Pandas常用基本功能
Series 和 DataFrame还未构建完成的朋友可以参考我的上一篇博文:https://www.cnblogs.com/zry-yt/p/11794941.html
当我们构建好了 Series 和 DataFrame 之后,我们会经常使用哪些功能呢?引用上一章节中的场景,我们有一些用户的的信息,并将它们存储到了 DataFrame 中。因为大多数情况下 DataFrame 比 Series 更为常用,所以这里以 DataFrame 举例说明,但实际上很多常用功能对于 Series 也适用。
此为上一章节完成的DataFrame
import pandas as pd
index = pd.Index(data=["Tom", "Bob", "Mary", "James"], name="name")
data = {
"age": [18, 30, 25, 40],
"city": ["BeiJing", "ShangHai", "GuangZhou", "ShenZhen"],
"sex": ["male", "male", "female", "male"]
}
user_info = pd.DataFrame(data=data, index=index)
user_info """
age city sex
name
Tom 18 BeiJing male
Bob 30 ShangHai male
Mary 25 GuangZhou female
James 40 ShenZhen male
"""
常用基本功能
了解数据的整体情况
user_info.info() """
<class 'pandas.core.frame.DataFrame'>
Index: 4 entries, Tom to James
Data columns (total 3 columns):
age 4 non-null int64
city 4 non-null object
sex 4 non-null object
dtypes: int64(1), object(2)
memory usage: 128.0+ bytes
"""
查看头部、尾部的n条数据
查看头部 --> .head(n)
# 查看前三条数据
user_info.head(3)
查看尾部 --> .tail(n)
# 查看最后两条数据
user_info.tail(2)
获取Pandas 中数据结构的方法和属性
通过 .shape 获取数据的形状
user_info.shape # (4, 3)
"""
age city sex
name
Tom 18 BeiJing male
Bob 30 ShangHai male
Mary 25 GuangZhou female
James 40 ShenZhen male
"""
通过 .T 获取数据的转置。
user_info.T
"""
name Tom Bob Mary James
age 18 30 25 40
city BeiJing ShangHai GuangZhou ShenZhen
sex male male female male
"""
通过 .values 获取原有数据
user_info.values
"""
array([[18, 'BeiJing', 'male'],
[30, 'ShangHai', 'male'],
[25, 'GuangZhou', 'female'],
[40, 'ShenZhen', 'male']], dtype=object)
"""
描述与统计
查看数据的简单统计指标
user_info.age.max() # 查看年龄的最大值
user_info.age.min() # 查看年龄的最小值
user_info.age.mean() # 查看年龄的平均值
user_info.age.quantile() # 查看年龄的中位数
user_info.age.sum() # 查看年龄的总和 user_info.age.cumsum() # 累加求和
"""
name
Tom 18
Bob 48
Mary 73
James 113
Name: age, dtype: int64
"""
一次性获取多个统计指标
查看数字类型列的一些统计指标:如 总数、平均数、标准差、最小值、最大值、25% / 50% / 75% 分位数
user_info.describe()
查看非数字类型的列的统计指标:如 总数,去重后的个数、最常见的值、最常见的值的频数
user_info.describe(include=["object"])
统计某列中每个值出现的次数
# 统计sex列值出现的次数
user_info.sex.value_counts()
"""
male 3
female 1
Name: sex, dtype: int64
"""
获取某列最大值或最小值对应的索引
# 获取年龄最大的索引
user_info.age.idxmax() # 'James'
# 获取年龄最小的索引
user_info.age.idxmin() # 'Tom'
离散化
数值区间为(a,b]
.cut
根据每个值的大小来进行离散化,自动生成等距的离散区间
# 将年龄分成3个区间
pd.cut(user_info.age,3)
"""
name
Tom (17.978, 25.333]
Bob (25.333, 32.667]
Mary (17.978, 25.333]
James (32.667, 40.0]
Name: age, dtype: category
Categories (3, interval[float64]): [(17.978, 25.333] < (25.333, 32.667] < (32.667, 40.0]]
"""
自定义区间与标签
pd.cut(user_info.age,[10,24,36,50],labels=["child",'youth',"middle"])
"""
user_index
Tom child
Scott child
Jass middle
Jame middle
Name: age, dtype: category
Categories (3, object): [child < youth < middle]
"""
.qcut
根据每个值出现的次数来进行离散化
pd.qcut(user_info.age,3)
"""
name
Tom (17.999, 25.0]
Bob (25.0, 30.0]
Mary (17.999, 25.0]
James (30.0, 40.0]
Name: age, dtype: category
Categories (3, interval[float64]): [(17.999, 25.0] < (25.0, 30.0] < (30.0, 40.0]]
"""
练习
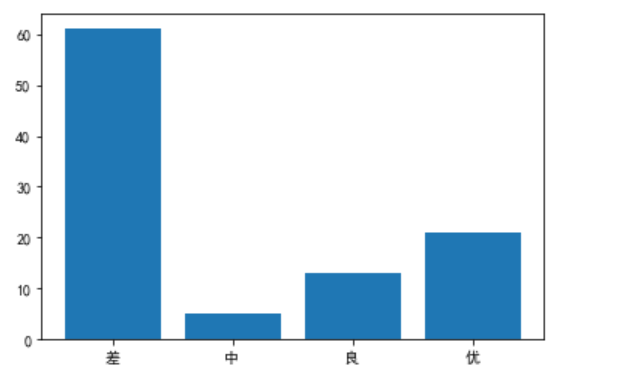
随机生成 100 个数作为考试成绩,给成绩设定优良中差,比如:0-59 分为差,60-70 分为中,71-80 分为良,81-100 为优秀,统计每个区间上的人数。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 种子
np.random.seed(10)
# 生成0-100的随机数字100个
data = np.random.randint(0,101,100)
# 准备区间名字
labels=["差","中","良","优"]
# 将区间显示为自定义区间名
count=pd.cut(data,[-1,59,70,80,100],labels=labels)
# 统计次数
count=count.value_counts()
# 画直方图,横轴为标签,纵轴为数量
plt.bar(labels,count)
# 防止中文编码错误
plt.rcParams['font.sans-serif']=['SimHei']
排序功能
Pandas 支持两种排序方式:
- 按轴(索引或列)排序
- 按实际值排序
按索引排序
.sort_index:默认是按照索引进行正序排的
user_info.sort_index()
按列名进行倒序排
设置参数 axis=1 和 ascending=False
user_info.sort_index(axis=1, ascending=False)
按照实际值来排序
.sort_values:后接需要排序的参数(默认升序)
# 按年龄排序
user_info.sort_values(by="age")
按照多个值来排序
# 先按年龄排序,再按城市排序
# list 中每个元素的顺序会影响排序优先级
user_info.sort_values(by=["age", "city"])
获取字段最大/小的 n 个值
# 获取年龄最大的两个值
user_info.age.nlargest(2)
# 获取年龄最小的两个值
user_info.age.nsmallest (2) """
注意:该方法比先排序再取head()或者tail()效率高
"""
函数应用
虽说 Pandas 为我们提供了非常丰富的函数,有时候我们可能需要自己定制一些函数,并将它应用到 DataFrame 或 Series。常用到的函数有: map 、 apply 、 applymap 。
map 方法
map 是 Series 中特有的方法,通过它可以对 Series 中的每个元素实现转换。
#通过年龄判断用户是否属于中年人(30岁以上为中年)
# 接收一个 lambda 函数
user_info.age.map(lambda x: "yes" if x >= 30 else "no")
"""
name
Tom no
Bob yes
Mary no
James yes
Name: age, dtype: object
""" # 通过城市来判断是南方还是北方
city_map = {
"BeiJing": "north",
"ShangHai": "south",
"GuangZhou": "south",
"ShenZhen": "south"
}
# 传入一个 map
user_info.city.map(city_map)
"""
name
Tom north
Bob south
Mary south
James south
Name: city, dtype: object
"""
apply方法
既支持 Series,也支持 DataFrame,在对 Series 操作时会作用到每个值上,在对DataFrame 操作时会作用到所有行或所有列(通过 axis 参数控制)
对 Series 来说,apply 方法 与 map 方法区别不大。
user_info.age.apply(lambda x: "yes" if x >= 30 else "no")
对 DataFrame 来说,apply 方法的作用对象是一行或一列数据(一个Series)
user_info.apply(lambda x: x.max(), axis=0)
"""
age 40
city ShenZhen
sex male
dtype: object
"""
applymap 方法
applymap 方法针对于 DataFrame,它作用于 DataFrame 中的每个元素,它对 DataFrame 的效果类似于 apply 对 Series 的效果
# .upper()将所有的英文字母大写
# .lower()将所有的英文字母小写
user_info.applymap(lambda x: str(x).upper())
"""
age city sex
name
Tom 23 BEIJING MALE
Bob 30 SHANGHAI MALE
Mary 25 GUANGZHOU FEMALE
James 40 SHENZHEN MALE
"""
修改列/ 索引名称
.rename ()
修改列
user_info.rename(columns={"age": "Age", "city": "City", "sex":
"Sex"})
修改索引
user_info.rename(index={"Tom": "tom", "Bob": "bob"})
类型操作
获取每种类型的列数
user_info.get_dtype_counts()
"""
int64 1
object 2
dtype: int64
"""
转换数据类型
user_info["age"].astype(float)
"""
name
Tom 23.0
Bob 30.0
Mary 25.0
James 40.0
Name: age, dtype: float64
"""
将 object 类型转为其他类型
object --> 数字 --> .to_numeric
object --> 日期 --> .to_datetime
object --> 时间差 --> .to_timedelta
#添加身高字段
user_info["height"] = ["", "", "", "180cm"]
"""
age city sex height
name
Tom 23 BeiJing male 178
Bob 30 ShangHai male 168
Mary 25 GuangZhou female 178
James 40 ShenZhen male 180cm
"""
"""
将身高这一列转为数字,很明显,180cm 并非数字,为了强制转换,我们可以传入 errors 参数,这个参数的作用是当强转失败时的处理方式。
默认情况下errors='raise':意味着强转失败后直接抛出异常
设置errors='coerce':可以在强转失败时将有问题的元素赋值为 pd.NaT(对于datetime或timedelta)或 np.nan(数字)
设置 errors='ignore':可以在强转失败时返回原有的数据。
""" pd.to_numeric(user_info.height, errors="coerce")
"""
name
Tom 178.0
Bob 168.0
Mary 178.0
James NaN
Name: height, dtype: float64
""" pd.to_numeric(user_info.height, errors="ignore")
"""
name
Tom 178
Bob 168
Mary 178
James 180cm
Name: height, dtype: object
"""
最新文章
- VMware Workstation 10+Centos7(64位)共享文件夹
- Mybatis 后台SQL不输出
- sublime text 如何设置”在浏览器浏览“的快捷键
- [转] Making GTFS query more convenient
- WinStore控件之Button
- 明白python文件如何组织,理解建立源文件
- html5画图和本地存储
- lecode Interleaving String
- #include <array>
- iOS很重要的 block回调
- Xpath语法学习
- 浅析 JavaScript 中的 Function.prototype.bind() 方法
- Educational Codeforces Round 62 (Rated for Div. 2) C 贪心 + 优先队列 + 反向处理
- Git分支管理的策略梳理
- python中的协程:greenlet和gevent
- 【题解】Luogu P1533 可怜的狗狗
- python 移动文件夹
- 《centos系列》ubuntu终端链接centos服务器
- 在Visual Studio中使用层关系图描述系统架构、技术栈
- Linxu安装Tomcat与Jdk并卸载自带OpenJdk