<强化学习>基于采样迭代优化agent
前面介绍了三种采样求均值的算法
——MC
——TD
——TD(lamda)
下面我们基于这几种方法来 迭代优化agent
传统的强化学习算法
||
ν
ν
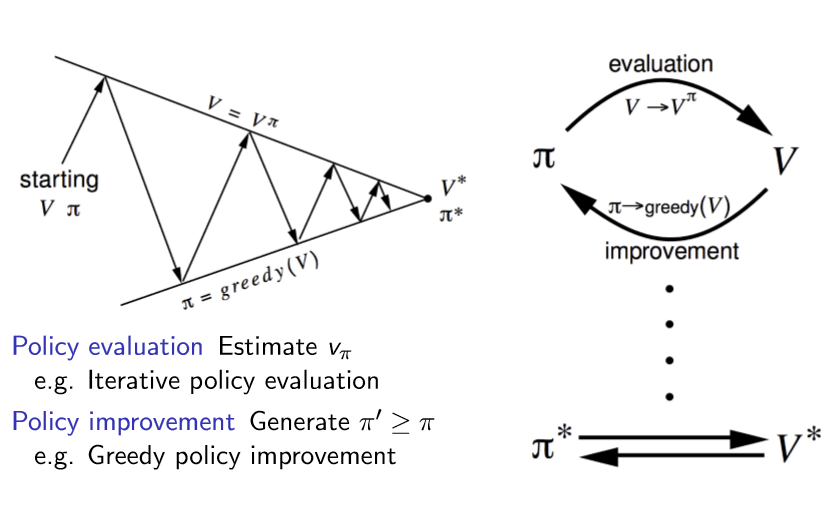
已经知道完整MDP——使用价值函数V(s)
没有给出完整MDP——使用价值函数Q(s,a)
可见我们的目标就是确定下来最优策略和最优价值函数
|
|——有完整MDP && 用DP解决复杂度较低
| ====》 使用贝尔曼方程和贝尔曼最优方程求解
|——没有完整MDP(ENV未知) or 知道MDP但是硬解MDP问题复杂度太高
| ====》 policy evaluation使用采样求均值的方法
| |—— ON-POLICY MC
| |—— ON-POLICY TD
| |____ OFF-POLICY TD
1 价值函数是V(s)还是Q(s,a)?
agent对外界好坏的认识是对什么的认识呢?是每一个状态s的好坏还是特定状态下采取特定行为(s,a)的好坏?
这取决于是什么样的问题背景。
有完整的MDP,知道从这个状态下采取某行为会有多大概率后继状态为某状态,那么我们的agent需要知道的是状态的好坏。如sutton书中的jack‘s car rental问题,方格问题等等,这些都是事先就明确知道状态行为转移概率矩阵的。丝毫没有“人工智能”的感觉。
没有完整的MDP,知道从这个状态下采取某行为会有多大概率后继状态为某状态,那么我们的agent需要知道的是状态行为对(s,a)的好坏。比如,围棋!我们下子之后,对手会把棋落哪是完全没法预测的,所以后继state是绝对不可预测,所以agent是不能用V(s)作为评价好坏的价值函数,所以agent应该在乎的是这个(s,a)好这个(s,a)不好,所以使用Q(s,a)作为价值函数。
2. ON-POLICY 和OFF-POLICY
on policy :基于策略A采样获取episode,并且被迭代优化的策略也是A
off policy :基于策略A采样获取episode,而被迭代优化的策略是B
3.为什么ε-greedy探索在on policyRL算法中行之有效?
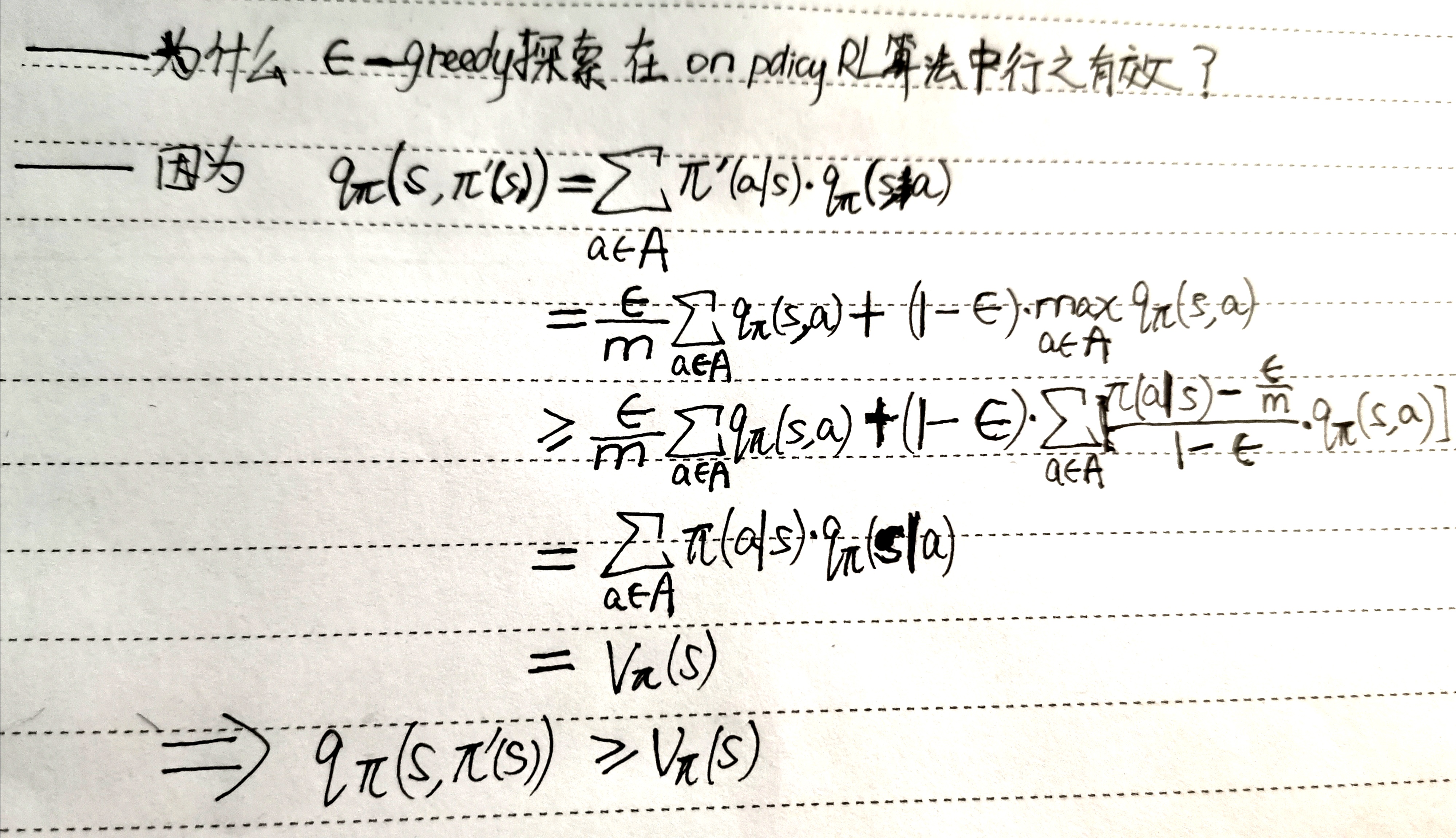
最新文章
- mfc ui库
- mybati之入门demo
- Javascript判断空对象
- 如何:对 Web 窗体使用路由
- 关于mwArray和一般数组的区别
- iOS小知识点大杂烩
- CentOS6.5+php5.3听云安装过程
- Android开发之使用URL訪问网络资源
- 初始化时查看combox的文本内容
- 空数组在以下三种遍历中均不可更改:forEach、map和for...in
- ArrayList和Vector区别及源码
- JPA中自定义的插入、更新、删除方法为什么要添加@Modifying注解和@Transactional注解?
- Codeforces Beta Round #94 (Div. 1 Only)B. String sam
- dellR720服务器设置光盘引导流程安装cenos7
- VS2017 配置freeglut3.0.0
- 样条之Akima光滑插值函数
- winform中RichTextBox在指定光标位置插入图片
- 【jquery基础】 jquery.manifest用法:通过后台查询and添加到默认项
- volley4--RequestQueue
- vSan中见证组件witness详解
热门文章
- 算法复杂度图示&JavaScript算法链接
- C. Swap Letters 01字符串最少交换几次相等
- 【剑指Offer面试编程题】题目1506:求1+2+3+...+n--九度OJ
- Primecoin服务端更新--操作流程
- HDU 5564:Clarke and digits 收获颇多的矩阵快速幂 + 前缀和
- 【PAT甲级】1008 Elevator (20 分)
- centos7一步一步搭建docker phpmyadmin 及nginx配置phpmyadmin非根目录重点讲解
- 什么是Device ID?
- selenium抓取淘宝数据报错:warnings.warn('Selenium support for PhantomJS has been deprecated, please use headless
- Python 基础之模块之math random time