Spark基本原理
仅作《Spark快速大数据分析》学习笔记
定义:Spark是一个用来实现 快速 而 通用 的集群计算平台;(通用的大数据处理引擎;)
改进了原Hadoop MapReduce处理模型,体现在三方面:
a. 速度;(内存计算)
b. 不仅支持批处理,还支持交互式查询(速度快的成果)、流式计算、机器学习、图计算等;(迭代算法)
c. 丰富的API和易用性;
Spark组件主要组成:
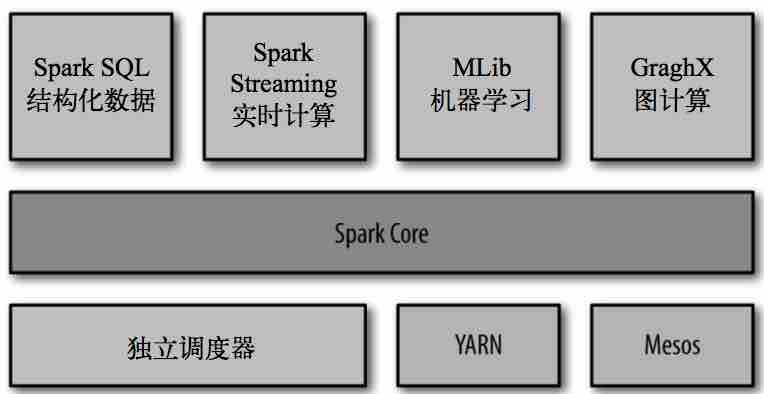
Spark Core:实现了Spark的核心功能,包含任务调度、内存管理、与存储系统交互、错误恢复等;定义了RDD API;
RDD:(resilient distributed dataset)弹性分布式数据集,表示分布在多个计算节点上可以平行操作的元素集合;
通过创建RDD来操作完成 统计计算,这些计算会自动地 在集群上并行进行。
Spark主要的编程抽象;
Spark SQL:Spark操作结构化数据的程序包;
Spark Streaming: Spark 提供的对实时数据进行流式计算的组件 ;
MLlib: 提供常见的机器学习(ML)功能的程序库 ;
GraphX: 是用来操作图(比如社交网络的朋友关系图)的程序库,可以进行并行的图计算;
Spark shell:和其他 shell 工具不一样的是,在其他 shell 工具中你只能使用单机的硬盘和内存来操作数据;
可用来与分布式存储在许多机器的内存或者硬盘上的数据进行交互,并且处理过程的分发由 Spark 自动控制完成;
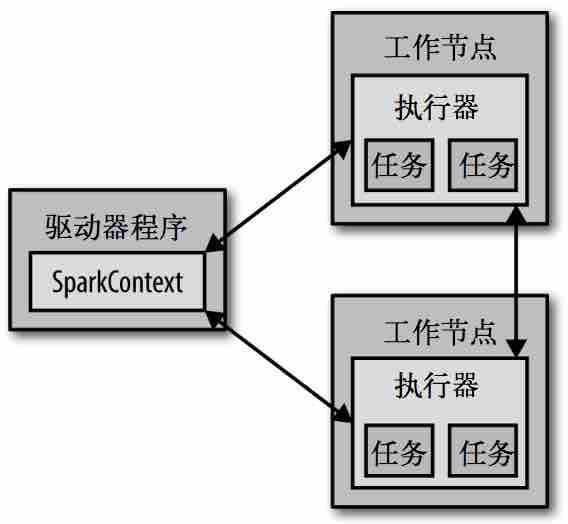
动作原理:
driver program
executor
每个 Spark 应用都由一个 驱动器程序(driver program) 来管理。
a. 驱动器程序包含应用的 main函数;
b. 并且定义了集群上的 分布式数据集;
c. 还对这些 分布式数据集应用了相关操作。
Shell环境下 驱动器程序就是 Spark shell 本身,可利用它输入想要运行的操作。
驱动器程序通过一个 SparkContext对象 来访问Spark,这个对象代表对计算集群的一个连接;slell启动时会自动创建一个SparkContext对象,变量名为sc;
//查看变量 sc
>>> sc
<pyspark.context.SparkContext object at 0x1025b8f90>
一旦有了SparkContext对象,就可以利用它创建RDD,如sc.textFile("/filename"),然后即可进行各种操作;
通常操作RDD的相关操作,驱动器程序一般要管理多个执行器(executor)节点;如count()操作,多个节点会统计文件不同的部分;
最新文章
- dom 节点篇 ---单体模式
- html5,格式的验证
- js动画之同时运动
- 核心动画 (CAAnimationGroup)
- python多线程监控指定目录
- Apache 常用伪静态配置
- Ubuntu进不入系统,一直停留在ubuntu图标画面(转)
- HashMap详解
- sql查询最大id
- gridview的高级使用
- ECMAScript 6 笔记(三)
- 团队作业8——第二次项目冲刺(Beta阶段) 5.19
- Django学习-5-模板渲染
- 解决tomcat端口被占用:Port 8005 required by Tomcat v7.0 Server at localhost is already in use
- yum安装的Nginx添加第三方模块支持tcp
- XX.exe 系统找不到指定文件
- 支持自定义协议的虚拟仪器【winform版】
- TcxGrid 复选框
- win8预装系统环境下安装win7问题以及双操作系统安装解决
- NASSA’s Robot
热门文章
- Redis常见配置redis.conf
- [USACO08DEC]Trick or Treat on the Farm (拓扑排序,DP)
- 用“道”的思想解决费用流问题---取/不取皆是取 (有下界->有上界) / ACdreamoj 1171
- Entity Farmework领域建模方式 3种编程方式
- [bzoj1187][HNOI2007]神奇游乐园_插头dp
- Hadoop学习(一)生态体系之简介
- Android Studio一些常用的快捷键
- 【Android开发—智能家居系列】(三):手机连接WIFI模块
- 王立平--Gallery:实现图片的左右滑动
- 通过Python实现自动填写调查问卷