使用python做一个爬虫GUI程序
2024-08-27 14:15:55
整体思路和之前的一篇博客爬虫豆瓣美女一致,这次加入了图片分类,同时利用tkinter模块做成GUI程序
效果如下:
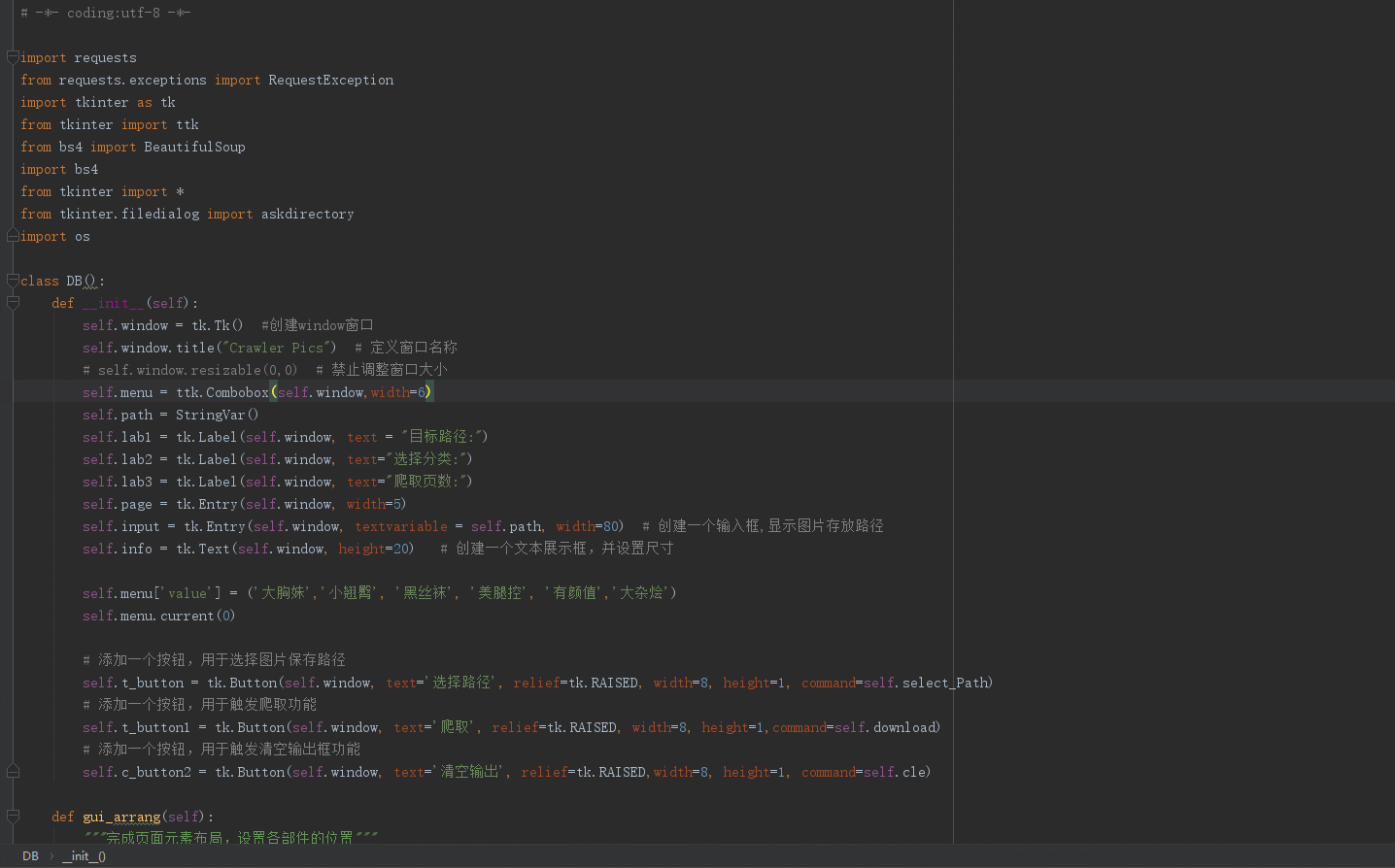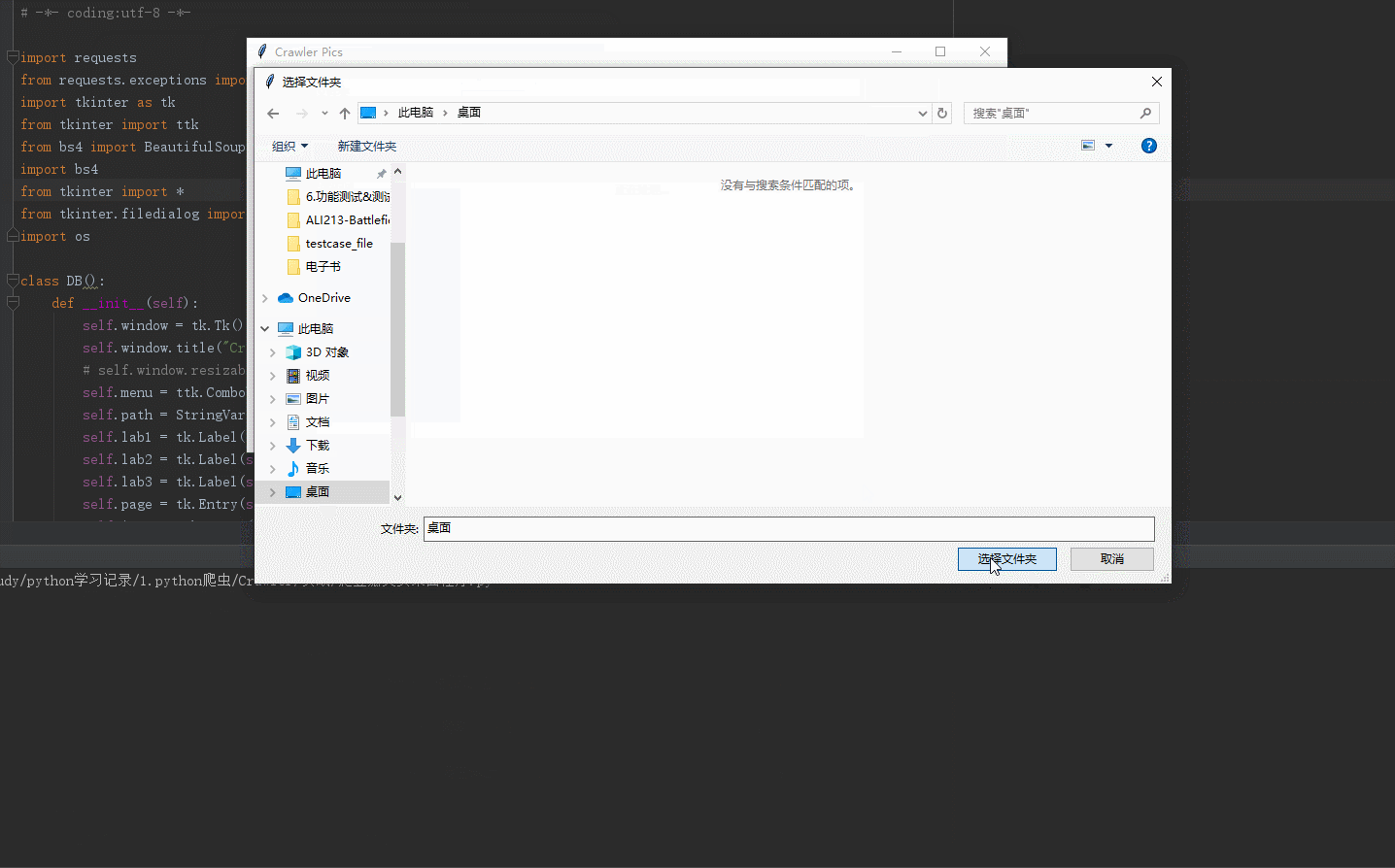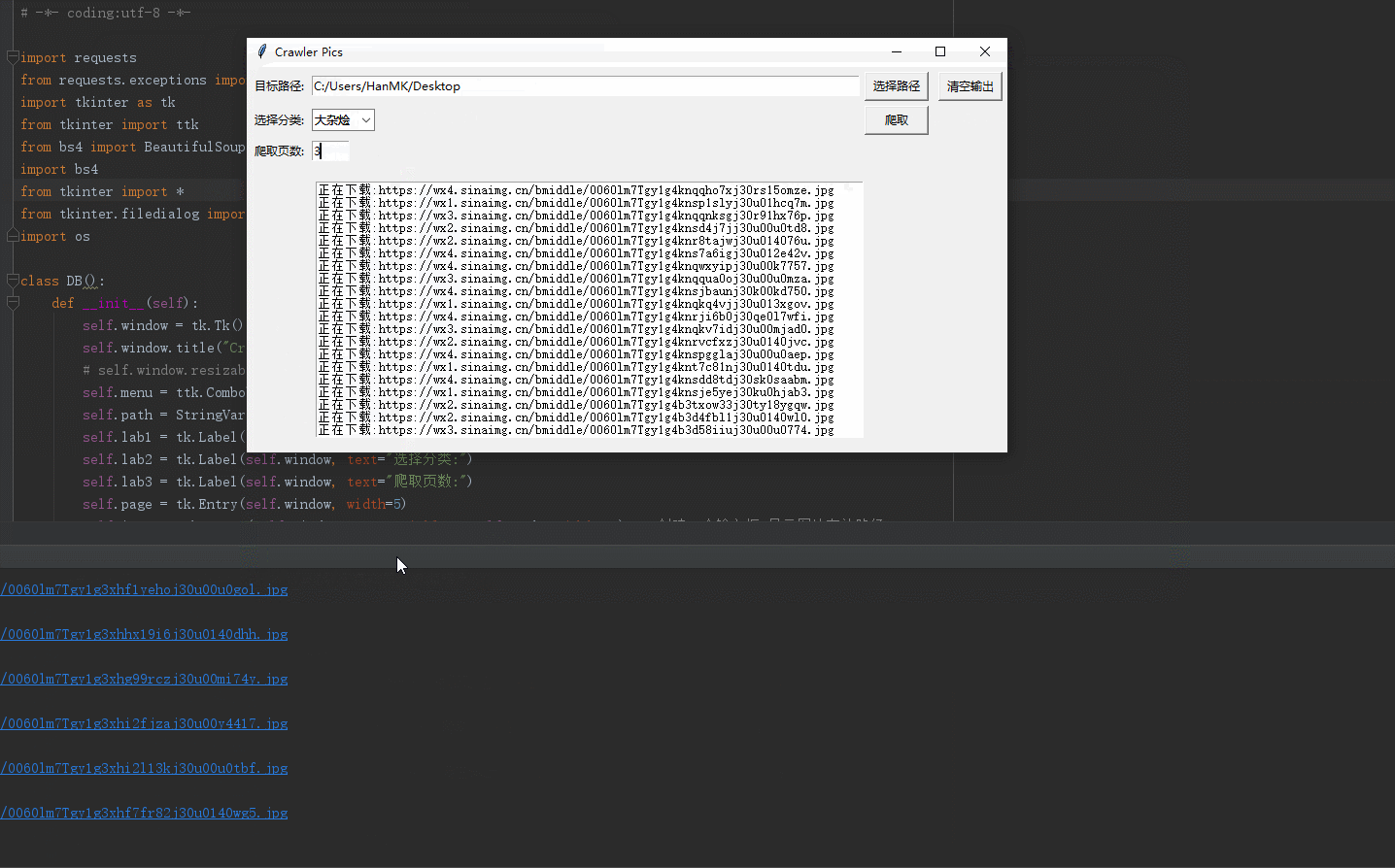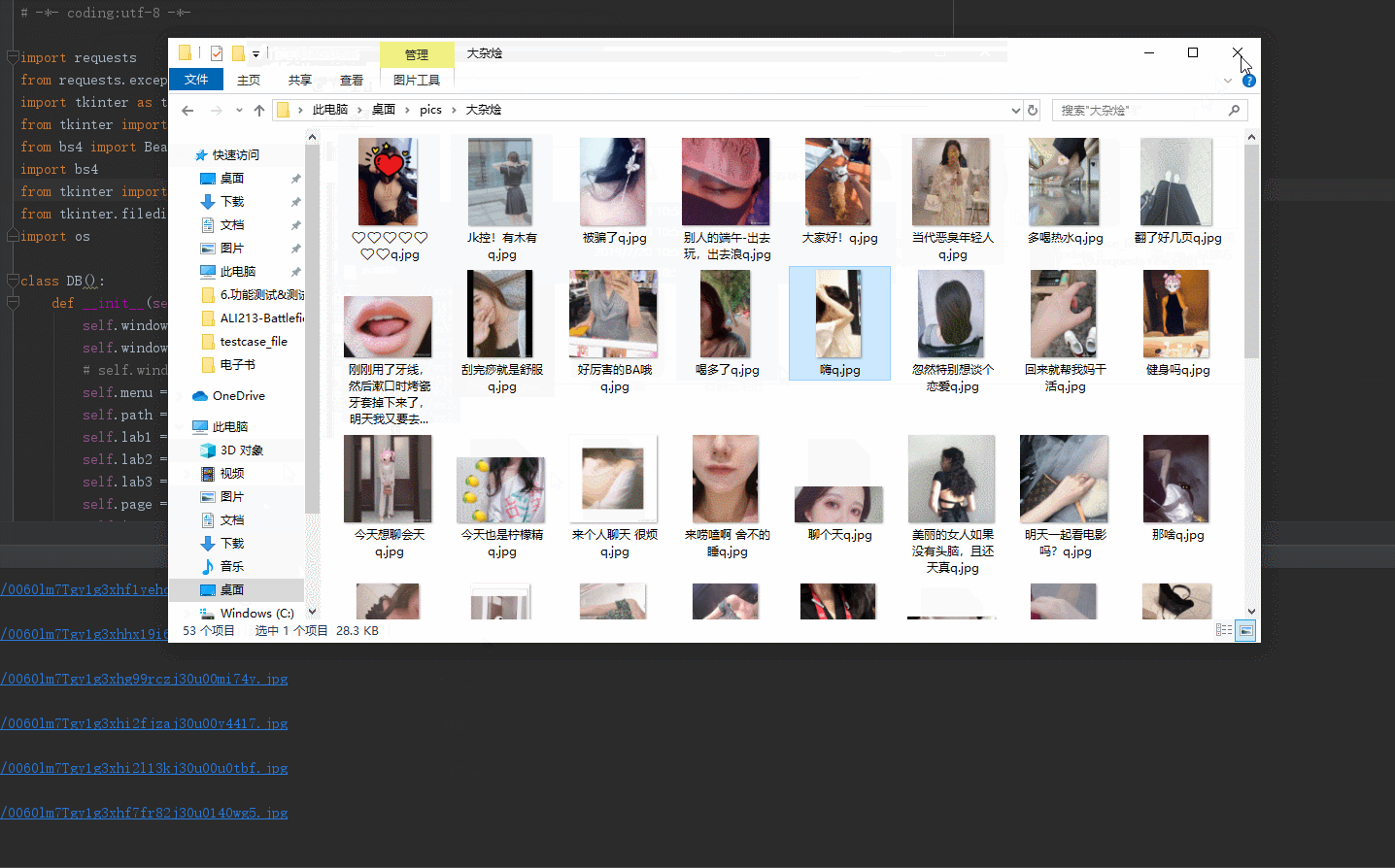
整体代码如下:
# -*- coding:utf-8 -*- import requests
from requests.exceptions import RequestException
import tkinter as tk
from tkinter import ttk
from bs4 import BeautifulSoup
import bs4
from tkinter import *
from tkinter.filedialog import askdirectory
import os class DB():
def __init__(self):
self.window = tk.Tk() #创建window窗口
self.window.title("Crawler Pics") # 定义窗口名称
# self.window.resizable(0,0) # 禁止调整窗口大小
self.menu = ttk.Combobox(self.window,width=6)
self.path = StringVar()
self.lab1 = tk.Label(self.window, text = "目标路径:")
self.lab2 = tk.Label(self.window, text="选择分类:")
self.lab3 = tk.Label(self.window, text="爬取页数:")
self.page = tk.Entry(self.window, width=5)
self.input = tk.Entry(self.window, textvariable = self.path, width=80) # 创建一个输入框,显示图片存放路径
self.info = tk.Text(self.window, height=20) # 创建一个文本展示框,并设置尺寸 self.menu['value'] = ('大胸妹','小翘臀', '黑丝袜', '美腿控', '有颜值','大杂烩')
self.menu.current(0) # 添加一个按钮,用于选择图片保存路径
self.t_button = tk.Button(self.window, text='选择路径', relief=tk.RAISED, width=8, height=1, command=self.select_Path)
# 添加一个按钮,用于触发爬取功能
self.t_button1 = tk.Button(self.window, text='爬取', relief=tk.RAISED, width=8, height=1,command=self.download)
# 添加一个按钮,用于触发清空输出框功能
self.c_button2 = tk.Button(self.window, text='清空输出', relief=tk.RAISED,width=8, height=1, command=self.cle) def gui_arrang(self):
"""完成页面元素布局,设置各部件的位置"""
self.lab1.grid(row=0,column=0)
self.lab2.grid(row=1, column=0)
self.menu.grid(row=1, column=1,sticky=W)
self.lab3.grid(row=2, column=0,padx=5,pady=5,sticky=tk.W)
self.page.grid(row=2, column=1,sticky=W)
self.input.grid(row=0,column=1)
self.info.grid(row=3,rowspan=5,column=0,columnspan=3,padx=15,pady=15)
self.t_button.grid(row=0,column=2,padx=5,pady=5,sticky=tk.W)
self.t_button1.grid(row=1,column=2)
self.c_button2.grid(row=0,column=3,padx=5,pady=5,sticky=tk.W) def get_cid(self):
category = {
'DX': 2,
'XQT': 6,
'HSW': 7,
'MTK': 3,
'YYZ': 4,
'DZH': 5
}
cid = None
if self.menu.get() == "大胸妹":
cid = category["DX"]
elif self.menu.get() == "小翘臀":
cid = category["XQT"]
elif self.menu.get() == "黑丝袜":
cid = category["HSW"]
elif self.menu.get() == "美腿控":
cid = category["MTK"]
elif self.menu.get() == "有颜值":
cid = category["YYZ"]
elif self.menu.get() == "大杂烩":
cid = category["DZH"]
return cid def select_Path(self):
"""选取本地路径"""
path_ = askdirectory()
self.path.set(path_) def get_html(self, url, header=None):
"""请求初始url"""
response = requests.get(url, headers=header)
try:
if response.status_code == 200:
# print(response.status_code)
# print(response.text)
return response.text
return None
except RequestException:
print("请求失败")
return None def parse_html(self, html, list_data):
"""提取img的名称和图片url,并将名称和图片地址以字典形式返回"""
soup = BeautifulSoup(html, 'html.parser')
img = soup.find_all('img')
for t in img:
if isinstance(t, bs4.element.Tag):
# print(t)
name = t.get('alt')
img_src = t.get('src')
list_data.append([name, img_src])
dict_data = dict(list_data)
return dict_data def get_image_content(self, url):
"""请求图片url,返回二进制内容"""
print("正在下载", url)
self.info.insert('end',"正在下载:"+url+'\n')
try:
r = requests.get(url)
if r.status_code == 200:
return r.content
return None
except RequestException:
return None def download(self):
base_url = 'https://www.dbmeinv.com/index.htm?'
for i in range(1, int(self.page.get())+1):
url = base_url + 'cid=' + str(self.get_cid()) + '&' + 'pager_offset=' + str(i)
# print(url)
header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q = 0.9, image/webp,image/apng,*/*;q='
'0.8',
'Accept-Encoding': 'gzip,deflate,br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'www.dbmeinv.com',
'Upgrade-Insecure-Requests': '',
'User-Agent': 'Mozilla/5.0(WindowsNT6.1;Win64;x64) AppleWebKit/537.36(KHTML, likeGecko) Chrome/'
'70.0.3538.102Safari/537.36 '
}
list_data = []
html = self.get_html(url)
# print(html)
dictdata = self.parse_html(html, list_data) root_dir = self.input.get()
case_list = ["大胸妹", "小翘臀", "黑丝袜", "美腿控", "有颜值", "大杂烩"]
for t in case_list:
if not os.path.exists(root_dir + '/pics'):
os.makedirs(root_dir + '/pics')
if not os.path.exists(root_dir + '/pics/' + str(t)):
os.makedirs(root_dir + '/pics/' + str(t)) if self.menu.get() == "大胸妹":
save_path = root_dir + '/pics/' + '大胸妹'
for t in dictdata.items():
try:
# file_path = '{0}/{1}.{2}'.format(save_path, t[1], 'jpg')
file_path = save_path + '/' + t[0] + 'q' + '.jpg'
if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取
with open(file_path, 'wb') as f:
f.write(self.get_image_content(t[1]))
f.close()
print('文件保存成功')
except FileNotFoundError:
continue elif self.menu.get() == "小翘臀":
save_path = root_dir + '/pics/' + '小翘臀'
for t in dictdata.items():
try:
# file_path = '{0}/{1}.{2}'.format(save_path, t[1], 'jpg')
file_path = save_path + '/' + t[0] + 'q' + '.jpg'
if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取
with open(file_path, 'wb') as f:
f.write(self.get_image_content(t[1]))
f.close()
print('文件保存成功')
except FileNotFoundError:
continue elif self.menu.get() == "黑丝袜":
save_path = root_dir + '/pics/' + '黑丝袜'
for t in dictdata.items():
try:
# file_path = '{0}/{1}.{2}'.format(save_path, t[1], 'jpg')
file_path = save_path + '/' + t[0] + 'q' + '.jpg'
if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取
with open(file_path, 'wb') as f:
f.write(self.get_image_content(t[1]))
f.close()
print('文件保存成功')
except FileNotFoundError:
continue elif self.menu.get() == "美腿控":
save_path = root_dir + '/pics/' + '美腿控'
for t in dictdata.items():
try:
# file_path = '{0}/{1}.{2}'.format(save_path, t[1], 'jpg')
file_path = save_path + '/' + t[0] + 'q' + '.jpg'
if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取
with open(file_path, 'wb') as f:
f.write(self.get_image_content(t[1]))
f.close()
print('文件保存成功')
except FileNotFoundError:
continue elif self.menu.get() == "有颜值":
save_path = root_dir + '/pics/' + '有颜值'
for t in dictdata.items():
try:
# file_path = '{0}/{1}.{2}'.format(save_path, t[1], 'jpg')
file_path = save_path + '/' + t[0] + 'q' + '.jpg'
if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取
with open(file_path, 'wb') as f:
f.write(self.get_image_content(t[1]))
f.close()
print('文件保存成功')
except OSError:
continue elif self.menu.get() == "大杂烩":
save_path = root_dir + '/pics/' + '大杂烩'
for t in dictdata.items():
try:
# file_path = '{0}/{1}.{2}'.format(save_path, t[1], 'jpg')
file_path = save_path + '/' + t[0] + 'q' + '.jpg'
if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取
with open(file_path, 'wb') as f:
f.write(self.get_image_content(t[1]))
f.close()
print('文件保存成功')
except FileNotFoundError:
continue def cle(self):
"""定义一个函数,用于清空输出框的内容"""
self.info.delete(1.0,"end") # 从第一行清除到最后一行 def main():
t = DB()
t.gui_arrang()
tk.mainloop() if __name__ == '__main__':
main()
关键点:
1.如何使用tkinter调用系统路径
2.构造url,参数化图片分类、抓取页数
3.使用tkinter获取输入参数传给执行代码
下面是练习的时候写的简陋版,不包含tkinter,主要是理清思路:
import re
import requests
import os
from requests.exceptions import RequestException case = str(input("请输入你要下载的图片分类:"))
category = {
'DX': 2,
'XQT': 6,
'HSW': 7,
'MTK': 3,
'YYZ': 4,
'DZH': 5
}
def get_cid():
cid = None
if case == "大胸妹":
cid = category["DX"]
elif case == "小翘臀":
cid = category["XQT"]
elif case == "黑丝袜":
cid = category["HSW"]
elif case == "美腿控":
cid = category["MTK"]
elif case == "有颜值":
cid = category["YYZ"]
elif case == "大杂烩":
cid = category["DZH"]
return cid base_url = 'https://www.dbmeinv.com/index.htm?'
url = base_url + 'cid=' + str(get_cid())
r = requests.get(url)
# print(r.status_code)
html = r.text
# print(r.text)
# print(html) name_pattern = re.compile(r'<img class="height_min".*?title="(.*?)"', re.S)
src_pattern = re.compile(r'<img class="height_min".*?src="(.*?.jpg)"', re.S) name = name_pattern.findall(html) # 提取title
src = src_pattern.findall(html) # 提取src
data = [name,src]
# print(name)
# print(src)
d=[]
for i in range(len(name)):
d.append([name[i], src[i]]) dictdata = dict(d)
# for i in dictdata.items():
# print(i) def get_content(url):
try:
r = requests.get(url)
if r.status_code == 200:
return r.content
return None
except RequestException:
return None root_dir = os.path.dirname(os.path.abspath('.')) case_list = ["大胸妹","小翘臀","黑丝袜","美腿控","有颜值","大杂烩"]
for t in case_list:
if not os.path.exists(root_dir+'/pics'):
os.makedirs(root_dir+'/pics')
if not os.path.exists(root_dir+'/pics/'+str(t)):
os.makedirs(root_dir+'/pics/'+str(t)) def Type(type):
save_path = root_dir + '/pics/' + str(type)
# print(save_path)
for t in dictdata.items():
try:
#file_path = '{0}/{1}.{2}'.format(save_path, t[1], 'jpg')
file_path = save_path + '/' + t[0]+ 'q' +'.jpg'
print("正在下载: "+'"'+t[0]+'"'+t[1])
if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取
with open(file_path, 'wb') as f:
f.write(get_content(t[1]))
f.close()
except FileNotFoundError:
continue
if case == "大胸妹":
Type(case) elif case == "小翘臀":
Type(case) elif case == "黑丝袜":
Type(case) elif case == "美腿控":
Type(case) elif case == "有颜值":
Type(case) elif case == "大杂烩":
Type(case)
效果如下

最新文章
- block,inline和inlinke-block细节对比
- java中的日期操作Calendar和Date
- Neutron VxLAN + Linux Bridge 环境中的网络 MTU
- 使用htmlunit在线解析网页信息
- hdu---------(1026)Ignatius and the Princess I(bfs+dfs)
- 照片浏览器软件-WTL开发的照片浏览器
- Oracle除去换行符的方法
- React 入门最好的实例-TodoList
- 使用PHP实现请求响应和MySql访问
- c++,operator=
- String,StringBuffer与StringBuilder差异??
- struts2+jquery +json实现异步加载数据,亲测(原创)
- mybatis一对一映射配置详解
- (五)jdk8学习心得之默认方法
- 点评cat系列-应用集成
- Android-Java-普通类与抽象类(覆盖)&方法重载
- JsBom
- JAVA JSON解析:类XPATH解析JSON
- SQL中varchar和nvarchar有什么区别
- 筛选datatable