Inception 2.0
文章《Rethinking the Inception Architecture for Computer Vision》
介绍
VGG与GoogLeNet相比更朴素,但计算量大。GoogLeNet中的Inception结构设计的目的是减少计算量和内存。GoogLeNet中只有5百万参数,是AlexNet的1/12,而VGG的参数是AlexNet的3倍。
如果增大Inception类型模型的容量,如果只是double滤波器组的数量,参数量和计算量将会增大4倍;在许多场景中,不允许这样设计。
下面讲解几个增大卷积网络的原则和优化方法。
通用设计原则
1.避免表示瓶颈,尤其是在网络的前面。前向传播网络可以看作一个有向无环图,从输入到输出。一般来说,representation size从输入到输出特征应该缓慢减小。理论上来说,不能仅仅通过维度得到信息,因为它已经丢弃了许多重要特征例如相关结构,维度只能代表信息的粗略估计。
2.高纬度特征在网络局部处理更加容易。在卷积神经网络中增加非线性可以解耦合特征,训练更快
3.空间聚合可以以低维度嵌入进行,这样不会影响representational power.例如,在进行大尺度卷积(3×3)时,在空间聚合前,先对输入进行降维,这样不会带来严重影响。我们猜测原因为:如果输出是为了空间聚合,那么临近单元的强相关性在降维过程中信息损失会很少。考虑到这些信号容易压缩,降维会加速学习过程
4.平衡宽度和深度。增加宽度或深度都会带来性能上的提升,两者同时增加带了并行提升,但是要考虑计算资源的合理分配。
分解大的卷积核
GoogLeNet性能优异很大程度在于使用了降维。降维可以看做卷积网络的因式分解。例如1×1卷积层后跟着3×3卷积层。在网络角度看,激活层的输出是高相关的;因此在聚合前进行降维,可以得到类似的局部表示性能。
这里考虑计算性能,我们探索其他形式的卷积因式分解。因为Inception结构是全卷积,每一个激活值对应的每一个权重,都对应一个乘法运算。因此减小计算量意味着减少参数。所以通过解耦和参数,可以加快训练。利用节省下来的计算和内存增加filter-bank大小,来提升网络性能。
分解为更小的卷积
大的卷积计算量更大,例如filter相同情况下,5×5卷积核比3×3卷积核计算量大25/9=2.78倍。5×5卷积核相比3×3卷积核有广阔“视野”,可以捕捉更多信息,单纯减小卷积核大小会造成信息损失。是否可以通过多层网络代替5×5卷积。把5×5网络看做全卷积,每个输出是卷积核在输入上滑动;可以通过2层3×3全卷积网络替换。如图所示。
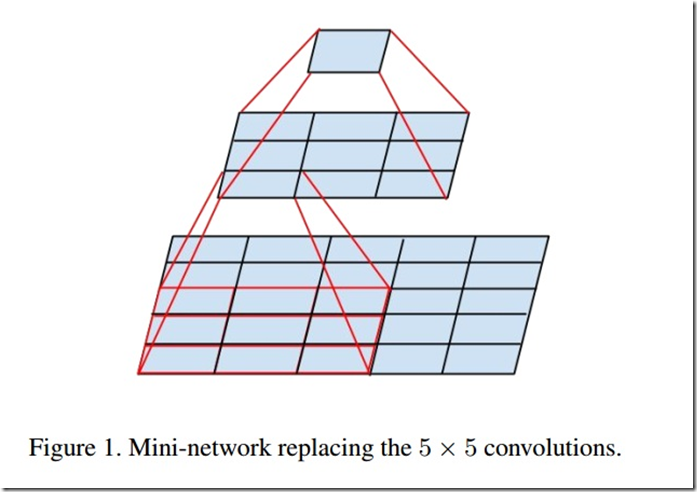
原来的Inception结构:
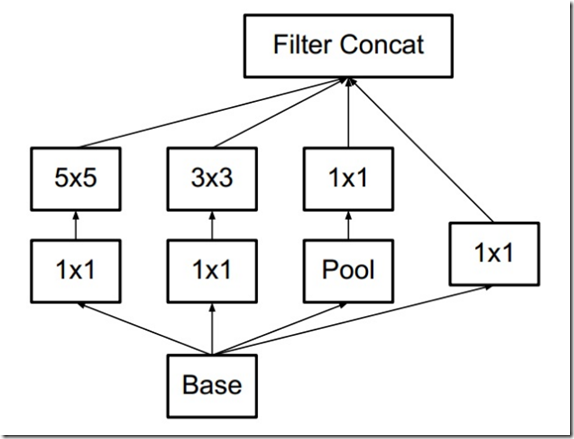
使用2个3x3替换5x5后的Inception结构:
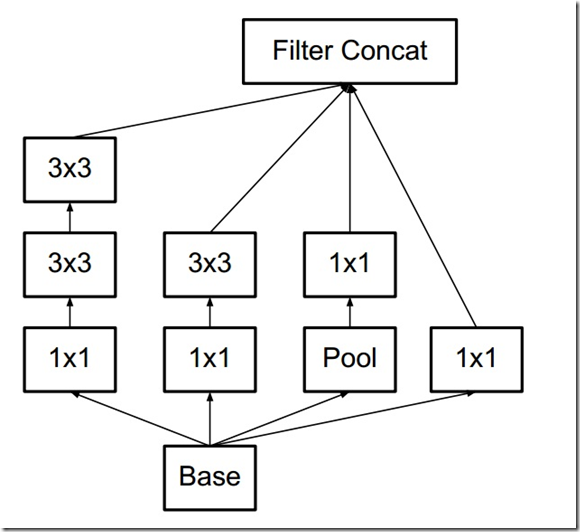
对于分解的卷积层,使用线性激活还是非线性激活,实验表明,非线性激活性能更好。
空间上分解为非对称卷积核
大于3×3的卷积层,都可以分解为连续的3×3的卷积层,那么是不是可以分解为更小的卷积核呢?实际上分解为非对称的更好,例如一个3×1卷积,后跟一个1×3卷积,相当于3×3卷积。如图:
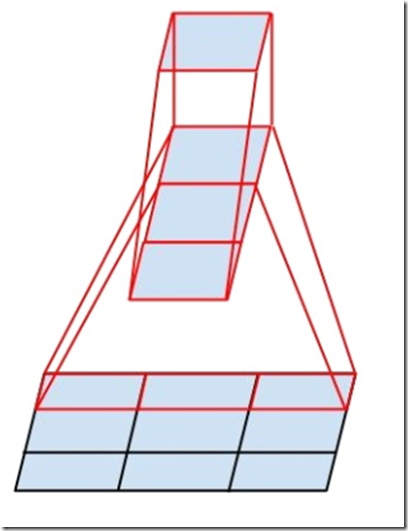
两层结构计算量减少33%。而2×2卷积替代的话计算量仅仅减少11%
理论上,n×n卷积可以通过1×n->n×1卷积代替,随着n增大,能减少更多计算量。在实践中,前几层这样的分解效果并不好;但是在中等网络中,有着不错的性能(m×m的feature map m介于12到20之间)
使用辅助分类器
GoogLeNet引入了附加分类器,其目的是想把有效梯度传递回去,从而加快训练。我们发现辅助分类器扮演着regularizer的角色;因为当辅助分类器使用了batch-normalized或dropout时,主分类器效果会更好。
降低特征图大小
pooling层用来减小feature map大小,为了避免出现representation bottleneck,在使用pooling前常常增加feature map个数。例如k个d×d的feature map,pooling后为k个d/2×d/2.如果想要得到pooling后有2k个feature map,那么在pooling前面的卷积层卷积核个数应该有2k个。前者卷积计算量为2D^2k^2,而后者为2(d/2)^2k^2,是前者四分之一。这样在representation上会有瓶颈。可以使用另一种方法,降低更多计算量:使用2个模块P和C。P表示pooling,C表示卷积;它们stride都为2.如下图所示:
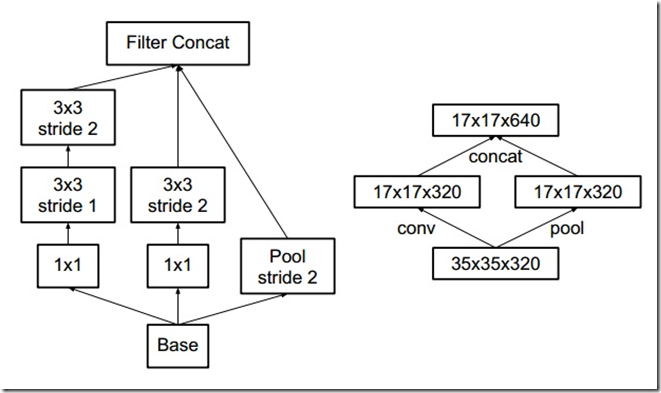
Inception-V2
我们提出Inception-V2模型。结构图下所示:
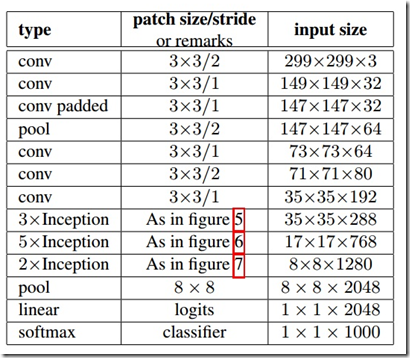
把7×7卷积替代为3个3×3卷积。包含3个inception部分。第一部分35×35×288,使用了2个3×3卷积代替传统的5×5;第二部分减小了feature map,增多filters,为17×17×768,使用了n×1->1×n结构;第三部分增多了filter,使用了卷积池化并行结构。网络有42层,但是计算量只有GoogLeNet的2.5倍。
通过平滑标签正则化模型
输入x,模型计算得到类别为k的概率
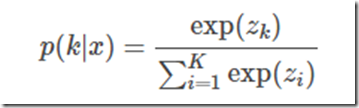
假设真实分布q(k),交叉熵损失函数为
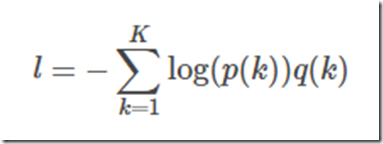
最小化交叉熵等价最大化似然函数。交叉熵函数对逻辑输出求导
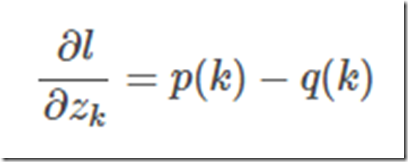

训练方法
batch-size=32,epoch=100。SGD+momentum,momentum=0.9。使用RMSProp,decay=0.9,ϵ=0.1,效果达到最好。lr=0.045,每2个epoch,衰减0.94。梯度最大阈值=2.0.
低分辨率图像的识别
对于低分辨有图像,使用“高分辨率”receptive field。实践中:1、减小前2个卷积层的stride,2、去掉第一个pooling层。
最新文章
- MVC 项目中为什么会有两个web.config
- java序列化---转
- .NET中的注释种类,单行注释、多行注释、文档注释。。。
- Android(java)学习笔记254:ContentProvider使用之内容观察者(观察发出去的短信)
- Java中Calender引用类型
- 懒人小工具:自动生成Model,Insert,Select,Delete以及导出Excel的方法
- 我的BO之强类型
- intel xeon家族介绍
- SDN中的Heavy-Hitter测量文献阅读
- python函数之协程与面向过程编程
- char 与 varchar 区别
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十七之铭文升级版
- [转]WordPress“添加媒体”文件时只显示上传到当前文章的附件图片
- 开窗函数 函数() OVER()
- scala中隐式转换之隐式转换调用类中本不存在的方法
- vm options设置
- Docker之删除container和image
- webpack之react开发前准备
- 【C/C++语法外功】类的静态成员理解
- java的IO操作:字节流与字符流操作
热门文章
- 使用caffe 的 python接口测试数据,选定GPU编号
- javascript - Underscore 与 函数式编程
- Redis_发布订阅(基础)
- oracle数据库性能优化方案精髓整理收集回想
- linux下调试使用的 一些shell命令
- the method getcontextpath() from the type httpservletrequest refers to the missing type string
- IOS MagicRecord 详解 (转载)
- poj1273 Drainage Ditches Dinic最大流
- plsql programming 11 记录类型
- php基本语法之逻辑运算符