开源文字识别软件tesseract
2024-09-02 07:42:40
1.下载4.0软件,下一步下一步到成功;
2.安装之后配置环境变量,Path中添加安装路径(默认:C:\Program Files (x86)\Tesseract-OCR)
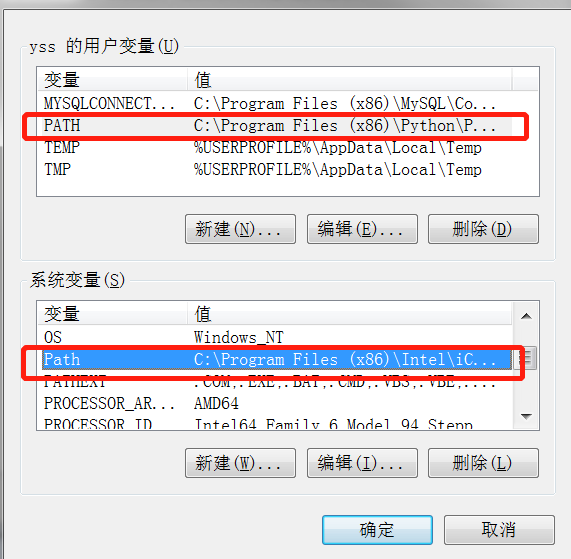
3.新增语言库的环境变量,变量名:TESSDATA_PREFIX,变量值(默认:C:\Program Files (x86)\Tesseract-OCR\tessdata)
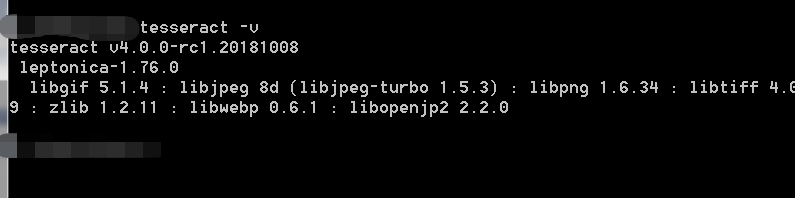
4.测试软件是否可用tesseract -v,能看到版本号就说明安装成功了
5.识别图片的文字(tesseract [in image] [out txt] [lange],如未指定语言,则默认为英文字体库识别)
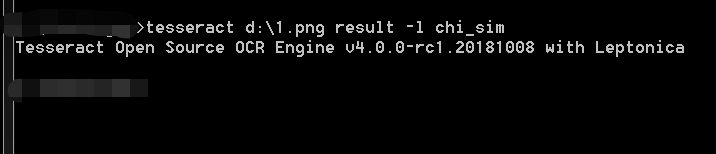
中文字体库识别:tesseract d:\1.png result -l chi_sim,
英文字体库识别:tesseract d:\1.png result,

tesseract 4.0中文字库和安装软件(安装时自带英文字库)
百度网盘:https://pan.baidu.com/s/1TiD2Tdez5JVbAhri8cumLA
密码:5mem
最新文章
- CloudNotes:一个云端个人笔记系统
- spring mvc(注解)上传文件的简单例子
- Android中View绘制流程以及invalidate()等相关方法分析
- java mail api 使用
- android手机两种方式获取IP地址
- SSH乱码和Xshell异常断开解决方法
- HTML中的英文缩写标记、属性
- [React] Higher Order Components (replaces Mixins)
- linux系统下安装tomcat服务器
- 怎么过滤  
- 解析数学表达式 代码解析AST语法树
- SQLServer · 最佳实践 · 透明数据加密TDE在SQLServer的应用
- Hbase Shell 数据操作说明
- unity之UI
- Codeforces 785 D. Anton and School - 2
- jquery-ajax实现文件批量下载
- Linux内核设计(第二周)——操作系统工作原理
- pbr若干概念
- [GO]关于go的waitgroup
- java 把InputStream流写入到文件中