的加上+正确的权重之和)为1/2。

我们希望 错误的总权重和/总权重和=1/2,其中橙色方块代表错误的总权重和,绿色圆圈代表正确的总权重和,绿色错误权重和指的是t+1轮的权重扔到t轮的分类器gt里的错误权重和。橙色指的是t+1轮的权重扔到t轮的分类器gt里面的正确权重和。我们希望t+1轮权重在g(t)上的错误权重和 = t+1轮在g(t)的权重的正确权重和。也就是所有的un (t+1)的incorrect等于un (t+1)的correct,即unt+1的总错误和等于总正确和的时候,权重错误率结果为1/2。即:

假设上一轮错误权重和是1126,正确权重和是6211,

我希望它俩能相等,就把上一轮的1126乘以上一轮的6211,6211乘以1126,它们俩就一定会相等,但这样越乘越大了,比较讨厌,我再除以一个7337,7337是什么?上一代的总权重和。所以相等的两端现在变成了(1126*6211)/7337=(6211*1126)/7337,这是一个恒等式。我们换个角度看这个公式,1126/7337是上一代的错误权重率,6211/7337是上一代的正确权重率。
对于左半部分(1126*6211)/7337可以看成是1126*(6211/7337)。而1126是所有的错误权重总和,6211/7337是正确权重率。这是一个加法分配率(a+b)*c=a*c+b*c。所以只要我让每一条数据,凡是你判断对了的乘以错误权重率,凡是你判断错误了的乘以正确权重率,即:

€t是t轮的权重错误率,1-€t是权重正确率。我们把所有正确的乘以€t;所有错误的乘以(1-€t),就能达到1/2的效果了。所以接下来我们的思路给大家捋一下,首先我有un了,我想算unt+1,接下来我要做的就是把从un训练出来的gt用到unt+1上,让它的表现是正确总权重等于错误总权重,怎么让正确总权重等于错误总权重呢?就是正确的总权重X错误率就等于原来的错误总权重X正确率,这样就相等了,那现在是对和的操纵,我们手里拿到的是一个一个的数据,那我怎么做这个数据呢?我就是让原来的正确的统统每一个都乘错误率,因为是有一个加法分配律,原来每一个错误都都X正确率,这样我是不是就得到了新一代的每一个权重也就是un(t+1)。
6.5 规划因子的由来:
然后你再宏观的看一下,一般是错误率高还是正确率高?肯定是正确率高,对吧?所以原来正确的都乘以一个比较小的数,原来错误的也乘以一个数,也变小了,大家统统都变小,正确的变得多,错误的变得少。而不是我们想要的错误的加大,正确的变小,所以我们加了一个规划因子,我们统统让正确的除以这个东西,错误的乘以这个东西,就能够达到我们想要的结果。为什么要这么做呢,我们推导下:
假设A为正确的总权重和,B为错误的总权重和,€是权重错误率,1-€是权重正确率。有A*€=B*(1-€),那么总权重和就是错误的权重和除以错误权重率,或者正确的权重和除以正确权重率,设总权重和C,则C=A/(1-€)= B/€。对于A*€=B*(1-€)这个式子里,都各乘一个C,则A*€*A/(1-€) = B*(1-€)*B/€。整理一下,是A*A*€/(1-€)= B*B*(1-€)/€。€/(1-€)和(1-€)/€是倒数关系,把两边开根号,就是A*sqrt(€/(1-€))= B* sqrt ((1-€)/€)。总结下上面公式推导如下:

(1-€)/€这一项,就是这里面的规范因子◆t,这里是错误的乘以根号下◆t ,如果正确乘以◆t的倒数,也就是除以◆t。即下面操作:

只要对un进行了这种操作,所有预测对的除◆t;所有预测错的乘◆t,我们就得到了unt+1,此时的unt+1就是把它扔进gt里,能够使gt得到权重正确率为1/2的那一组unt+1。
sqrt((1-€)/€),它是大于一的数还是小于一的数?通常是权重正确率高,€是错误率,分母是一个比较小的数,分子是一个比较大的数,结果是一个大于一的数。最后得到一个结果是:错误的乘以大于1的数,而正确的除以大于1的数,最后结果是错误的权重提升了,正确的权重减小了,而此刻还达到了1/2。 完美!!!
7、解决第二个问题:α的计算:
所以目前的整体流程是根据数据un1训练出来一个g1(x),然后根据g1(x)判断是否正确,有了g1(x)就有€t1,€t1就是un1在g1(x)上的表现。un2就是un1里边所有正确的除以◆t,所有错误的乘以◆t,就得到了un2,然后我们去计算g2(x)。有了g2(x)跟un2,我们就有€t2,就是un2在g2(x)上面的表现。就可以往复迭代下去了。那我们还差每个g上的α,g里面€t越低,α越大合适,€t越小就代表这个东西表现的还不错,要给它一个比较高的权重。
α怎么求呢,非常简单,α=ln ◆t,◆t=√((1-€)/€)。实际上是根据损失函数推出来的,α=ln ◆t肯定是一个大于0的正数,通常大于一,万一小于一会产生什么问题?ln的点,当x<1的时候就得到了负数。也就是说对于◆t<1的这么特别差的一个分类器,它算出来的α<0,代表它投的是负票。也不矛盾,它计算的正确率都已经不到0.5了,我们自然需要让它去投负票。我们可以看ln曲线的变化,
随着的◆t增大,也不会变大的特别快,也就是说你表现的是90份给你打的权重可能是1.2,你打了99分可能给你的权重是1.8变化的也不会特别多,所以加这么一个ln表现的不会这么明显,我们既要通过限制数的深度防止独裁也要通过限制α的设计上防止有些分类器的权重过高了导致的问题。这也正是为什么需要Ln的原因。
7.1 每一个弱分类器需要什么样的树:
假设是一个完全长成的树,也就是完全分对的树,它的优缺点各是什么?
优点:如果是完全长成的树€t会等于0,分的完全正确,此时的αt= ln ◆t=ln√((1-€)/€),当€=0的时候,αt等于正无穷,就产生了autocracy这个问题,独裁。容易导致一个问题---过拟合,这是个致命的缺点,一切运算效率上的缺点都可以忍受,但忍受不了的是这个模型过拟合一旦严重了就没法用了。假设α1的€=0,此时的G(x)中α1就是正无穷了,其它的没有意义了。最后G(x)等于多少就看g1等于多少了,此时的Adaboost就退化成一个完全长成的决策树了,就一定会带来过拟合的问题。别人再怎么加也干不过它。此时G(x)≈g1(x)。所以完全长成的树不能用。
如果不是用完全长成的树,树的层次稍微深一点的话,准确率高一点又会有什么情况呢?假如这棵树能准确率能到95%,此时的€很小,当€t特别小的时候,((1-€)/€)会变得特别大,权重也会变化特别大。它一定程度上能缓解过拟合的问题,不会让g1(x)独裁,但是很大的话,这个弱分类器的权重也会相对很大,所以虽然不会独裁,但是也不是我们所需要的。
所以我们在这里面倾向于最浅的树,也就是说倾向于pruned Dtree,被剪枝过的Dtree。一般只需要两层,我们称为决策桩(decision-stump),为什么需要决策桩呢,决策树不行吗?我们解剖下原因:
decision-stump是一个一分为二的决策树,它可以以权重正确率论英雄,去遍历所有的分裂节点,看哪种分出来之后权重正确率最高。我们思考一个问题,之前讲的决策树为什么不直接以ACC作为分裂结果,而要以纯度呢?传统决策树虽然没有权重,总可以用ACC,至少二分类的时候的正确率更高,为什么每次分裂不去分一个ACC更高的值呢?而是要用纯度这种间接的方式来判断哪种分裂条件好还是不好?因为在只有一层的情况下,可以分为左边是正例,右边是负例。但有多层的情况下,你能左边是正例,右边是负例吗?它并不一定能分好,强制的让它把正例都分左边,负例都分右边,不如每一步都让它去把纯度搞纯,最后再做投票,该是正例就是正例,该是负例就是负例,它如果只是一分为二,你可以简单说左边是1右边-1,因为有多层了,所以就不能直接用正确率强制的分左右,否则分出来决策树一定是表示正例的叶子节点,跟表示负例的叶子节点的数量是相同的,这样有可能并不是最好的结果。而是每一个叶子节点你都尽量把它分纯,让它越分越纯,虽然最后可能只有个别几个叶子节点表示负例,但仍然是能找到的最好的分类的方式。
假如Adaboost硬要使用一个不止两层的决策树作为弱分类器,它的权重应该如何用起来呢?对比决策桩的权重,直接拿过来算权重正确率,然后找分裂条件,而决策树不能这么干,那数据权重应该怎么用起来? 实际上通过按比例抽样的方式,这个权重不能直接丢到算法里去,对于decision-stump它能认识权重,但是对于decision-tree它不认识这个权重。于是就又要在训练集上做文章了,按照数据的权重的比例去抽样,比如样本集的权重分别是1,2,将来数据里就有1份第一条数据,2份第二条数据。重新构建一个符合数据权重比例的数据集,虽然决策树不认识这个权重,但是在构造训练集的时候已经把它按比例构造好了,它就可以认识权重了。通过这种间接的方式,相当于你的模型、算法是个黑盒,它认识不了权重,改一改数据集,让它在不需要认识权重的情况下,把权重的信息直接体现在数据集里面去,训练一棵decision-tree。但这样更麻烦,所以大部分时间就直接使用单层的决策树,也就是决策桩。我们会手动的限制让我们的每一个分类器尽量弱一点,怎么让它弱,对于决策树来说就需要将树的高度给限制掉,让它尽量的别自己分的太好,让它的正确率是0.6左右就可以了,还有兄弟姐妹们互相补强,这就是为什么要使用弱一些的树的原因。
8、具体总结Adaboost的整体流程:
1、初始化权重un1。un1是一组数,它的数量等于样本的数量。
2、开始迭代。
2.1 有un1可以理解为有第一个unt,根据unt训练gt。
2.2 gt根据在unt数据上的结果计算◆t
2.3 根据◆t可以算unt+1 。所有这个数据集上一代被判断错了的,都乘以◆t;上一代为判断对了的都除以◆t,就得到了下一代的u。
2.4 根据◆t可以算αt,就是ln◆t,这种迭代方式是在一次循环中同时产生两个迭代结果,和我们讲的L-BFGS类似,L-BFGS在迭代xk+1的时候,也要迭代一个dk+1出来,也是在同一轮循环中要得出两个结果,我们管这种迭代方式叫on the fly迭代。
3、迭代完成后,得到一组g(x),返回G(x)。
9、举例说明Adaboost的流程:
举例验证下一轮权重与上一轮权重的关系:
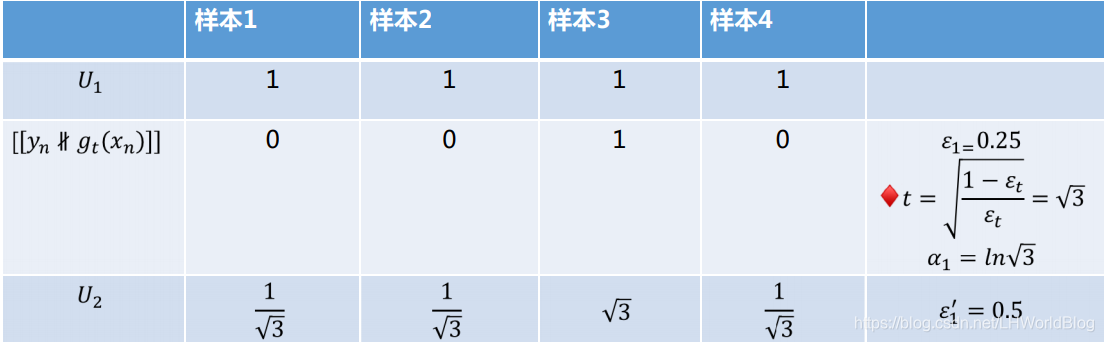
根据gt判断样本的正确性,判断对了gt就是0,判断错了gt就是1,此时的权重误差率是€=0.25,◆t是√3,α1是ln√3,此时我们就可以算出u2来了。把u2这组权重扔到g1里面去,此时的€=0.5,因为判断出来的结果是对对错对,所以根据u2计算出来的权重正确率是1/2。此时u2不是生凑的,而是确实有的乘以了◆t,有的除以了◆t,所有判断对的都除以了◆t,所有判断错的都乘以了◆t,最后结果等于了0.5。
10、总结Adaboost:
1. 把弱聚合强
2. 每次生成新的权重时放大一次错的, 缩小上一次对的。
3. 把得到的g(x) 线性组合得到G(x)。
Adaboost的优势是快,它比随机森林快好多,它虽然不能并行处理,但它只需要10,20颗树就够了。 90棵树和40棵树,差别已经不是很大了。
Adaboost的最早的应用,一炮成名是一个人脸识别的应用,在第一款数码相机上面能显示一个小框,识别出人脸的时候,背后算法就Adaboost。它是在Adaboost提出论文之后,第二年年底出来的产品,是当时的学术界向产业输出算相当快的。
为什么能在当时实现这个功能,当时其实早就可以通过神经网络来实现人脸识别了,但是数码相机的cpu根本就跑不起来,而Adaboost提供了一种轻量化的解决方案,它也能做到二分类,是人脸还是不是人脸。在这个算法底层还有好多计算机视觉方面做法,它要把图像分成多少个方块,怎么分最合理。
最后它判断每一张小方块图到底是不是人脸,通过Adaboost训练好的模型直接在里面去判断,模型是直接内嵌在固件里面,不需要你拿你的数码相机去训练模型,厂商训练好了模型,把这一组数的分裂条件存到了固件里面,然后它拿过来直接就跑这十个树,最后一投票结果到底是人脸还是不是人脸就出来了,它就会判断这个人脸到底在哪。这个是Adaboost最早成名的,它最早能在客户端实现能够达到人脸识别效果的这么一个算法。
最新文章
- Microsoft Dynamics CRM 2013 Js Odata 查询
- Android jar包的导出和使用
- java综合
- Android 下log的使用总结
- Mongodb使用
- CSS 3层嵌套居中布局
- Javascript Array Distinct (array.reduce实现)
- 《Programming WPF》翻译 第7章 7.我们进行到哪里了?
- 在Linux手动把文件转码的方法,防止乱码出现
- JS之For---in 语句
- JavaScript中Array.prototype.sort()的详解
- Timewarp 一种生成当中帧技术,异步时间扭曲(Asynchronous Timewarp)
- NodeJS初介
- 芝麻HTTP:代理的基本原理
- MySql foreach属性
- .net实现md5加密 sha1加密 sha256加密 sha384加密 sha512加密 des加密解密
- 关键字(3):order by/group by/having/where/sum/count(*)...查询结果筛选关键字
- 如何禁止某个linux用户访问某些文件夹及执行某些命令
- 如何在myeclipse中安装spket插件
- hexo d 报错‘fatal: could not read Username for 'https://github.com': No error’