验证 .NET 4.6 的 SIMD 硬件加速支持的重要性
2024-09-20 01:57:33
SIMD 的意思是 Single Instruction Multiple Data。顾名思义,一个指令可以处理多个数据。
.NET Framework 4.6 推出的 Nuget 程序包 System.Numerics.Vectors 里面的 Vector`1 类型是有硬件加速功能的。这个硬件加速功能就是指即时编译的时候根据硬件环境选用一些 SIMD 的指令让程序运行更快。
这个硬件加速功能的威力可以用下面的方式得到验证。
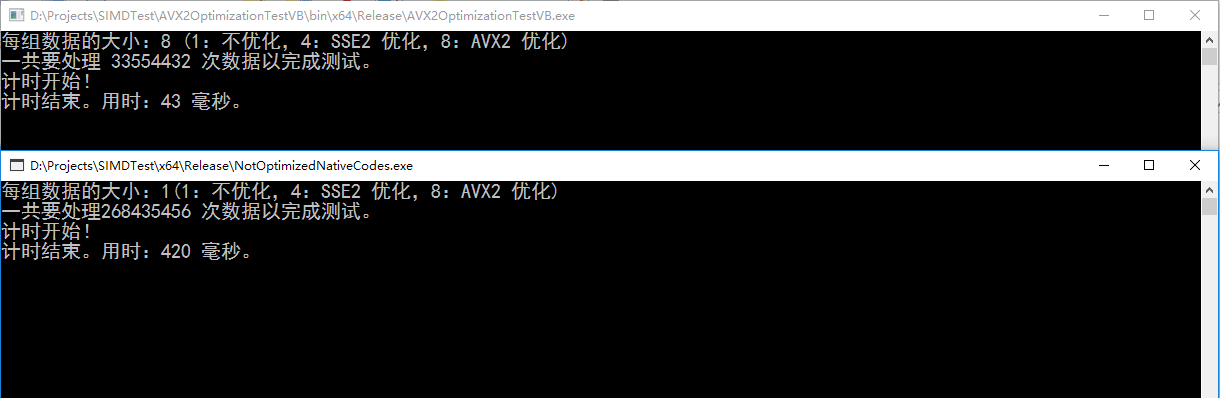
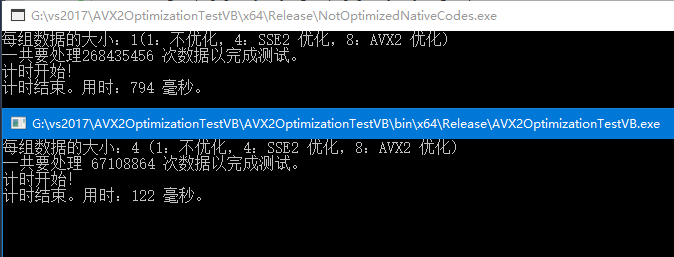
用单线程的程序重复 10000000H 个单精度浮点数的加法。加法的每一个输入都是引用类型,输出也必须获取值的引用。
VB 2017 程序:
动态获取当前硬件支持一组算多少个单精度浮点数的加法,然后分组计算。Release x64 编译,优化代码(反编译验证没有优化掉循环),取消整数溢出检查(为了跟 c# 执行时间一样)。
VB
Imports System.Numerics
Module Program
Sub Main()
Const TotalDataSize = &H1000_0000
Dim watch As New Stopwatch
Dim groupSize = Vector(Of Single).Count
Dim groupCount = TotalDataSize / groupSize
Console.WriteLine($"每组数据的大小:{groupSize} (1:不优化,4:SSE2 优化,8:AVX2 优化)
一共要处理 {groupCount} 次数据以完成测试。")
Console.WriteLine("计时开始!")
watch.Start()
Dim groupA(groupSize - ), groupB(groupSize - ) As Single
Dim vecA As New Vector(Of Single)(groupA), vecB As New Vector(Of Single)(groupB), vecResult As Vector(Of Single)
For i = To groupCount
vecResult = vecA + vecB
Next
watch.Stop()
Console.WriteLine($"计时结束。用时:{watch.ElapsedMilliseconds} 毫秒。")
Console.ReadKey()
End Sub
End Module
VC++ 2017程序:
用循环 0x10000000 次的 for 循环,Release x64 编译,禁止优化(开优化不管循环多少次都是 0 毫秒,肯定是把循环优化掉了)。
C++
#include "stdafx.h"
#include <iostream>
#include "NotOptimizedNativeCodes.h" const int TotalDataSize = 0x10000000; #pragma unmanaged void NativeTest()
{
float groupA[] = { }, groupB[] = { }, *groupResult;
for (size_t i = ; i < TotalDataSize; i++)
{
float result = groupA[] + groupB[];
groupResult = &result;
}
} #pragma managed using namespace System;
using namespace System::Diagnostics; int NotOptimizedNativeCodes::Program::main(array<System::String ^> ^args)
{
auto watch = gcnew Stopwatch();
std::cout << "每组数据的大小:" << << "(1:不优化,4:SSE2 优化,8:AVX2 优化)" << std::endl <<
"一共要处理" << TotalDataSize << " 次数据以完成测试。" << std::endl;
Console::WriteLine(L"计时开始!");
watch->Start();
NativeTest();
watch->Stop();
std::cout << "计时结束。用时:" << watch->ElapsedMilliseconds << " 毫秒。" << std::endl;
Console::ReadKey();
return ;
} int main(array<System::String ^> ^args)
{
NotOptimizedNativeCodes::Program::main(args);
}
执行结果(CPU 是 i5 6400,有 AVX2 指令集)
使用 i7 3632QM (没有 AVX2 但是有 SSE2)
最新文章
- asp.net中按钮回车事件(转自http://www.cnblogs.com/adinet/archive/2013/03/03/2941424.html)
- zend framework2 下载及安装
- 转载:C# this.invoke()作用 多线程操作UI 理解二
- Greenplum——升级的分布式PostgresSQL
- RAID对硬盘的要求及其相关
- protocol buffer的简单使用
- SSRS和SSAS是支持VB的
- BootstrapDialog点击空白处禁止关闭
- HTML5到底能给企业带来些什么?
- 51中的C语言数据类型
- Oracle 数据库基本操作——实用手册、表操作、事务操作、序列
- [转载]cin、cin.get()、cin.getline()、getline()、gets()函数的用法
- mysql相关日志汇总
- 1054: [HAOI2008]移动玩具
- 脚本自动化 ant
- Codeforces 803 G. Periodic RMQ Problem
- 时间序列数据库调研之InfluxDB
- Eclipse添加JDK,JRE切换
- MATLAB中floor、round、ceil、fix区别
- VS2015工具箱不出现ArcGIS Windows Forms怎么办?
热门文章
- POJ - 3190 Stall Reservations 贪心+自定义优先级的优先队列(求含不重叠子序列的多个序列最小值问题)
- 无法序列化会话状态。请注意,当会话状态模式为“StateServer”或“SQLServer”时,不允许使用无法序列化的对象或 MarshalByRef 对象。
- Telnet 命令格式
- Ogre 中使用OIS的两种模式
- 监控利器---Zabbix(一)
- [Xcode 实际操作]二、视图与手势-(6)给图像视图添加阴影效果
- 覆盖equals方法时请遵守通用约定
- shell chpasswd 命令 修改用户密码
- __slots__,__doc__,__module__,__class__.__call__
- 洛谷1005(dp)