python基础-----字符编码
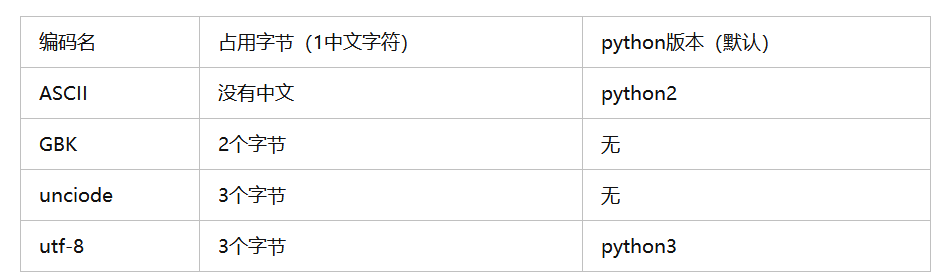
1、ASCII
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256-1,所以,ASCII码最多只能表示 255 个符号,python2.x解释器默认是ASCII编码。
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
二进制和数字转换:128 64 32 16 8 4 2 1 比如:2表示二进制 0000 0010
字符和数字转换 : 查看ASCII码表 比如: A字母 表示数字是65,二进制是0100 0001
2、Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定所有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,注:此处说的的是最少2个字节,可能更多,比如汉字就需要3个字节,python3.x解释器默认是Unicode编码。
3、UTF-8
是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行动态分类:ASCII码中的内容用1个字节保存、欧洲的字符用2个字节保存,汉字用3个字节保存...
所以,python2.x解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ASCII),如果是如下代码的话:
报错:ascii码无法表示中文
tomcat@node:~$ vim a.py
#!/usr/bin/env python
print "你好!世界"<br>
tomcat@node:~$ python a.py
File "a.py", line 2
SyntaxError: Non-ASCII character '\xe4' in file a.py on line 2, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
改正:应该显示的告诉python解释器,用什么编码来执行源代码,即:
tomcat@node:~$ vi a.py
#!/usr/bin/env python
# coding:utf-8
print "你好!世界" tomcat@node:~$ python a.py
你好!世界
注意:python3.x中字符集默认为UTF-8
python2.x还是ASCII所以需要设置#coding:utf-8
字符编码总结:
最新文章
- 自定义tabBar
- 关于标准C语言的预定义宏【转】
- XML文件操作(C#)
- STL笔记(3) copy()之绝版应用
- knowledge
- Part 2 How are the URL's mapped to Controller Action Methods?
- .NET连接MySQL数据库的方法实现
- [原创][下载]Senparc.Weixin.MP-微信公众平台SDK(C#) - 已支持微信6.x API
- 动软代码生成器 可用于生成Entity层,可更改模板 /codesmith 也可以
- C primer plus 读书笔记第十章
- iOS 输入时键盘处理问题
- 整合springboot(app后台框架搭建四)
- ORACLE 博客文章目录(2015
- Jquery之isPlainObject源码分析
- android 框架LoonAndroid,码农偷懒专用
- Python学习笔记 - 数据类型和变量
- 对话框--pop&dialog总结
- CSS样式学习-3、轮廓、伪类/元素、display-flex布局
- Faster rcnn代码理解(3)
- 阿里云实现putty私钥登录全过程