简单了解node stream
Almost all Node.js applications, no matter how simple, use streams in some manner.
开篇先吓吓自己。画画图,分析分析代码加深自己的理解。
简单了解node stream
- stream基本概念
- Readable - 可读取数据的流
- Writable - 可写入数据的流
- 总结
1.stream基本概念
1.1什么是 stream
1. 在编写代码时,我们应该有一些方法将程序像连接水管一样连接起来 -- 当我们需要获取一些数据时,可以去通过"拧"其他的部分来达到目的。这也应该是IO应有的方式。 -- Doug McIlroy. October 11, 1964
结合到node中
stream 就像是一个抽象的模型(有点像水管),能有序的传输数据(有点像水),需要时就拧开水管取点用,还可以控制大小。
- Writable - 可写入数据的流(例如 fs.createWriteStream())。
- Readable - 可读取数据的流(例如 fs.createReadStream())。
- Duplex - 可读又可写的流(例如 net.Socket)。
- Transform - 在读写过程中可以修改或转换数据的 Duplex 流(例如 zlib.createDeflate())。
2.Readable-可读取数据的流
2.1 简单描述Readable 可读取数据流
可读流是对提供数据的来源的一种抽象。就像水管传递水资源供我们消费使用一样。
可读流有两种模式:流动模式(flowing)或暂停模式(paused)
- 流动模式flowing,数据自动从底层系统读取,并通过EventEmitter 接口的‘data’事件尽可能快地被提供给应用程序。
- 暂停模式paused, 数据必须显示通过调用stream.read()读取数据。
Stream 实例的 _readableState.flow(_readableState 是内部用来存储状态数据的对象) 有三个状态:
- _readableState.flow = null,暂时没有消费者过来(初始状态,没有确定模式)
- _readableState.flow = false,
- _readableState.flow = true,
2.2Readable 可读取数据流 flowing 模式
举个例子: flowing 模式,一旦绑定监听器到 'data' 事件时,流会转换到流动模式_readableState.flow = true
const { Readable } = require('stream');
class myReadable extends Readable {
constructor(options,sources) {
super(options);
this.sources = Buffer.from(sources);
this.pos = 0;
}
// 继承了Readable 的类必须实现 _read() 私有方法,被内部 Readable类的方法调用
// 当_read() 被调用时,如果从资源读取到数据,则需要开始使用 this.push(dataChunk) 推送数据到读取队列。
// _read() 应该持续从资源读取数据并推送数据,直到push(null)
_read(size) {
if (this.pos < this.sources.length) {
if(this.pos + size >= this.sources.length ) {
size = this.sources.length - this.pos
}
this.push(this.sources.slice(this.pos, this.pos + size));
this.pos = this.pos + size;
} else {
this.push(null);
}
}
}
let rs = new myReadable({
highWaterMark: 6
},"我是罗小布,我是某个地方来的水资源")
let waterCup = []
// 绑定监听器到 'data' 事件时,流会转换到流动模式。
// 当流将数据块传送给消费者后触发。
rs.on('data',(chunk)=>{
console.log(chunk); // chunk 是一个 buffer
waterCup.push(chunk)
})
rs.on('end',()=>{
console.log('读取消耗完毕');
console.log(Buffer.concat(waterCup).toString())
})
从上述代码开启调试:
大概的画了一下flowing模式的代码执行图:(这个图真心不好看,建议看后面的那个。这个不是流程图)

_read() 函数里面push 是同步操作会先将数据存储在this.buffer (this.buffe = new bufferList(),bufferList是内部实现的数据结构)变量中,然后再从this.buffer 变量中取出,emit('data',chunk) 消费掉。
function flow(stream) { // 消耗缓存操作
const state = stream._readableState;
debug('flow', state.flowing);
while (state.flowing && stream.read() !== null);
}
_read() 函数里面push 是异步,一旦异步操作中调用了push方法,且有数据,无缓存队列,此时会直接emit('data',chunk) 消费掉,然后调用stream.read(0)。
stream.read(0)调用代码如下:
function maybeReadMore_(stream, state) {
// - 缓冲区中没有数据,并且流处于流模式。 在这种模式下,下面的循环负责确保调用read()。
// 只执行一次就跳出 因为 len === state.length
while (!state.reading && !state.ended &&
(state.length < state.highWaterMark ||
(state.flowing && state.length === 0))) {
const len = state.length;
debug('maybeReadMore read 0');
stream.read(0);
if (len === state.length)
// Didn't get any data, stop spinning.
break;
}
state.readingMore = false;
}
但是如果在读取数据的途中调用了stream.pause() 此时会停止消费数据,但不会停止生产数据,生产的数据会缓存起来,如果流的消费者没有调用stream.read或者stream.resume方法, 这些数据会始终存在于内部缓存队列中(this.buffe = new bufferList(),bufferList是内部实现的数据结构),直到被消费。
由上简化图形:
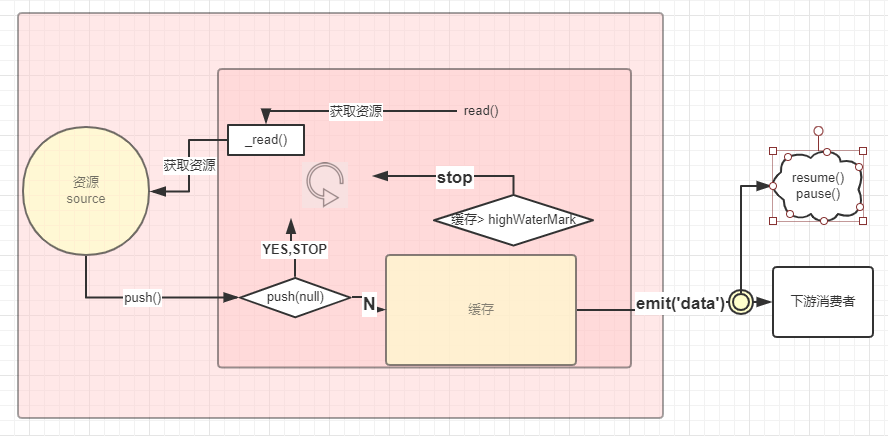
flowing 模式是自动获取底层资源不断流向消费者,是流动的。
2.3 .flowing 模式在 node 其它模块中的使用
已经封装好的模块更关注数据消费部分
http 模块
let http = require('http')
let server = http.createServer((req,res)=>{
var method = req.method;
if(method === 'POST') {
req.on('data',()=>{ // 接收数据
console.log(chunk)
})
req.on('end',()=>{
// 接收数据完成
console.log(chunk)
res.end('ok')
})
}
})
server.listen(8000)
fs 模块
let fs = require('fs')
let path = require('path')
let rs = fs.createReadStream(path.resolve(__dirname,'1.txt'),{
flags: 'r+',
highWaterMark: 3,
})
rs.on('data',(data)=>{ // 接收数据
console.log(data.toString())
})
rs.on('end',()=>{ // 接收数据完成
console.log('end')
})
rs.on('error',(error)=>{
console.log(error)
})
2.4.Readable 可读取数据流 paused模式
举个例子: paused模式,一旦绑定监听器到 'readable' 事件时,流会转换到暂停模式_readableState.flow = false
const { Readable } = require("stream");
class myReadable extends Readable {
constructor(options, sources) {
super(options);
this.sources = Buffer.from(sources);
console.log(this.sources)
this.pos = 0;
}
// 继承了Readable 的类必须实现 _read() 私有方法,被内部 Readable类的方法调用
// 当_read() 被调用时,如果从资源读取到数据,则需要开始使用 this.push(dataChunk) 推送数据到读取队列。
// _read() 应该持续从资源读取数据并推送数据,push(null)
_read(size) {
if (this.pos < this.sources.length) {
if(this.pos + size >= this.sources.length ) {
size = this.sources.length - this.pos
}
console.log('读取了:', this.sources.slice(this.pos, this.pos + size))
this.push(this.sources.slice(this.pos, this.pos + size));
this.pos = this.pos + size;
} else {
this.push(null);
}
}
}
let rs = new myReadable(
{
highWaterMark: 8
},
'我是罗小布,我是某个地方来的水资源'
);
let waterCup = [];
// 绑定监听器到 'readable' 事件时,流会转换到暂停模式。
// 'readable' 事件将在流中有数据有变化的时候触发
rs.on("readable", () => {
console.log('触发了readable')
while (null !== (chunk = rs.read(7))) {
console.log("消耗---",chunk.length);
waterCup.push(chunk)
}
});
rs.on("end", () => {
console.log("读取消耗完毕");
console.log(Buffer.concat(waterCup).toString());
});
从上述代码开启调试:
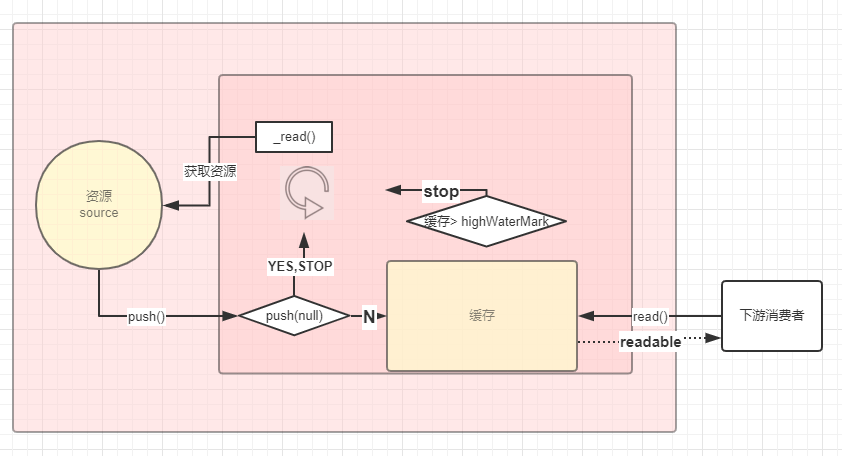
大概的画了一下paused模式的代码执行流程:

一旦开始监听readable事件,Readable内部就会调用read方法,获取数据到缓存中,并发出“readable”事件。
消费者监听了 readable 事件并不会消费数据,需要主动调用 .read(size) 函数获取数据,数据才会从缓存池取出。
若果读取的数据size > highWaterMark,会修改掉之前设置的highWaterMark,(会影响读取数据的大小)
如果获取的数据大于缓存池数据, .read(size) 会返回null, 底层会自动读取数据存储进缓存池并发出“readable”事件,通知消费。当消费者获得数据后,如果资源池缓存低于highWaterMark值,底层会读取并往缓存池输送数据,直到缓存高于highWaterMark值(数据足够的情况)
如果获取的数据小于缓存池数据,返回数据。接着判定消耗数据后,如果资源池缓存低于highWaterMark值,底层会读取并往缓存池输送数据,直到缓存高于highWaterMark值(数据足够的情况)
// If we're asking for more than the current hwm, then raise the hwm.
if (n > state.highWaterMark)
state.highWaterMark = computeNewHighWaterMark(n);
readable.push(chunk[, encoding]) 函数
readable.push() 方法用于将内容推入内部的 buffer。 它可以由 readable._read() 方法驱动。
这个方法的返回值可以控制读的速度,同Writable.write()控制写的速度。源码中返回true/false
// We can push more data if we are below the highWaterMark.
// Also, if we have no data yet, we can stand some more bytes.
// This is to work around cases where hwm=0, such as the repl.
return !state.ended &&
(state.length < state.highWaterMark || state.length === 0);
3.Writable-可写入数据的流
3.1 Writable的小例子
let { Writable } = require("stream");
class myWrite extends Writable {
constructor(dest, options) {
super(options);
}
// Writable 的类必须实现._write() 或._writev()私有方法,被内部 Writable类的方法调用
// _write 被调用时,将数据发送到底层资源。
// 无论是成功完成写入还是写入失败出现错误,都必须调用 callback
_write(chunk, encoding, callback) {
arr.push(chunk);
setTimeout(() => {
callback();
});
}
}
let arr = [];
let ws = new myWrite(arr, {
highWaterMark: 4
});
let text = "数据源哈哈哈";
let n = 0;
function write() {
let flag = true;
while (flag && text.length > n) {
console.log(text[n]);
flag = ws.write(text[n]);
n++;
}
}
ws.on("drain", () => {
console.log("排空了");
write();
});
write();
从上述代码开启调试:
大概的画了一下writable代码执行图:

调用 writable.write(chunk) ,如果此时正在进行底层写,此时的数据流就会进入队列池缓存起来,如果此时没有则会调用_write()将数据写入目的地。
可写流通过反复调用 writable.write(chunk) 方法将数据放到缓冲器。 当内部缓冲数据的总数小于 highWaterMark 指定的阈值时, 调用 writable.write() 将返回true。 一旦内部缓冲器的大小达到或超过 highWaterMark ,调用 writable.write() 将返回 false 。
此时最好停止调用writable.write(chunk),等待内部将缓存区清空 emit('drain') 时,再接着写入数据。
由上简化图形:
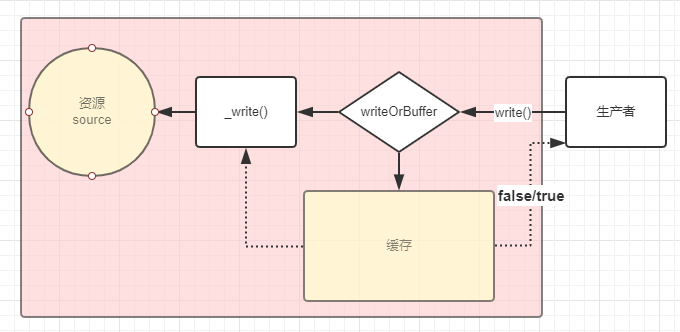
可以关注一下finish 方法
3.2 .stream writable 在node 其它模块中的使用
已经封装好的模块更关注数据生产部分
http 模块
let http = require('http')
let server = http.createServer((req,res)=>{
res.write('hello');
res.write('world');
res.end();
})
server.listen(8000)
fs模块:
let fs = require("fs");
let path = require("path");
let ws = fs.createWriteStream(path.resolve(__dirname, "./1.txt"), {
flags: "w",
encoding: "utf8",
start: 0,
highWaterMark: 3
});
let i = 9;
function write() {
let flag = true; // 表示是否能写入
while (flag && i >= 0) {
// 9 - 0
flag = ws.write(i-- + "");
}
}
ws.on("drain", () => {
write();
});
write();
4.总结
文章是对stream的简单了解,文中例子比较粗糙,理解不准确之处,还请教正。
node文档写的很详细,了解更多细节可以参考文档,以及node源码。
参考资料:
https://github.com/substack/stream-handbook
https://www.barretlee.com/blog/2017/06/06/dive-to-nodejs-at-stream-module/
https://nodejs.org/dist/latest-v13.x/docs/api/stream.html
https://github.com/nodejs/node/blob/master/lib/_stream_readable.js
https://github.com/nodejs/node/blob/master/lib/_stream_writable.js
最新文章
- mysql跟踪和日志
- Java利用aspose-words将word文档转换成pdf(破解 无水印)
- rds材资收集
- @font-face
- HTML5的Server-Sent Events (SSE)
- JavaScript进阶(四)
- Prince2学习有感:PRINCE2项目管理到底是什么?
- Hadoop生态系统图解
- css盒子边框样式
- git stash的用法
- 最近公共祖先问题(LCA)的几种实现方式
- jsp请求java返回pdf、excel与word
- laravel 多对多关联 attach detach sync
- K8S学习笔记之Kubernetes 部署策略详解
- Bootstrap3基础 text-right/left/center 设置标题右对齐、左对齐、居中
- 用virtualenv建立独立虚拟环境 批量导入模块信息
- 【工具相关】web-HTML/CSS/JS Prettify的使用
- Python selenium 滚动条 详解
- tomcat运行模式APR安装
- 第一次spring冲刺第3、4天