GAN网络原理介绍和代码
2024-09-02 17:33:41
GAN网络的整体公式:

公式各参数介绍如下:
X是真实地图片,而对应的标签是1。
G(Z)是通过给定的噪声Z,生成图片(实际上是通过给定的Z生成一个tensor),对应的标签是0。
D是一个二分类网络,对于给定的图片判别真假。
D和G的参数更新方式:
D通过输入的真假图片,通过BCE(二分类交叉熵)更新自己的参数。
D对G(Z)生成的标签L,G尽可能使L为true,也就是1,通过BCE(二分类交叉熵)更新自己的参数。
公式演变:
对于G来说要使D无法判别自己生成的图片是假的,故而要使G(Z)越大越好,所以就使得V(G,D)越小越好;而对于D,使G(Z)越小D(X)越大,故而使V(G,D)越大越好

为了便于求导,故而加了log,变为如下:
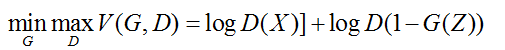
最后对整个batch求期望,变为如下:
基于mnist实现的GAN网络结构对应的代码
import itertools
import math
import time import torch
import torchvision
import torch.nn as nn
import torchvision.datasets as dsets
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from IPython import display
from torch.autograd import Variable
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
]) train_dataset = dsets.MNIST(root='./data/', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=100, shuffle=True) class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(784, 1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(256, 1),
nn.Sigmoid()
) def forward(self, x):
out = self.model(x.view(x.size(0), 784))
out = out.view(out.size(0), -1)
return out class Generator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(100, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(1024, 784),
nn.Tanh()
) def forward(self, x):
x = x.view(x.size(0), -1)
out = self.model(x)
return out discriminator = Discriminator().cuda()
generator = Generator().cuda()
criterion = nn.BCELoss()
lr = 0.0002
d_optimizer = torch.optim.Adam(discriminator.parameters(), lr=lr)
g_optimizer = torch.optim.Adam(generator.parameters(), lr=lr) def train_discriminator(discriminator, images, real_labels, fake_images, fake_labels):
discriminator.zero_grad()
outputs = discriminator(images)
real_loss = criterion(outputs, real_labels)
real_score = outputs outputs = discriminator(fake_images)
fake_loss = criterion(outputs, fake_labels)
fake_score = outputs d_loss = real_loss + fake_loss
d_loss.backward()
d_optimizer.step()
return d_loss, real_score, fake_score
def train_generator(generator, discriminator_outputs, real_labels):
generator.zero_grad()
g_loss = criterion(discriminator_outputs, real_labels)
g_loss.backward()
g_optimizer.step()
return g_loss # draw samples from the input distribution to inspect the generation on training
num_test_samples = 16
test_noise = Variable(torch.randn(num_test_samples, 100).cuda())
# create figure for plotting
size_figure_grid = int(math.sqrt(num_test_samples))
fig, ax = plt.subplots(size_figure_grid, size_figure_grid, figsize=(6, 6))
for i, j in itertools.product(range(size_figure_grid), range(size_figure_grid)):
ax[i, j].get_xaxis().set_visible(False)
ax[i, j].get_yaxis().set_visible(False) # set number of epochs and initialize figure counter
num_epochs = 200
num_batches = len(train_loader)
num_fig = 0 for epoch in range(num_epochs):
for n, (images, _) in enumerate(train_loader):
images = Variable(images.cuda())
real_labels = Variable(torch.ones(images.size(0)).cuda()) # Sample from generator
noise = Variable(torch.randn(images.size(0), 100).cuda())
fake_images = generator(noise)
fake_labels = Variable(torch.zeros(images.size(0)).cuda()) # Train the discriminator
d_loss, real_score, fake_score = train_discriminator(discriminator, images, real_labels, fake_images,
fake_labels) # Sample again from the generator and get output from discriminator
noise = Variable(torch.randn(images.size(0), 100).cuda())
fake_images = generator(noise)
outputs = discriminator(fake_images) # Train the generator
g_loss = train_generator(generator, outputs, real_labels) if (n + 1) % 100 == 0:
test_images = generator(test_noise) for k in range(num_test_samples):
i = k // 4
j = k % 4
ax[i, j].cla()
ax[i, j].imshow(test_images[k, :].data.cpu().numpy().reshape(28, 28), cmap='Greys')
display.clear_output(wait=True)
display.display(plt.gcf()) plt.savefig('results/mnist-gan-%03d.png' % num_fig)
num_fig += 1
print('Epoch [%d/%d], Step[%d/%d], d_loss: %.4f, g_loss: %.4f, '
'D(x): %.2f, D(G(z)): %.2f'
% (epoch + 1, num_epochs, n + 1, num_batches, d_loss.data[0], g_loss.data[0],
real_score.data.mean(), fake_score.data.mean())) fig.close()
最新文章
- Dapper学习笔记(1)-开始
- MVC Razor模板引擎输出HTML或者生产HTML文件
- 【英语】Bingo口语笔记(39) - Get系列
- 使用Busybox-1.2.0制作根文件系统
- EXCEL 2010学习笔记—— 动态图表
- Android Sensor Test
- 杭电oj 1328
- XSS跨站攻击
- Hibernate主键生成策略简单总结
- Windows store 验证你的 URL http:// 和 https:// ms-appx:/// ms-appdata:///local
- MVC区域小结
- WindowsAzure上把WebApp和WebService同时部署在一个WebRole中
- hack查询地址
- 前端笔记之NodeJS(二)路由&REPL&模块系统&npm
- 微信小程序注意点与快捷键
- winform Combobox出现System.Data.DataRowView的解决的方法
- SpringBoot(11) SpringBoot自定义拦截器
- 出现明明SQL语句没问题,但是却无法通过代码查询到结果的问题。
- (Review cs231n) Optimized Methods
- jquery引入
热门文章
- Lucene&Solr框架之第一篇
- ES6中常用的小技巧,用了事半功倍哦
- 验证apk签名方式(V1 || V2)
- SolrCloud 高可用集群搭建
- Configuration on demand is not supported by the current version of the Android Gradle plugin since you are using Gradle version 4.6 or above. Suggestion: disable configuration on demand by setting org
- MongoDB学习笔记(六、MongoDB复制集与分片)
- 批量修改含空格的文件名「Linux」
- [译]Vulkan教程(28)Image视图和采样器
- Java连载54-两种单例模式、接口详解
- idea中导入别人的vue项目并运行