python爬取youtube视频 多线程 非中文自动翻译
声明:我写的所有文章都是发在博客园的,我看到其他复制粘贴过去的 连个出处也不写,直接打上自己的水印。。。真是没的说了。
前言:前段时间搞了一些爬视频的项目,代码都写好了,这里写文章那就在来重新分析一遍吧。有不好的地方 莫见怪 : )
环境:python2.7 + win10
开始先说一下,访问youtube需要科学上网,请自行解决,最好是全局代理。
ok,现在开始,首先打开网站观察

网站很干净清爽,这次做的是基于关键字搜索来爬那些相关视频,这样就能很好的分类了,若输入中文搜索,那结果也一般都是国内视频,英文的话 那就是国外的。
这里先来测试中文的 ,输入''搞笑'',搜出来很多视频,也可以根据条件筛选,YouTube视频链接很有规律,都是这种https://www.youtube.com/watch?v=v_OVBHGwOaU,只有后面的 v值不一样,这里就叫id吧。
ok,先从最简单的开始,查看网页源代码看看这些视频链接是否都是在里面,我睁大了我的24k单身狗的眼睛找出来了。。。看了一下,视频信息全在这个<script>标签里面。
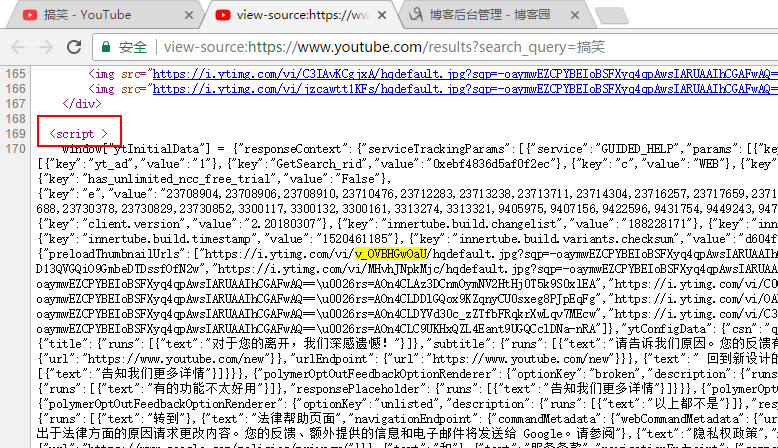
既然如此,那就直接上正则表达式来匹配
"url":"/watch\?v=(.*?)","webPageType"
这样就能匹配出ID来。但是 这好像只有第一页的视频,那第二页的呢,经常观察,此方法不行,视频翻页是基于ajax请求来的,源码里面的信息始终都是第一页的数据,ok 那既然这样,我们来分析ajax请求,我喜欢用谷歌浏览器,打开开发者工具,network,来抓包。
鼠标一直往下拉,会自动请求,是个post请求,一看就是返回的视频信息。
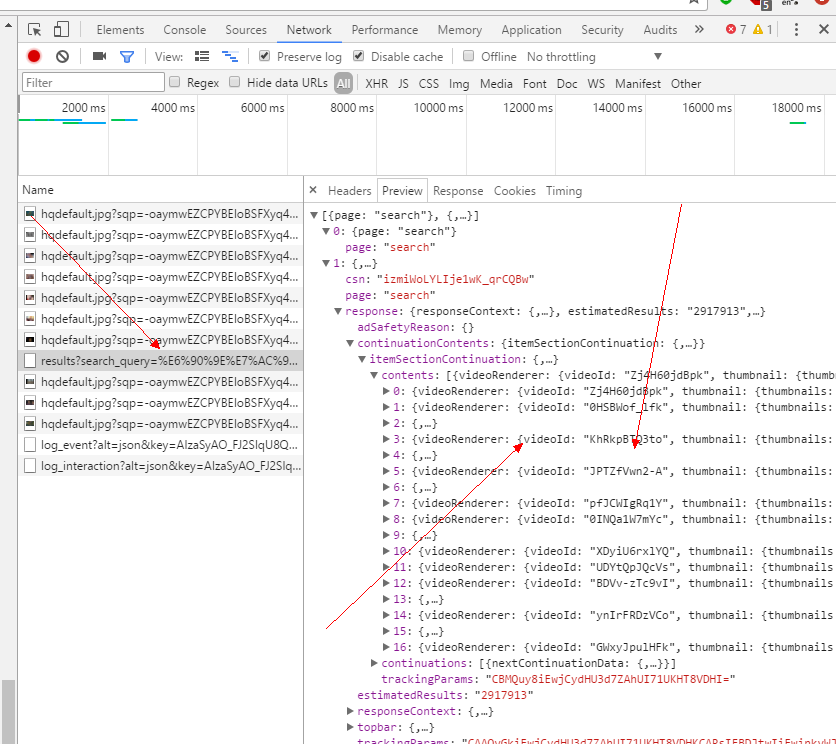
看到这里很高兴,离胜利已经不远了。但,我们先来看下headers 以及发送的post参数,看了之后 就一句 wtf。。。
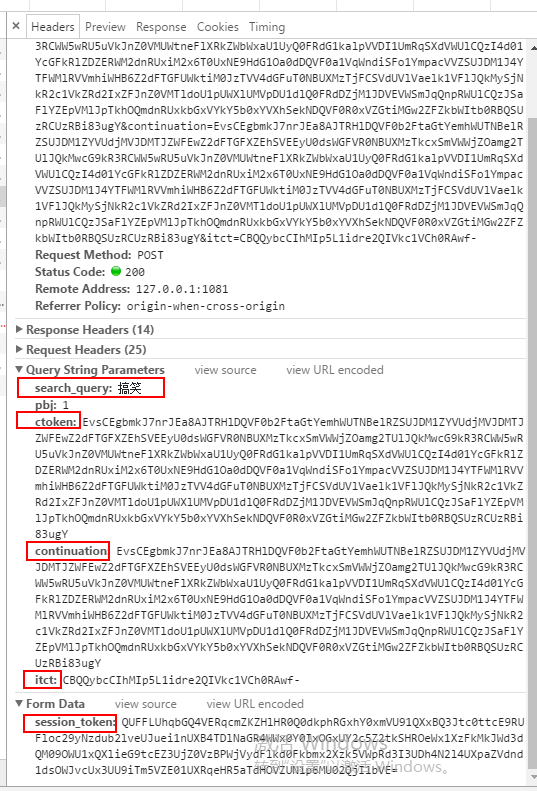
一万个羊驼在奔腾,我把那些加密的参数都标记了,前后端交互,既然是发过去的数据,那肯定已经在前端产生了,至于什么产生的,那就要一步一步分析来了,最后。对 我没有分析出来。。。刚开始挨着挨查看js文件,参数的确是在js里面产生的,但。。。tmd写的太复杂了。。。能力有限,解决不了。难道就这样放弃了吗。肯定不会,不然 各位也不会看到这篇文章了。于是,我灵机一动,在地址栏里面输入&page= 结果,真的返回视频了。。。卧槽 哈哈哈,我当时真是很开心呢。因为前端页面上并没有翻页按钮,没想到竟然还真的可以这样翻页。。。哈哈

既然这都被我猜出来了,那思路就很清晰了,翻页--获得源代码-- 正则匹配 --就可以批量得到视频链接了,然后去重后 在想办法直接通过这个链接去下载。于是,一阵百度 谷歌 找到很多方法,也找到很多api,ok 那就不必要重复造轮子,直接拿来用吧。
有一个开源项目youtube-dl 在github上 是个命令行的应用,安装之后,他是这样的。
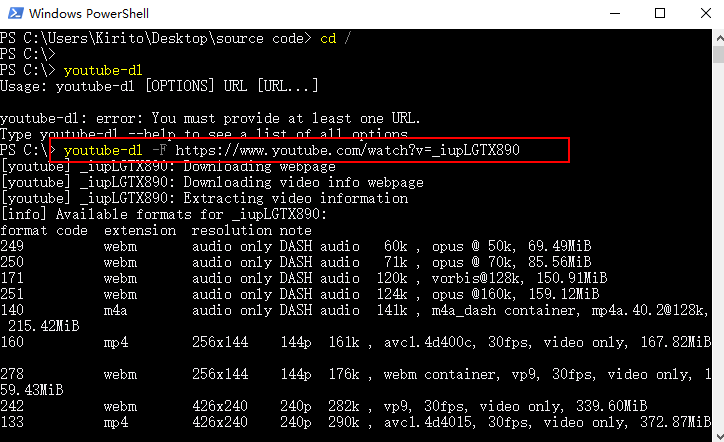
youtube-dl -F https://www.youtube.com/watch?v=_iupLGTX890
这样就能直接分析出所有视频格式的信息,然后通过id 就可以下载下来了。是很好用的一个工具。
在代码里面怎么使用呢,直接调用cmd命令就行了,但是。经过我测试发现呢,批量下载时候,老是有一些视频没有下载完整,所以 我就没用这个方法了,在国外网站上找到一个api 还蛮不错。
怎么找 怎么使用api 我就不用介绍了吧,等会直接贴代码,大家一看便知。
这里在说下,当我输入关键字是英文的话,搜出来的结果全部是英文的,于是 我就下载成功后,保存文件 翻译一下他的标题。翻译成中文的,我去找翻译,最后就用金山词霸了,如果使用官方api的话,好像也有收费。。那不行,我要直接爬页面,于是,我就直接还是爬他的翻译页面,提交英文,返回中文,解析网页,正则匹配出来。就这样 嘿嘿嘿。。
ok。说了这么多了 现在上代码。
# -*-coding:utf-8-*-
# author : Corleone
from bs4 import BeautifulSoup
import lxml
import Queue
import requests
import re,os,sys,random
import threading
import logging
import json,hashlib,urllib
from requests.exceptions import ConnectTimeout,ConnectionError,ReadTimeout,SSLError,MissingSchema,ChunkedEncodingError
import random reload(sys)
sys.setdefaultencoding('gbk') # 日志模块
logger = logging.getLogger("AppName")
formatter = logging.Formatter('%(asctime)s %(levelname)-5s: %(message)s')
console_handler = logging.StreamHandler(sys.stdout)
console_handler.formatter = formatter
logger.addHandler(console_handler)
logger.setLevel(logging.INFO) q = Queue.Queue() # url队列
page_q = Queue.Queue() # 页面 def downlaod(q,x,path):
urlhash = "https://weibomiaopai.com/"
try:
html = requests.get(urlhash).text
except SSLError:
logger.info(u"网络不稳定 正在重试")
html = requests.get(urlhash).text
reg = re.compile(r'var hash="(.*?)"', re.S)
result = reg.findall(html)
hash_v = result[0]
while True:
data = q.get()
url, name = data[0], data[1].strip().replace("|", "")
file = os.path.join(path, '%s' + ".mp4") % name
api = "https://steakovercooked.com/api/video/?cached&hash=" + hash_v + "&video=" + url
api2 = "https://helloacm.com/api/video/?cached&hash=" + hash_v + "&video=" + url
try:
res = requests.get(api)
result = json.loads(res.text)
except (ValueError,SSLError):
try:
res = requests.get(api2)
result = json.loads(res.text)
except (ValueError,SSLError):
q.task_done()
return False
vurl = result['url']
logger.info(u"正在下载:%s" %name)
try:
r = requests.get(vurl)
except SSLError:
r = requests.get(vurl)
except MissingSchema:
q.task_done()
continue
try:
with open(file,'wb') as f:
f.write(r.content)
except IOError:
name = u'好开心么么哒 %s' % random.randint(1,9999)
file = os.path.join(path, '%s' + ".mp4") % name
with open(file,'wb') as f:
f.write(r.content)
logger.info(u"下载完成:%s" %name)
q.task_done() def get_page(keyword,page_q):
while True:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0'
}
page = page_q.get()
url = "https://www.youtube.com/results?sp=EgIIAg%253D%253D&search_query=" + keyword + "&page=" + str(page)
try:
html = requests.get(url, headers=headers).text
except (ConnectTimeout,ConnectionError):
print u"不能访问youtube 检查是否已翻墙"
os._exit(0)
reg = re.compile(r'"url":"/watch\?v=(.*?)","webPageType"', re.S)
result = reg.findall(html)
logger.info(u"第 %s 页" % page)
for x in result:
vurl = "https://www.youtube.com/watch?v=" + x
try:
res = requests.get(vurl).text
except (ConnectionError,ChunkedEncodingError):
logger.info(u"网络不稳定 正在重试")
try:
res = requests.get(vurl).text
except SSLError:
continue
reg2 = re.compile(r"<title>(.*?)YouTube",re.S)
name = reg2.findall(res)[0].replace("-","")
if u'\u4e00' <= keyword <= u'\u9fff':
q.put([vurl, name])
else:
# 调用金山词霸
logger.info(u"正在翻译")
url_js = "http://www.iciba.com/" + name
html2 = requests.get(url_js).text
soup = BeautifulSoup(html2, "lxml")
try:
res2 = soup.select('.clearfix')[0].get_text()
title = res2.split("\n")[2]
except IndexError:
title = u'好开心么么哒 %s' % random.randint(1, 9999)
q.put([vurl, title])
page_q.task_done() def main():
# 使用帮助
keyword = raw_input(u"请输入关键字:").decode("gbk")
threads = int(raw_input(u"请输入线程数量(建议1-10): "))
# 判断目录
path = 'D:\youtube\%s' % keyword
if os.path.exists(path) == False:
os.makedirs(path)
# 解析网页
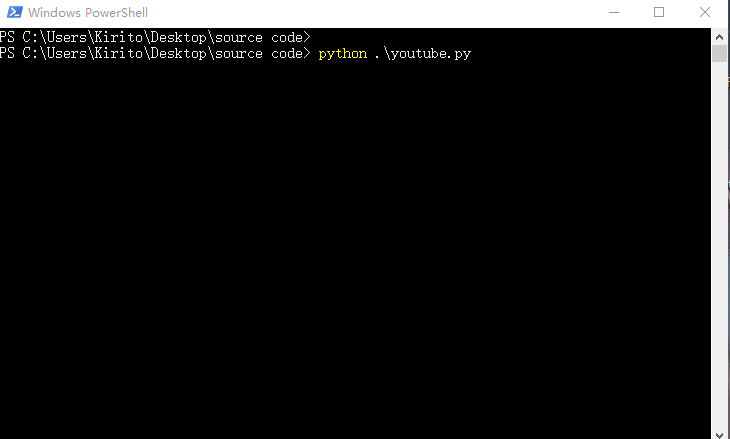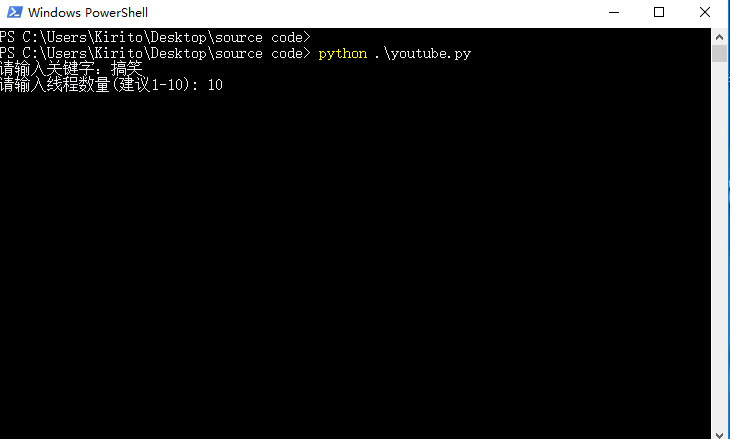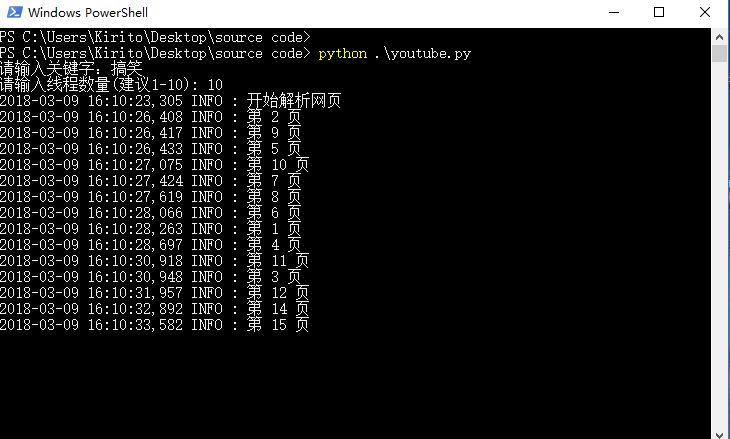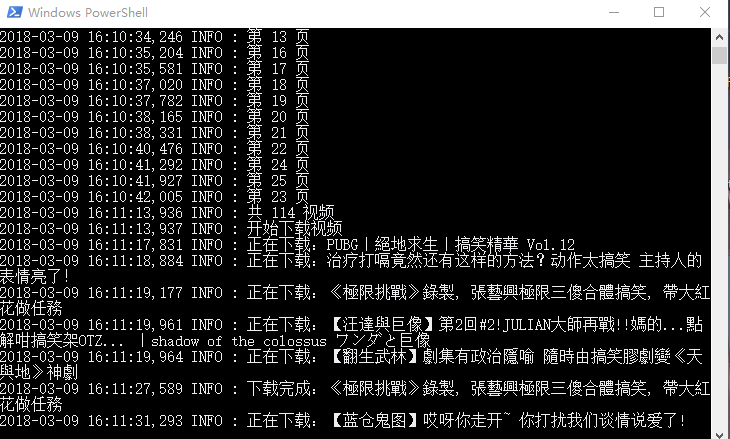
logger.info(u"开始解析网页")
for page in range(1,26):
page_q.put(page)
for y in range(threads):
t = threading.Thread(target=get_page,args=(keyword,page_q))
t.setDaemon(True)
t.start()
page_q.join()
logger.info(u"共 %s 视频" % q.qsize())
# 多线程下载
logger.info(u"开始下载视频")
for x in range(threads):
t = threading.Thread(target=downlaod,args=(q,x,path))
t.setDaemon(True)
t.start()
q.join()
logger.info(u"全部视频下载完成!") main()
在这里在说一下,我当时用的win10 所有编码全是gbk的,若在linux上面跑,请自行修改。也是多线程下载的,默认下载目录 d:\youtube 然后会根据关键字在创建子目录,视频都放在里面。对了 还有我代码里面用筛选了,只爬1天之内更新的。每天爬一遍即可。
来测试一下。下载的时候 就是考验网速的时候了,网不好了,可能会出现一些我没捕获的异常。。。可能是我找的fq服务器网速还行。。
ok 到这里整篇文章就结束了,写文章都快弄了一个小时了。。不容易呢 :-
我的github地址 https://github.com/binglansky/spider
嘿嘿,欢迎一块学习交流 :) ~~~
最新文章
- nova instance出错:"message": "Proxy error: 502 Read from server failed
- 鱼搜_鱼搜官网_鱼搜搜索_http://www.7yusou.com
- css3制作旋转立方体相册
- mysql 总结二(自定义存储过程)
- QTdebug时没有调试引擎
- Binary Search Tree In-Order Traversal Iterative Solution
- C#跳出循环的几种方法的区别
- In Java, what is the default location for newly created files?
- Mysql中存储方式的区别
- HDU - 1407 打表
- LeetCode(54)-Longest Common Prefix
- python字典转化成json格式。JSONEncoder和JSONDecoder两个类来实现Json字符串和dict类型数据的互相转换
- Win7 VS2017 NASM编译FFMPEG(2018.12.22)
- mysql处理重复数据
- Vijos P1459 车展 (treap 任意区间中位数)
- 在单文件组件中,引入安装模块里的css的2种方式:script中引入、style中引入
- CF1088F Ehab and a weird weight formula 贪心 倍增
- DoBox 下载
- 初探UE4中的Profiling【转】
- mui 选项卡与header文字同步