MapReduce-WordCount
2024-10-18 23:35:58
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>hadoop</groupId>
<artifactId>root</artifactId>
<version>1.0-SNAPSHOT</version> <dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.9.2</version>
</dependency>
</dependencies> <repositories>
<repository>
<id>alimaven</id>
<name>aliyun maven</name>
<url>https://maven.aliyun.com/repository/central</url>
</repository>
</repositories> <build>
<plugins>
<!-- 指定jdk -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<encoding>UTF-8</encoding>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
Code
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.log4j.BasicConfigurator; import java.io.IOException; public class WordcountDriver { static {
try {
// 设置 HADOOP_HOME 环境变量
System.setProperty("hadoop.home.dir", "D:/DevelopTools/hadoop-2.9.2/");
// 日志初始化
BasicConfigurator.configure();
// 加载库文件
System.load("D:/DevelopTools/hadoop-2.9.2/bin/hadoop.dll");
// System.out.println(System.getProperty("java.library.path"));
// System.loadLibrary("hadoop.dll");
} catch (UnsatisfiedLinkError e) {
System.err.println("Native code library failed to load.\n" + e);
System.exit(1);
}
} public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
// 获取Job对象
Job job = Job.getInstance(conf);
// 设置 jar 存储位置
job.setJarByClass(WordcountDriver.class);
// 关联 Map 和 Reduce 类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
// 设置 Mapper 阶段输出数据的 key 和 value 类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置最终数据输出(不一定是 Mapper 的输出)的 key 和 value 类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 手动设置输入路径和输出路径,注意输出路径不能为已存在的文件夹
args = new String[]{"D://tmp/123.txt", "D://tmp/456/"};
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交job
// job.submit();
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
} // Map 阶段
// 前两个参数为输入数据 k-v 的类型
// 后两个参数为输出数据 k-v 的类型
class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { Text k = new Text();
IntWritable v = new IntWritable(1); // 多少行数据执行多少次 Map
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 获取一行
String line = value.toString();
// 以空格分割
String[] words = line.split(" ");
// 循环写出,k 为单词,v 为 1
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
} // Reducer 阶段
// 前两个参数为输入数据的 k-v 类型,即 Map 阶段输出数据的 k-v类型
// 后两个参数为输出数据的 k-v 类型
class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { IntWritable v = new IntWritable(); @Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
// 累加求和,把相同单词的 v 值相加
for (IntWritable value : values) {
sum += value.get();
}
v.set(sum);
context.write(key, v);
}
}
本地运行
input(123.txt)
aa aa bb aa xx xx cc cc
11 22 55 qs dd ds ds ds
ww ee rr tt yy ff gg hh
12 ads aa ss xx zz cc qq
we 12 23 sd fc gb gb dd
212as asd 212as ads we
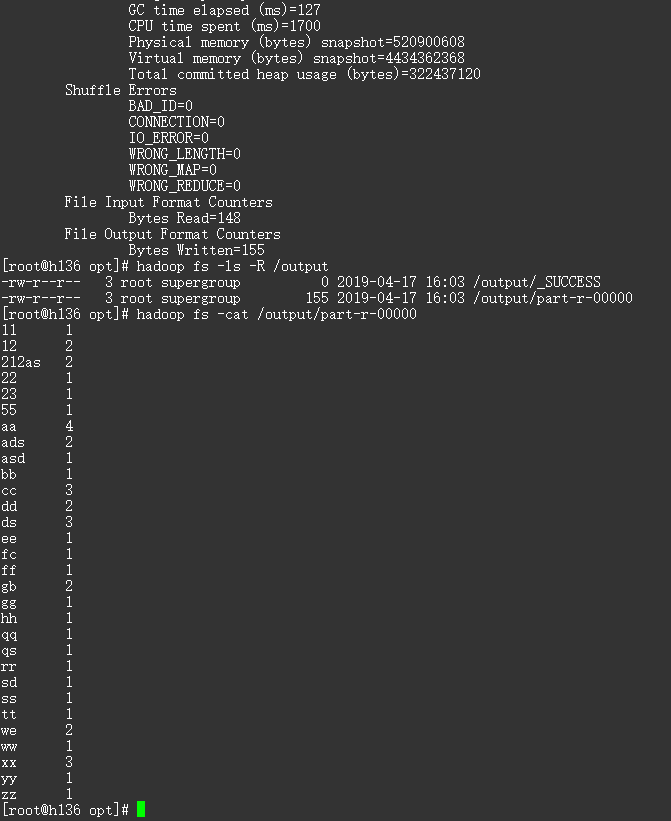
output(part-r-00000)
11 1
12 2
212as 2
22 1
23 1
55 1
aa 4
ads 2
asd 1
bb 1
cc 3
dd 2
ds 3
ee 1
fc 1
ff 1
gb 2
gg 1
hh 1
qq 1
qs 1
rr 1
sd 1
ss 1
tt 1
we 2
ww 1
xx 3
yy 1
zz 1
打包在集群上运行
使用 maven-assembly-plugin 打包,使用方法:http://maven.apache.org/components/plugins/maven-assembly-plugin/usage.html
在 pom 中添加打包插件
<!-- 打包 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.1</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<!-- 启动入口 -->
<mainClass>com.mapreduce.wordcount.WordcountDriver</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
删除原来写死的输入输出路径和环境设置,注释掉如下几行代码
System.setProperty("hadoop.home.dir", "D:/DevelopTools/hadoop-2.9.2/");
System.load("D:/DevelopTools/hadoop-2.9.2/bin/hadoop.dll");
args = new String[]{"D://tmp/123.txt", "D://tmp/456/"};
在项目根目录执行打包命令 mvn clean install,或直接点击 install
执行完后会生成两个文件
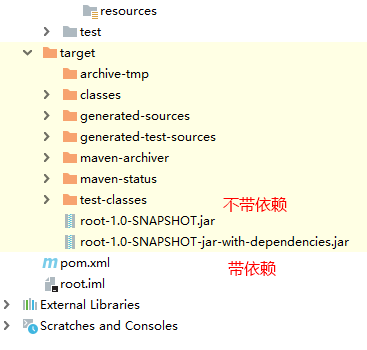
由于集群上已有环境,选择不带依赖 jar 包的即可,拷贝到集群执行
# 上传输入文件至 hdfs
hadoop fs -put 123.txt / # 运行
hadoop jar root-1.0-SNAPSHOT.jar com.mapreduce.wordcount.WordcountDriver /123.txt /output/ # 查看生成文件
hadoop fs -ls -R /output # 查看结果
hadoop fs -cat /output/part-r-00000
最新文章
- 我认识的log4j开源日志
- hdoj 1272 小希的迷宫
- 利用ListView的基本方法实现效果
- velocity使用知识总结
- hdu1233
- XSD - <schema> 元素
- rsyslog 详解3
- HDU 1203 I NEED A OFFER! 01背包 概率运算预处理。
- arduino笔记
- Python基础__函数
- Log file location for Oracle E-Business Suite R12
- 【MyBatis】Mapper XML 文件
- 【XSY3048 】Polynominal 数学
- 18.24 Ubuntu修改静态IP
- Vue+min-width实现最大两栏布局
- Redis之主从复制
- python创建目录保存文件
- 借助强大的IDEA开发ide高效实现equals,hashcode以及toString方法
- unity3d抛物线的脚本
- playbook相关
热门文章
- while(~scanf(..))为什么可以这样写
- [bzoj2288][pojChallenge]生日礼物【贪心+堆+链表】
- [leetcode]Weekly Contest 68 (767. Reorganize String&&769. Max Chunks To Make Sorted&&768. Max Chunks To Make Sorted II)
- nginx.conf(centos7 1.14)主配置文件修改
- Jmeter工具之上传图片,上传音频文件接口
- nio再学习之通道channel
- 洛谷P4319 变化的道路
- Python三大web框架简单介绍
- (六)Oracle 的 oracle表查询关键字
- 第三十五篇-AppBarLayout的使用