2 数据分析之Numpy模块(1)
Numpy
Numpy(Numerical Python的简称)是高性能科学计算和数据分析的基础包。它是我们课程所介绍的其他高级工具的构建基础。
其部分功能如下:
- ndarray, 一个具有复杂广播能力的快速且节省空间的多维数组。
- 对于整组数据进行快速的运算,无需编写循环。
- 用于读写磁盘数据的工具以及用于操作内容映射文件的工具。
- 用于集成由C, C++等语言编写的代码的工具。
Numpy本身并没有提供那么多高级的数据分析功能,理解Numpy数组以及面向数组的计算将有助于我们更加高效的使用pandas之类的工具。
创建数组 ndarray概述
Numpy最重要的一个特点就是其N纬数组对象(即ndarray),该对象是一个快速而灵活的大数据集容器。你可以利用这种数组对整块的数据执行一些数学运算。
ndarray是一个通用的同构数据多维容器,其中的所有元素必须是相同类型的。每个数组都有一个shape(表示各维度大小的元组)和一个dtype(表示数组数据类型的对象):
我们将会介绍Numpy数组的基本用法,虽然说大多数数据分析工作不需要深入理解Numpy,但精通面向数组的编程和思维方式是成为Python科学计算牛人的一大关键步骤。
注意: 我们将依照标准的Numpy约定,即总是使用import numpy as np. 当然你也可以为了不写np,而直接在代码中使用from numpy import *, 但是建议你最好还是不要养成这样的坏习惯。
在界面上的命令行操作
esc切换到命令模式,
输入dd 删除当前单元格
a在当前单元格前面增加一个单元格
b在当前单元格后面增加一个单元格
创建ndarray
创建数组最简单的方法就是使用array函数。它接收一切序列型的对象(包括其他数组),然后产生一个新的含有传入数据的Numpy数组。
array函数创建数组
import numpy as np
创建一维数组
ndarray1 = np.array([1, 2, 3, 4, 5]) ndarray1

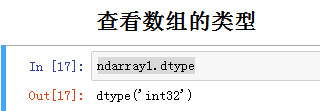
查看数组的类型
ndarray1.dtype
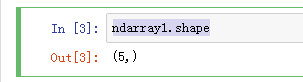
查看数组的shape(看维数和数组的长度,一维的只显示数组的长度)
ndarray1.shape
创建二维数组
这里要用一个大列表,把里面的数组包起来
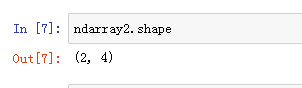
ndarray2 = np.array([[1, 2, 3, 4], [2, 4, 6, 8]]) ndarray2

查看数组的shape
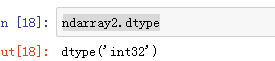
查看数组的类型
ndarray2.dtype
创建一个字符数组
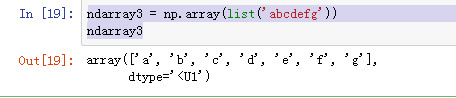
ndarray3 = np.array(list('abcdefg'))
ndarray3
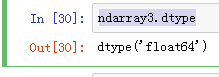
查看数组的类型
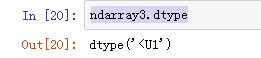
ndarray3.dtype
查看数组的shape
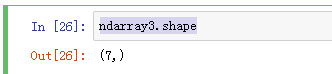
ndarray3.shape
zeros和zeros_like创建数组
它的类型是Float
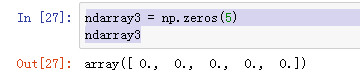
用于创建数组,数组元素默认值是0. 注意:zeros_linke函数只是根据传入的ndarray数组的shape来创建所有元素为0的数组,并不是拷贝源数组中的数据.
ndarray3 = np.zeros(5) ndarray3
查看类型
ndarray3.dtype
zeros_like
ndarray4 = np.zeros((2, 2)) ndarray4[0][0] = 100 ndarray4

like版本的函数表示按照参数的shape创建数组
ndarray5 = np.zeros_like(ndarray4) ndarray5
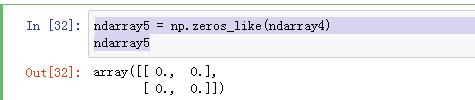
值并不和 ndarray4 的值一样,只是和它的维度和长度有关
ones和ones_like创建数组
用于创建所有元素都为1的数组.ones_like用法同zeros_like用法.
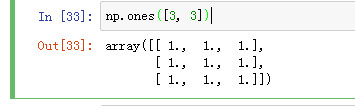
ndarray6 = np.ones([3, 3])
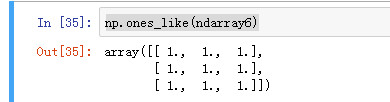
np.ones_like(ndarray6)
empty和empty_like创建数组
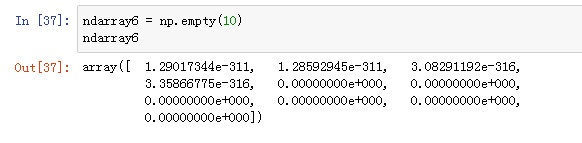
用于创建空数组,空数据中的值并不为0,而是未初始化的随机值(垃圾值)
ndarray6 = np.ones([3, 3])
ndarray6
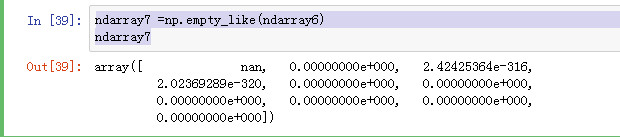
empty_like的用法同上
ndarray7 =np.empty_like(ndarray6) ndarray7
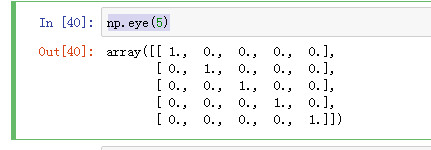
eys创建对角矩阵数组
该函数用于创建一个N*N的矩阵,对角线为1,其余为0.
np.eye(5)
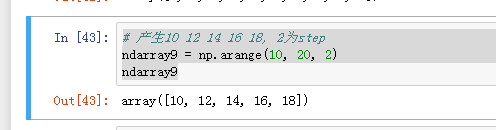
arange创建数组
arange函数是python内置函数range函数的数组版本.
#产生0-9共10个元素 ndarray8 = np.arange(10) ndarray8

# 产生10 12 14 16 18, 2为step ndarray9 = np.arange(10, 20, 2) ndarray9
2.2 数据类型
我们可以通过ndarray的dtype来打印数组中元素的类型. ndarray常见的数据类型如下:
ul 表示无符号正数,没有负数
| 类型 | 类型代码 | 说明 |
|---|---|---|
| int8、uint8 | i1、u1 | 有符号和无符号的8位(1个字节长度)整型 |
| int16、uint16 | i2、u2 | 有符号和无符号的16位(2个字节长度)整型 |
| int32、uint32 | i4、u4 | 有符号和无符号的32位(4个字节长度)整型 |
| float16 | f2 | 半精度浮点数 |
| float32 | f4或f | 标准单精度浮点数 |
| float64 | f8或d | 双精度浮点数 |
| bool | ? | 布尔类型 |
| object | O | Python对象类型 |
| unicode_ | U | 固定长度的unicode类型,跟字符串定义方式一样 |
import numpy as np
ndarray1 = np.array([1, 2, 3, 4])
ndarray2 = np.array(list('abcdefg'))
ndarray3 = np.array([True, False, False, True])
class Person(object):
pass
ndarray4 = np.array([Person(), Person(), Person()])
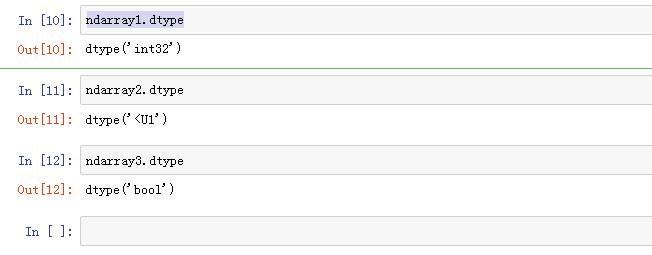
依次查看类型
ndarray1.dtype
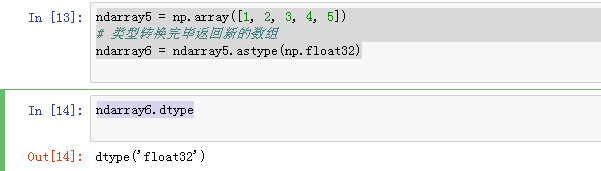
使用astype函数转换数组类型
ndarray5 = np.array([1, 2, 3, 4, 5]) # 类型转换完毕返回新的数组 ndarray6 = ndarray5.astype(np.float32)
ndarray6.dtype
ndarray7 = np.array([1.1, 2.2, 3.3, 4.4]) # 如果浮点数转换为整数,则小数部分将会被截断 ndarray8 = ndarray7.astype(np.int32)ndarray8

ndarray9 = np.array(['10', '20', '30', '40']) # 如果某些字符串数组表示的全是数字,也可以用astype将其转换为数值类型 ndarray10 = ndarray9.astype(np.int32) ndarray10

数组运算
快速切换到Markdown的快捷键 Esc +M
不需要循环即可对数据进行批量运算,叫做矢量化运算. 不同形状的数组之间的算数运算,叫做广播.
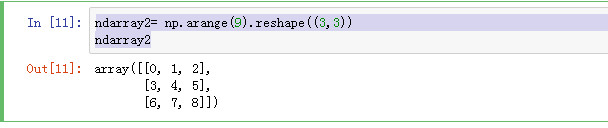
reshape()函数可以重新设置数组的shape
ndarray2= np.arange(9).reshape((3,3)) ndarray2
数组和数字之间的运算(广播的形式挨个遍历)
ndarray3 = np.arange(10) ndarray3+100

ndarray3 * 10

ndarray2+100

数组还可以进行布尔运算
ndarray1 = np.arange(10) ndarray1>2

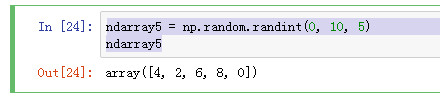
1 np.random.randint(0, 10, 5) 随机产生5个0-10的元素
np.random.randint(0, 10, 5)

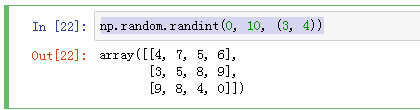
2 np.random.randint(0, 10, (3, 4)) 随机产生3行4列的元素
np.random.randint(0, 10, (3, 4))
数组和数组运算
ndarray4 = np.random.randint(0, 10, 5) ndarray4

ndarray5 = np.random.randint(0, 10, 5) ndarray5
ndarray4 + ndarray5

ndarray6 = np.random.randint(0, 10, (3, 4)) ndarray6

ndarray7 = np.random.randint(0, 10, (3, 4)) ndarray7

ndarray6+ndarray7

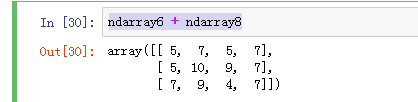
ndarray8 = np.random.randint(0, 10, 4) ndarray8

ndarray6 + ndarray8
一维数组和多维数组进行想加是每一行,每一行进行广播想加
数组索引和切片
Numpy数组的索引是一个内容丰富的主题,因为选取数据子集或单个元素的方式有很多。一维数组很简单。从表面上看,它们和Python列表的功能差不多。
数组索引和切片基本用法
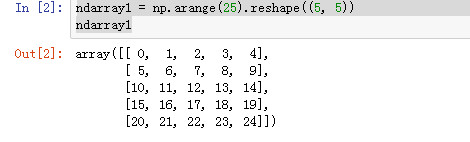
ndarray1 = np.arange(25).reshape((5, 5)) ndarray1
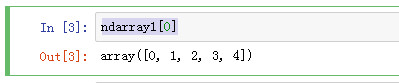
获取二维数组的第一个元素(数组)
ndarray1[0]
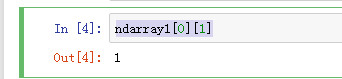
获取二维数组第一个元素的第二个元素
ndarray1[0][1]
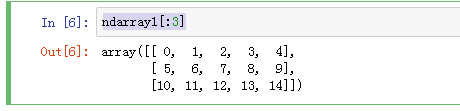
获取二维数组的前三个元素(数组)
ndarray1[:3]
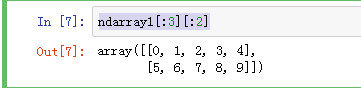
获取二维数组的前三个元素的前两个元素
ndarray1[:3][:2]
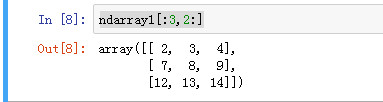
获取二维数组的前三个元素,每个元素从2开始切片
ndarray1[:3,2:]
注意:
- 当把一个数字值赋值给一个切片时,该值会自动传播到整个选区。跟列表的区别在于,数组切片是原始数组的视图,这意味着数据不会被赋值,视图上的任何修改都会直接反应到源数组上.
- 大家可能对此感到不解,由于Numpy被设计的目的是处理大数据,如果Numpy将数据复制来复制去的话会产生何等的性能和内存问题.
- 如果要得到一个切片副本的话,必须显式进行复制操作.
数组花式索引
ndarray2 = np.empty((8,8))
for val in range(8):
ndarray2[val]= np.arange(val,val+8)
ndarray2
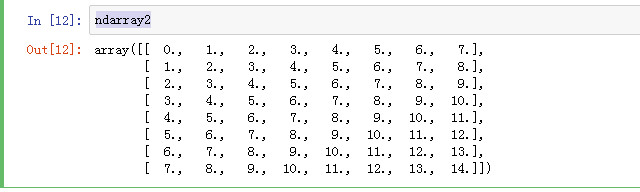
获取指定下标元素的集合
ndarray2[[1,3,5]]
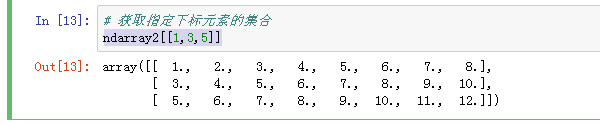
获取筛选后的1,2元素
ndarray2[[1,3,5]][[1,2]]

获取筛选后每个元素的第0个元素
ndarray2[[1,3,5],0]
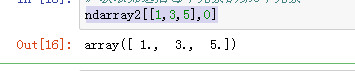
获取筛选后每个元素,从下标0开始切片到2
ndarray2[[1,3,5],:2]
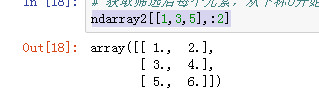
获取每个元素的指定的元素
ndarray2[[1,3,5],[0,1,2]]
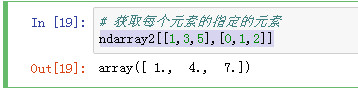
布尔型索引
# 获取一个随机3行4列的数组 country_data = np.random.randint(1000,10000,(4,3)) country_data

添加行索引
country_index = np.array(['中国','美国','德国','法国'])
country_index

country_index == '美国'

# 也就是一个数组里面又嵌套了一个数组 country_data[country_index == '美国']

添加列索引
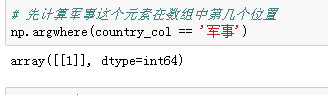
country_col=np.array(['经济','军事','人口'])
# 先计算军事这个元素在数组中第几个位置 np.argwhere(country_col == '军事')
取出这个位置
np.argwhere(country_col == '军事')[0][0]

获取法国的人口
country_data[country_index == '法国'][0][np.argwhere(country_col == '人口')[0][0]]

查看元素在数组中的第几个位置
np.argwhere(条件)
np.argwhere(country_data == 8377)

布尔类型数组跟切片、整数混合使用
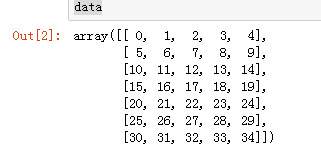
names = np.array(['aaa', 'bbb', 'ccc', 'ddd', 'eee', 'fff', 'ggg']) data = np.arange(35).reshape((7, 5)) data
ret1 = data[names == 'ccc'] ret1

布尔类型数组和整数混合使用
ret2= data[names == 'ccc', 2] ret2

布尔类型数组和切片混合使用
ret3= data[names == 'ccc', 1:] ret3

使用不等于!=,使用(~)对条件否定
ret1 = data[names != 'ccc'] ret1

ret2 = data[~(names == 'ccc')] ret2

ret3 = data[~(names > 'ccc')] ret3

使用&(和)、|(或)组合多个布尔条件
ret1 = data[(names == 'aaa') | (names == 'ccc')] ret1
ret2 = data[(names > 'ddd') | (names == 'aaa')] ret2
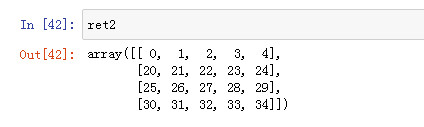
ret3 = data[(names < 'eee') & (names > 'bbb') ] ret3

使用布尔类型数组设置值是一种经常用到的手段
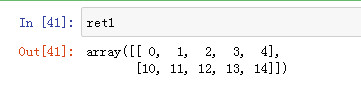
ndarray1 = np.arange(5) ndarray2 = np.arange(16).reshape((4, 4)) names = np.array(['aaa', 'bbb', 'ccc', 'ddd'])
将数组ndarray1中所有大于2的元素设置成666
ndarray1[ndarray1 > 2] = 666 ndarray1

将ndarray2的aaa这一行所有的元素设置为0
ndarray2[names == 'aaa'] = 0 ndarray2
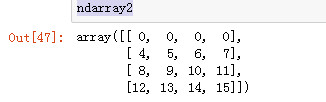
将ndarray2的bbb这一行2位置往后所有的元素设置为1
ndarray2[names == 'bbb', 2:] = 1 ndarray2

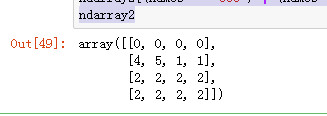
将ndarray2的ccc ddd这2行所有的元素设置为2
ndarray2[(names == 'ccc') | (names == 'ddd')] = 2 ndarray2
zip 函数的使用
zip([列表1],[列表2])用法,拿列表中1的值,在拿列表2中的值,进行一一对应
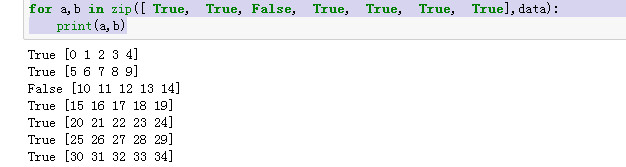
for a,b in zip([ True, True, False, True, True, True, True],data):
print(a,b)
# 只取为真的值
for a,b in zip([ True, True, False, True, True, True, True],data):
if a:
print(a,b)
np.where用法
np.where()函数的使用-----------> np.where(条件,满足条件是什么值,不满足条件是什么值)
ndarray1 = np.random.randint(-10, 10, (5, 5)) ndarray1

把数组中小于0的值改为100
np.where(ndarray1<0,100,ndarray1)

将数组中大于-3小于3的值改为100
np.where(ndarray1>-3,np.where(ndarray1<3,100,ndarray1),ndarray1)

最新文章
- LeetCode 7. Reverse Integer
- 设计模式(六):控制台中的“命令模式”(Command Pattern)
- github page+jekyll搭博客初体验
- 浏览器缓存相关的Http头介绍:Expires,Cache-Control,Last-Modified,ETag
- js弹出提示信息,然后跳转到另一页面
- 【caffe-windows】 caffe-master 之 cifar10 超详细
- hdu 1686 Oulipo KMP匹配次数统计
- Android学习笔记一
- java集合框架复习(一)
- Cordova 3.0 Plugin 安装 及"git" command line tool is not installed
- 在Windows Server 2012服务器上安装可靠多播协议
- Rendering Transparent 3D Surfaces in WPF with C#(转载)
- cocos2d-x 背景音乐播放
- 实战:mysql版本号升级
- Cocos2d-x中的CC_CALLBACK_X详解
- poi jsp xls
- 图片懒加载、selenium和PhantomJS
- parrot os 安装后更改更新源
- 将一个C++的AES加密算法(有向量的)翻译成C#
- 读书笔记(chapter7)
热门文章
- Identity Server 4 中文文档(v1.0.0)
- Java虚拟机学习笔记(一)
- Yii2基本概念之——配置(Configurations)
- vue 如何点击按钮返回上一页
- 小tips:node起一个简单服务,打开本地项目或文件浏览
- 后端开发者的Vue学习之路(一)
- 无依赖简单易用的Dynamics 365实体记录数计数器并能计算出FetchXml返回的记录数
- Django的urls.py加载静态资源图片,TypeError: view must be a callable or a list/tuple in the case of include().
- 动态BGP和静态BGP的含义与区别
- 使用OCLint和Sonar对iOS代码分析和质量管理