hbase的常用的shell命令&hbase的DDL操作&hbase的DML操作
前言
笔者在分类中的hbase栏目之前已经分享了hbase的安装以及一些常用的shell命令的使用,这里不仅仅重新复习一下shell命令,还会介绍hbase的DDL以及DML的相关操作。
hbase的shell操作
启动hbase shell
在hbase的安装目录的bin目录下面启动我们的hbase,执行命令:hbase shell,执行效果以>结束,如下执行效果:
[root@mini1 bin]# ./hbase shell SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding .jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding .jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] HBase Shell; enter 'help<RETURN>' for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version , r930b9a55528fe45d8edce7af42fef2d35e77677a, Thu Apr :: PDT hbase(main)::> hbase shell
执行hbase shell的帮助文档
输入help并按Enter键,可以显示hbase Shell的基本使用信息,和我们接下来会列举的一些命令类似。需要注意的是,表名,行,列都必须包含在引号内。
执行效果:
hbase(main)::> help
HBase Shell, version , r930b9a55528fe45d8edce7af42fef2d35e77677a, Thu Apr :: PDT
Type 'help "COMMAND"', (e.g. 'help "get"' -- the quotes are necessary) for help on a specific command.
Commands are grouped. Type 'help "COMMAND_GROUP"', (e.g. 'help "general"') for help on a command group.
COMMAND GROUPS:
Group name: general
Commands: status, table_help, version, whoami
Group name: ddl
Commands: alter, alter_async, alter_status, create, describe, disable, disable_all, drop, drop_all, enable, enable_all, exists, get_table, is_disabled, is_enabled, list, locate_region, show_filters
Group name: namespace
Commands: alter_namespace, create_namespace, describe_namespace, drop_namespace, list_namespace, list_namespace_tables
Group name: dml
Commands: append, count, delete, deleteall, get, get_counter, get_splits, incr, put, scan, truncate, truncate_preserve
Group name: tools
Commands: assign, balance_switch, balancer, balancer_enabled, catalogjanitor_enabled, catalogjanitor_run, catalogjanitor_switch, close_region, compact, compact_rs, flush, major_compact, merge_region, move, normalize, normalizer_enabled, normalizer_switch, split, splitormerge_enabled, splitormerge_switch, trace, unassign, wal_roll, zk_dump
Group name: replication
Commands: add_peer, append_peer_tableCFs, disable_peer, disable_table_replication, enable_peer, enable_table_replication, get_peer_config, list_peer_configs, list_peers, list_replicated_tables, remove_peer, remove_peer_tableCFs, set_peer_tableCFs, show_peer_tableCFs
Group name: snapshots
Commands: clone_snapshot, delete_all_snapshot, delete_snapshot, delete_table_snapshots, list_snapshots, list_table_snapshots, restore_snapshot, snapshot
Group name: configuration
Commands: update_all_config, update_config
Group name: quotas
Commands: list_quotas, set_quota
Group name: security
Commands: grant, list_security_capabilities, revoke, user_permission
Group name: procedures
Commands: abort_procedure, list_procedures
Group name: visibility labels
Commands: add_labels, clear_auths, get_auths, list_labels, set_auths, set_visibility
SHELL USAGE:
Quote all names in HBase Shell such as table and column names. Commas delimit
command parameters. Type <RETURN> after entering a command to run it.
Dictionaries of configuration used in the creation and alteration of tables are
Ruby Hashes. They look like this:
{'key1' => 'value1', 'key2' => 'value2', ...}
and are opened and closed with curley-braces. Key/values are delimited by the
'=>' character combination. Usually keys are predefined constants such as
NAME, VERSIONS, COMPRESSION, etc. Constants do not need to be quoted. Type
'Object.constants' to see a (messy) list of all constants in the environment.
If you are using binary keys or values and need to enter them in the shell, use
double-quote'd hexadecimal representation. For example:
hbase> get 't1', "key\x03\x3f\xcd"
hbase> get 't1', "key\003\023\011"
hbase> put 't1', "test\xef\xff", 'f1:', "\x01\x33\x40"
The HBase shell is the (J)Ruby IRB with the above HBase-specific commands added.
For more on the HBase Shell, see http://hbase.apache.org/book.html
退出hbase shell
使用quit命令,退出hbase Shell 并且断开和集群的连接,但此时hbase仍然在后台运行。
使用status命令查看hbase现在的状态
hbase(main)::> status active master, backup masters, servers, dead, 1.0000 average load
从上面可以看出一个master在运行,并且下面有两个服务器...没有备份的master,没有死亡的服务。
使用version命令查看hbase的相关的版本
hbase(main)::> version , r930b9a55528fe45d8edce7af42fef2d35e77677a, Thu Apr :: PDT
从上面可以看出版本是1.3.1版本的。
table_help
此命令将引导如何使用表引用的命令。下面给出的是使用这个命令的语法:
hbase(main)::> table_help Help for table-reference commands. You can either create a table via 'create' and then manipulate the table via commands like 'put', 'get', etc. See the standard help information for how to use each of these commands. However, as of 0.96, you can also get a reference to a table, on which you can invoke commands. For instance, you can get create a table and keep around a reference to it via: hbase> t = create 't', 'cf' Or, if you have already created the table, you can get a reference to it: hbase> t = get_table 't' You can do things like call 'put' on the table: hbase> t.put 'r', 'cf:q', 'v' which puts a row 'r' with column family 'cf', qualifier 'q' and value 'v' into table t. To read the data out, you can scan the table: hbase> t.scan which will read all the rows in table 't'. Essentially, any command that takes a table name can also be done via table reference. Other commands include things like: get, delete, deleteall, get_all_columns, get_counter, count, incr. These functions, along with the standard JRuby object methods are also available via tab completion. For more information on how to use each of these commands, you can also just type: hbase> t.help 'scan' which will output more information on how to use that command. You can also do general admin actions directly on a table; things like enable, disable, flush and drop just by typing: hbase> t.enable hbase> t.flush hbase> t.disable hbase> t.drop Note that after dropping a table, your reference to it becomes useless and further usage is undefined (and not recommended).
whoami
该命令返回hbase用户详细信息。如果执行这个命令,返回当前hbase用户,如下所示:
hbase(main)::> whoami root (auth:SIMPLE) groups: root
从上面我们看出操作者是root用户,该用户属于root组。
hbase的DDL相关的操作
使用hbase创建表
创建表
可以使用命令创建一个表,在这里必须指定表名和列族名。在hbase shell中创建表的语法如下所示:
create '<table name>','<column family>'
例子:
下面给出的是一个表名为emp的样本模式。它有两个列族:“personal data”和“professional data”:
hbase(main)::> create 'emp','personal data','professional data' row(s) in 1.2570 seconds => Hbase::Table - emp
验证创建
可以验证是否已经创建,使用 list 命令如下所示。在这里,可以看到创建的emp表:
hbase(main)::> list TABLE emp row(s) in 0.0480 seconds => ["emp"]
从上面我们可以很直观地看出我们已经创建了相关的emp表格了。
使用hbase禁用表
禁用表
要删除表或改变其设置,首先需要使用 disable 命令关闭表。使用 enable 命令,可以重新启用它。
禁用我们上面创建的emp表:
hbase(main)::> disable 'emp' row(s) in 2.3300 seconds
验证禁用
禁用表之后,仍然可以通过 list 和exists命令查看到。但是无法扫描到它存在,它会给下面的错误。
下面以exists命令为例:
hbase(main)::> exists 'emp' Table emp does exist row(s) in 0.3610 seconds
从第二行我们可以很直观地看出我们的emp表是存在的。
hbase(main)::> scan 'emp'
ROW COLUMN+CELL
ERROR: emp is disabled.
Here is some help for this command:
Scan a table; pass table name and optionally a dictionary of scanner
specifications. Scanner specifications may include one or more of:
TIMERANGE, FILTER, LIMIT, STARTROW, STOPROW, ROWPREFIXFILTER, TIMESTAMP,
MAXLENGTH or COLUMNS, CACHE or RAW, VERSIONS, ALL_METRICS or METRICS
If no columns are specified, all columns will be scanned.
To scan all members of a column family, leave the qualifier empty as in
'col_family'.
The filter can be specified in two ways:
. Using a filterString - more information on this is available in the
Filter Language document attached to the HBASE- JIRA
. Using the entire package name of the filter.
If you wish to see metrics regarding the execution of the scan, the
ALL_METRICS boolean should be set to true. Alternatively, if you would
prefer to see only a subset of the metrics, the METRICS array can be
defined to include the names of only the metrics you care about.
Some examples:
hbase> scan 'hbase:meta'
hbase> scan 'hbase:meta', {COLUMNS => 'info:regioninfo'}
hbase> scan , STARTROW => 'xyz'}
hbase> scan , STARTROW => 'xyz'}
hbase> scan , ]}
hbase> scan 't1', {REVERSED => true}
hbase> scan 't1', {ALL_METRICS => true}
hbase> scan 't1', {METRICS => ['RPC_RETRIES', 'ROWS_FILTERED']}
hbase> scan 't1', {ROWPREFIXFILTER => 'row2', FILTER => "
(QualifierFilter (>=, , ))"}
hbase> scan 't1', {FILTER =>
org.apache.hadoop.hbase.filter.ColumnPaginationFilter.new(, )}
hbase> scan 't1', {CONSISTENCY => 'TIMELINE'}
For setting the Operation Attributes
hbase> scan 't1', { COLUMNS => ['c1', 'c2'], ATTRIBUTES => {'mykey' => 'myvalue'}}
hbase> scan 't1', { COLUMNS => ['c1', 'c2'], AUTHORIZATIONS => ['PRIVATE','SECRET']}
For experts, there is an additional option -- CACHE_BLOCKS -- which
switches block caching for the scanner on (true) or off (false). By
default it is enabled. Examples:
hbase> scan 't1', {COLUMNS => ['c1', 'c2'], CACHE_BLOCKS => false}
Also for experts, there is an advanced option -- RAW -- which instructs the
scanner to return all cells (including delete markers and uncollected deleted
cells). This option cannot be combined with requesting specific COLUMNS.
Disabled by default. Example:
hbase> scan }
Besides the default 'toStringBinary' format, 'scan' supports custom formatting
by column. A user can define a FORMATTER by adding it to the column name in
the scan specification. The FORMATTER can be stipulated:
. either as a org.apache.hadoop.hbase.util.Bytes method name (e.g, toInt, toString)
. or as a custom class followed by method name: e.g. 'c(MyFormatterClass).format'.
Example formatting cf:qualifier1 and cf:qualifier2 both as Integers:
hbase> scan 't1', {COLUMNS => ['cf:qualifier1:toInt',
'cf:qualifier2:c(org.apache.hadoop.hbase.util.Bytes).toInt'] }
Note that you can specify a FORMATTER by column only (cf:qualifier). You cannot
specify a FORMATTER for all columns of a column family.
Scan can also be used directly from a table, by first getting a reference to a
table, like such:
hbase> t = get_table 't'
hbase> t.scan
Note in the above situation, you can still provide all the filtering, columns,
options, etc as described above.
is_disabled
1)这个命令是用来查看表是否被禁用。它的语法如下:
hbase> is_disabled 'table name'
下面的例子验证表名为emp是否被禁用。如果禁用,它会返回true,如果没有,它会返回false。
hbase(main)::> is_disabled 'emp' true row(s) in 0.0440 seconds
从第二行中我们可以看出,这张emp表确实已经被禁用了。
2)disable_all
此命令用于禁用所有匹配给定正则表达式的表。disable_all命令的语法如下:
hbase> disable_all 'r.*'
假设有5个表在hbase,即raja, rajani, rajendra, rajesh 和 raju。下面的代码将禁用所有以 raj 开始的表。
hbase(main)::> disable_all 'raj.*' raja rajani rajendra rajesh raju Disable the above tables (y/n)? y tables successfully disabled
启用表
启用表
命令格式:
enable 'table_name'
执行命令:
hbase(main)::> enable 'emp' row(s) in 1.3610 seconds
验证表是不是已经被启用了
启用表之后,扫描。如果能看到的模式,那么证明表已成功启用:
hbase(main)::> scan 'emp' ROW COLUMN+CELL row(s) in 0.0700 seconds
is_enabled
此命令用于查找表是否被启用。它的语法如下:
hbase> is_enabled 'table name'
下面的代码验证表emp是否启用。如果启用,它将返回true,如果没有,它会返回false。
hbase(main)::> is_enabled 'emp' true row(s) in 0.0130 seconds
hbase的表描述和修改
表描述
命令格式:
describe 'table_name'
下面给出的是对emp表的 describe 命令的输出:
hbase(main)::> describe 'emp'
Table emp is ENABLED
emp
COLUMN FAMILIES DESCRIPTION
{NAME => ', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DA
TA_BLOCK_ENCODING => ', BLOCKCACHE => 'true', BLOCKSI
ZE => '}
{NAME => ', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE'
, DATA_BLOCK_ENCODING => ', BLOCKCACHE => 'true', BLO
CKSIZE => '}
row(s) in 0.0430 seconds
表修改
alter用于更改现有表的命令。使用此命令可以更改列族的单元,设定最大数量和删除表范围运算符,并从表中删除列家族。更改列族单元格的最大数目
1)下面给出的语法来改变列家族单元的最大数目。
hbase> alter
在下面的例子中,单元的最大数目设置为5。
hbase(main)::> alter Updating all regions with the new schema... / regions updated. / regions updated. Done. row(s) in 2.3050 seconds
2)表范围运算符
使用alter,可以设置和删除表范围,运算符,如MAX_FILESIZE,READONLY,MEMSTORE_FLUSHSIZE,DEFERRED_LOG_FLUSH等。
设置只读
下面给出的是语法,是用以设置表为只读。
命令格式: hbase>alter 't1', READONLY(option)
在下面的例子中,我们已经设置表emp为只读。
hbase(main)::> alter 'emp', READONLY Updating all regions with the new schema... / regions updated. / regions updated. Done. row(s) in 2.2140 seconds
3)删除表范围运算符
也可以删除表范围运算。下面给出的是语法,从emp表中删除“MAX_FILESIZE”。
hbase> alter 't1', METHOD => 'table_att_unset', NAME => 'MAX_FILESIZE'
4)删除列族
使用alter,也可以删除列族。下面给出的是使用alter删除列族的语法。
hbase> alter ‘ table name ’, ‘delete’ => ‘ column family ’
下面给出的是一个例子,从“emp”表中删除列族。
假设在hbase中有一个employee表。它包含以下数据:
hbase(main)::> scan 'employee'
ROW COLUMN+CELL
row1 column=personal:city, timestamp=, value=hyderabad
row1 column=personal:name, timestamp=, value=raju
row1 column=professional:designation, timestamp=, value=manager
row1 column=professional:salary, timestamp=, value=
row(s) in 0.0160 seconds
现在使用alter命令删除指定的 professional 列族。
hbase(main)::> alter 'employee','delete'=>'professional' Updating all regions with the new schema... / regions updated. / regions updated. Done. row(s) in 2.2380 seconds
现在验证该表中变更后的数据。观察列族“professional”也没有了,因为前面已经被删除了。
hbase(main)::> scan 'employee' ROW COLUMN+CELL row1 column=personal:city, timestamp=, value=hyderabad row1 column=personal:name, timestamp=, value=raju row(s) in 0.0830 seconds
删除表
drop命令可以删除表。在删除一个表之前必须先将其禁用。
hbase(main)::> disable 'emp' row(s) in 1.4580 seconds hbase(main)::> drop 'emp' row(s) in 0.3060 seconds
使用exists 命令验证表是否被删除。
hbase(main)::> exists 'emp' Table emp does not exist row(s) in 0.0730 seconds
drop_all
这个命令是用来在给出删除匹配“regex”表。它的语法如下:
hbase> drop_all 't.*'
注意:要删除表,则必须先将其禁用。
示例
假设有一些表的名称为raja, rajani, rajendra, rajesh, 和 raju。
hbase(main)::> list TABLE raja rajani rajendra rajesh raju row(s) in 0.0270 seconds
所有这些表以字母raj开始。首先使用disable_all命令禁用所有这些表如下所示:
hbase(main)::> disable_all 'raj.*' raja rajani rajendra rajesh raju Disable the above tables (y/n)? y tables successfully disabled
现在,可以使用 drop_all 命令删除它们,如下所示:
hbase(main)::> drop_all 'raj.*' raja rajani rajendra rajesh raju Drop the above tables (y/n)? y tables successfully dropped
exit
可以通过键入exit命令退出shell。
hbase(main)::> exit
停止hbase
要停止hbase,浏览进入到hbase主文件夹,然后键入以下命令。
./bin/stop-hbase.sh
hbase的DML相关的操作
本章将介绍如何在hbase表中创建的数据。要在hbase表中创建的数据,可以下面的命令和方法:
put 命令:
add() - Put类的方法
put() - HTable 类的方法
作为一个例子,我们将在hbase中创建下表:
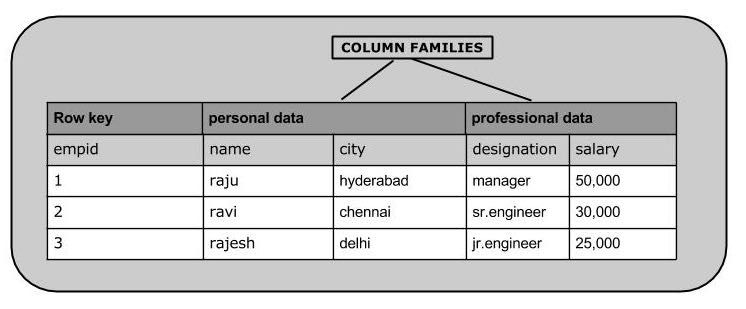
使用put命令,可以插入行到一个表。它的语法如下:
put '<table name>','row1','<colfamily:colname>','<value>'
hbase创建数据
首先我们按照上图的要求将第一行数据插入到表emp中:
hbase(main)::> put ','personal data:name','raju' row(s) in 0.0210 seconds hbase(main)::> put ','personal data:city','hyderabad' row(s) in 0.0140 seconds hbase(main)::> put ','professional data:designation','manager' row(s) in 0.0120 seconds hbase(main)::> put ' row(s) in 0.0090 seconds
同样的方式将第二行,第三行插入到表中,此时进行扫描就会发现数据已经插入了:
hbase(main)::> scan 'emp'
ROW COLUMN+CELL
column=personal data:city, timestamp=, value=hyderabad
column=personal data:name, timestamp=, value=raju
column=professional data:designation, timestamp=, value=manager
column=professional data:salary, timestamp=, value=
row(s) in 0.5880 seconds
当然了,笔者比较懒,只是插入了一行数据...
hbase修改数据
可以使用put命令更新现有的单元格值。按照下面的语法,并注明新值,如下所示:
put 'table name','row ','Column family:column name','new value'
新给定值替换现有的值,并更新该行。
实例:
通过扫描我们可以发现我们刚刚已经添加了一行数据:
hbase(main)::> scan 'emp'
ROW COLUMN+CELL
column=personal data:city, timestamp=, value=hyderabad
column=personal data:name, timestamp=, value=raju
column=professional data:designation, timestamp=, value=manager
column=professional data:salary, timestamp=, value=
row(s) in 0.5880 seconds
现在我们的任务就是将上面的city改成'NewYork':
hbase(main)::> put ','personal data:city','New York' row(s) in 0.1710 seconds
验证修改:
hbase(main)::> scan 'emp'
ROW COLUMN+CELL
column=personal data:city, timestamp=, value=NewYork
column=personal data:name, timestamp=, value=raju
column=professional data:designation, timestamp=, value=manager
column=professional data:salary, timestamp=, value=
row(s) in 0.0470 seconds
毫无疑问我们已经将数据修改了。
hbase获取数据
get命令和HTable类的get()方法用于从hbase表中读取数据。使用 get 命令,可以同时获取一行数据。它的语法如下:
get '<table name>','row number'
读取整行的数据
hbase(main)::> get ' COLUMN CELL personal data:city timestamp=, value=NewYork personal data:name timestamp=, value=raju professional data:designation timestamp=, value=manager professional data:salary timestamp=, value= row(s) in 0.0580 seconds
读取指定列的数据
命令格式:
hbase>get 'table name', 'rowid', {COLUMN => 'column family:column name'}
读取city那一行的数据:
hbase(main)::> get ',{COLUMN=>'personal data:city'}
COLUMN CELL
personal data:city timestamp=, value=NewYork
row(s) in 0.0250 seconds
hbase删除数据
从表中删除指定的单元格
使用 delete 命令,可以在一个表中删除特定单元格。 delete 命令的语法如下:
delete '<table name>', '<row>', '<column name >', <time stamp>
下面是一个删除特定单元格和例子。在这里,我们删除city:
hbase(main)::> delete row(s) in 0.0090 seconds
笔者发现了一个问题,那就是<time stamp>这个参数加上去和没有加上去的效果,都能够删除指定的单元格,那为什么要加呢?是不是有什么特定的作用?
从表中删除所有的单元格
使用“deleteall”命令,可以删除一行中所有单元格。下面给出是 deleteall 命令的语法:
deleteall '<table name>', '<row>'
下面是删除第一行的例子:
hbase(main)::> deleteall ' row(s) in 0.0120 seconds
下面是验证删除所有:
hbase(main)::> scan 'emp' ROW COLUMN+CELL row(s) in 0.0160 seconds
发现笔者插入的一条数据都已经被删除了...
hbase的计数和截断
hbase的计数
可以使用count命令计算表的行数量。它的语法如下:
count '<table name>'
当然了,笔者上面比较懒,只是插入了一条数据,后来又将之删除了,所以只能够重新插入一下了,此处略去....
truncate
此命令将禁止删除并重新创建一个表。truncate 的语法如下:
hbase> truncate 'table name'
下面给出是 truncate 命令的例子。在这里,我们已经截断了emp表:
hbase(main)::> truncate 'emp' Truncating 'emp' table (it may take a while): - Disabling table... - Truncating table... row(s) in 4.5990 seconds
截断表之后,我们使用scan命令来验证会得到表的行数为0:
hbase(main)::> scan 'emp' ROW COLUMN+CELL row(s) in 0.1500 seconds
最新文章
- Eclipse swt开发环境搭建
- HDU 1003 maxsum
- c++ is_space函数
- 第十讲(LINQ)
- 微小企业中Sqlserver2000服务器的日常备份与恢复
- 防止SQL注入的,网站安全的一些常用解决方案
- mybatis xml 中的特殊符转义字符号和模糊查询
- 安装rlwrap错误的问题解决方法
- X86汇编语言中的registers相关
- 图像二值化----otsu(最大类间方差法、大津算法)
- Android:Xml(读取与存储)
- iOS开发-分页栏和选取器的使用
- Android 开发笔记___EditText__文本编辑框
- 模板设计在tomcat中的应用
- 装B命令行,常用Windows命令
- 从零开始学安全(二十一)●PHPSPL异常
- yarn如何全局安装命令以及和环境变量的关系
- bash: cannot create temp file for here-document: Read-only file system
- 如何创建和还原SQL Server 2000数据库?
- github使用心得和链接