【sklearn】Toy datasets上的分类/回归问题 (XGBoost实践)
分类问题
1. 手写数字识别问题
from sklearn.datasets import load_digits
digits = load_digits() # 加载手写字符识别数据集
X = digits.data # 特征值
y = digits.target # 目标值
X.shape, y.shape
((1797, 64), (1797,))
划分70%训练集,30%测试集,
from sklearn.model_selection import train_test_split
# 划分数据集,70% 训练数据和 30% 测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
((1257, 64), (540, 64), (1257,), (540,))
使用默认参数,
import xgboost as xgb
model_c = xgb.XGBClassifier()
model_c
XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, gamma=0, learning_rate=0.1,
max_delta_step=0, max_depth=3, min_child_weight=1, missing=None,
n_estimators=100, n_jobs=1, nthread=None,
objective='binary:logistic', random_state=0, reg_alpha=0,
reg_lambda=1, scale_pos_weight=1, seed=None, silent=None,
subsample=1, verbosity=1)
参数解释:
max_depth – 基学习器的最大树深度。
learning_rate – Boosting 学习率。
n_estimators – 决策树的数量。
gamma – 惩罚项系数,指定节点分裂所需的最小损失函数下降值。
booster – 指定提升算法:gbtree, gblinear or dart。
n_jobs – 指定多线程数量。
reg_alpha – L1 正则权重。
reg_lambda – L2 正则权重。
scale_pos_weight – 正负权重平衡。
random_state – 随机数种子。
model_c.fit(X_train, y_train) # 使用训练数据训练
model_c.score(X_test, y_test) # 使用测试数据计算准确度
0.9592592592592593
简单调参:
| max_depth | result |
|---|---|
| 1 | 0.912962962962963 |
| 2 | 0.9666666666666667 |
| 3 | 0.9592592592592593 |
| 4 | 0.9629629629629629 |
| 5 | 0.9537037037037037 |
| 6 | 0.9537037037037037 |
max_depth=2时效果最好。
| learning_rate | result |
|---|---|
| 0.05 | 0.9148148148148149 |
| 0.1 | 0.9666666666666667 |
| 0.15 | 0.9777777777777777 |
| 0.2 | 0.9814814814814815 |
| 0.25 | 0.9851851851851852 |
| 0.3 | 0.9796296296296296 |
| 0.35 | 0.9851851851851852 |
| 0.4 | 0.9851851851851852 |
learning_rate设置为0.25比较好。
| n_estimators | result |
|---|---|
| 50 | 0.9722222222222222 |
| 75 | 0.9777777777777777 |
| 100 | 0.9851851851851852 |
| 125 | 0.987037037037037 |
| 150 | 0.987037037037037 |
| 200 | 0.987037037037037 |
n_estimators设置为125比较好。
经过调参,准确率从95.9%提高到了98.7%。
from matplotlib import pyplot as plt
from matplotlib.pylab import rcParams
%matplotlib inline
# 设置图像大小
rcParams['figure.figsize'] = [50, 10]
xgb.plot_tree(model_c, num_trees=1)
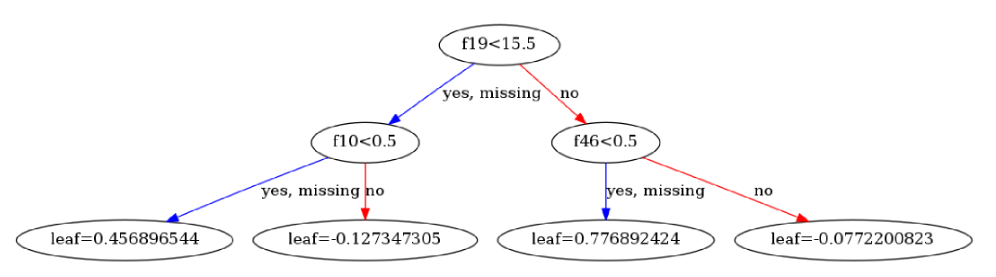
回归问题
1. 波士顿房价预测问题
from sklearn.datasets import load_boston
boston = load_boston()
X = boston.data # 特征值
y = boston.target # 目标值
# 划分数据集,80% 训练数据和 20% 测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
((404, 13), (102, 13), (404,), (102,))
默认参数:
model_r = xgb.XGBRegressor()
model_r
XGBRegressor(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, gamma=0,
importance_type='gain', learning_rate=0.1, max_delta_step=0,
max_depth=3, min_child_weight=1, missing=None, n_estimators=100,
n_jobs=1, nthread=None, objective='reg:linear', random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=None, subsample=1, verbosity=1)
model_r.fit(X_train, y_train) # 使用训练数据训练
model_r.score(X_test, y_test) # 使用测试数据计算 R^2 评估指标
0.811524182952107
参考资料
scikit-learn toy datasets doc.
最新文章
- .NET 基础一步步一幕幕[面向对象前言]
- 基于MVC4+EasyUI的Web开发框架经验总结(10)--在Web界面上实现数据的导入和导出
- 纪念逝去的岁月——C/C++字符串反转
- 【转】SQL常用的语句和函数
- IOI1998 hdu1828 poj1177 Picture
- VS2010编译、调用Lua程序
- shell中命令的执行流程
- Ubuntu13.04使用Mesa
- javascript字符串属性及常用方法总结
- Unix代码段和数据段
- linux文件删除原理
- VS2015右键集成TortoiseGit
- ajax请求封装的公共方法
- <Java><Multi-thread><Lock interface>
- android检测手机是否安装某个app
- 让HTML5来为你定位(转)
- 【ActiveMQ】Spring Jms集成ActiveMQ学习记录
- Cairo编程
- IOS开发常见第三方总结
- Jenkins02:Jenkins+maven+svn集成